MeshAvatar: Learning High-quality Triangular Human Avatars from Multi-view Videos

0

Sign in to get full access
Overview
• This paper introduces MeshAvatar, a system that can generate high-quality, realistic 3D human avatars from multi-view video inputs.
• The key innovation is a neural network-based approach that can reconstruct detailed, triangular-mesh human models, going beyond previous work on lower-quality representations like point clouds or implicit surfaces.
• The authors demonstrate that MeshAvatar can produce avatars that are both visually compelling and physically realistic, enabling applications in virtual reality, gaming, and beyond.
Plain English Explanation
MeshAvatar is a new technology that can create highly detailed, 3D digital humans from videos of people. Unlike previous methods that produced lower-quality 3D models, MeshAvatar can generate avatars with a realistic triangular mesh structure, capturing fine details like facial features and clothing.
The key innovation is a neural network model that can take in multiple camera views of a person and reconstruct a full 3D avatar. This allows the avatars to be highly realistic and suitable for a variety of applications, such as virtual reality experiences, video games, and digital entertainment.
The authors show that MeshAvatar can produce avatars that not only look visually striking, but also behave in a physically plausible way, with accurate movement and deformation. This is a significant advance over simpler 3D representations that lack these properties.
Technical Explanation
The MeshAvatar system takes as input multi-view video footage of a person and outputs a high-quality 3D triangular mesh model of that person's avatar. This goes beyond previous work that could only produce lower-fidelity point cloud or implicit surface representations.
The core of MeshAvatar is a neural network architecture that can effectively fuse information from multiple camera views to reconstruct a detailed 3D mesh. This includes encoders to process the input images, a differentiable rendering module to project the 3D model into 2D, and decoders to predict the final mesh geometry and texture.
Importantly, the authors also incorporate physical priors into the model, enabling the generated avatars to exhibit realistic deformation and motion. This is achieved through a novel integration of a physics-based "skin" layer on top of the core 3D mesh.
The authors validate MeshAvatar through extensive experiments, demonstrating state-of-the-art performance on benchmark datasets compared to prior 3D human modeling approaches like GomAvatar and GAVatar. They also show that the generated avatars can be effectively used for tasks like virtual try-on and animation.
Critical Analysis
While MeshAvatar represents a significant advance in human 3D modeling, the paper does acknowledge some limitations. For example, the current system requires multi-view video inputs, which may not always be available in practical scenarios. The authors suggest extending the approach to work with monocular inputs as an area for future research.
Additionally, the paper does not provide a detailed analysis of the computational efficiency of MeshAvatar. As the model needs to process multiple camera views and perform complex rendering and physics simulations, the inference time and resource requirements could be a practical concern for real-time applications.
Another potential issue is the reliance on extensive training data. The authors use a large dataset of 3D human scans to pre-train their model, which may limit the accessibility of the technique for researchers or developers without access to similar resources.
Overall, MeshAvatar is a promising step towards more realistic and physically plausible human avatars. However, further work is needed to address the practical limitations and broaden the applicability of the approach.
Conclusion
The MeshAvatar system introduces a novel neural network-based approach for generating high-quality, triangular mesh-based 3D human avatars from multi-view video inputs. By incorporating physical priors and leveraging detailed training data, the authors demonstrate the ability to create visually compelling and physically realistic digital humans.
This work represents a significant advancement in the field of 3D human modeling, with potential applications in virtual reality, gaming, and digital entertainment. The authors' focus on producing detailed, deformable mesh representations, rather than simpler point clouds or implicit surfaces, sets MeshAvatar apart from previous approaches and opens up new possibilities for more immersive and interactive digital experiences.
While the current system has some limitations, the core ideas and techniques presented in this paper lay the groundwork for further research and development in this exciting area of computer graphics and computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MeshAvatar: Learning High-quality Triangular Human Avatars from Multi-view Videos
Yushuo Chen, Zerong Zheng, Zhe Li, Chao Xu, Yebin Liu
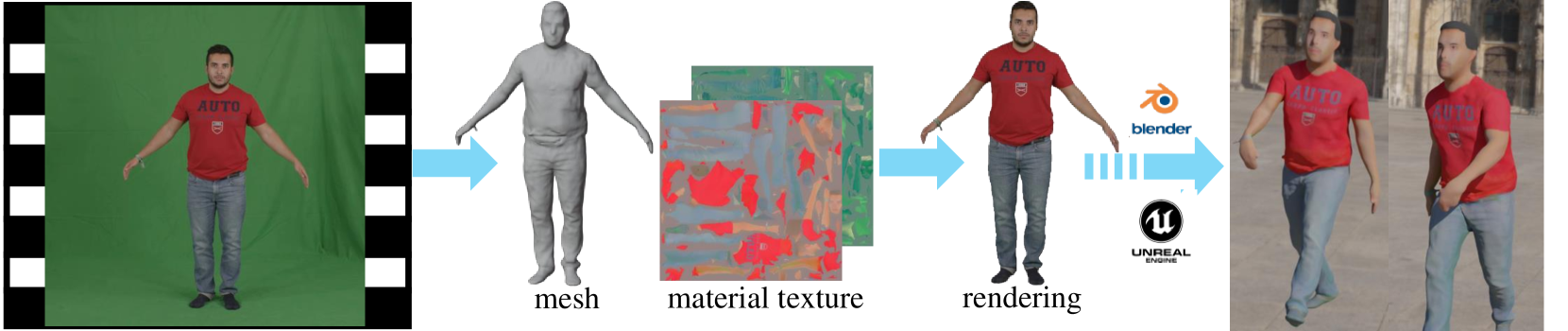
We present a novel pipeline for learning high-quality triangular human avatars from multi-view videos. Recent methods for avatar learning are typically based on neural radiance fields (NeRF), which is not compatible with traditional graphics pipeline and poses great challenges for operations like editing or synthesizing under different environments. To overcome these limitations, our method represents the avatar with an explicit triangular mesh extracted from an implicit SDF field, complemented by an implicit material field conditioned on given poses. Leveraging this triangular avatar representation, we incorporate physics-based rendering to accurately decompose geometry and texture. To enhance both the geometric and appearance details, we further employ a 2D UNet as the network backbone and introduce pseudo normal ground-truth as additional supervision. Experiments show that our method can learn triangular avatars with high-quality geometry reconstruction and plausible material decomposition, inherently supporting editing, manipulation or relighting operations.
Read more7/12/2024
0
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
Read more5/21/2024
⛏️
0
Animatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars
Yang Liu, Xiang Huang, Minghan Qin, Qinwei Lin, Haoqian Wang
Neural radiance fields are capable of reconstructing high-quality drivable human avatars but are expensive to train and render and not suitable for multi-human scenes with complex shadows. To reduce consumption, we propose Animatable 3D Gaussian, which learns human avatars from input images and poses. We extend 3D Gaussians to dynamic human scenes by modeling a set of skinned 3D Gaussians and a corresponding skeleton in canonical space and deforming 3D Gaussians to posed space according to the input poses. We introduce a multi-head hash encoder for pose-dependent shape and appearance and a time-dependent ambient occlusion module to achieve high-quality reconstructions in scenes containing complex motions and dynamic shadows. On both novel view synthesis and novel pose synthesis tasks, our method achieves higher reconstruction quality than InstantAvatar with less training time (1/60), less GPU memory (1/4), and faster rendering speed (7x). Our method can be easily extended to multi-human scenes and achieve comparable novel view synthesis results on a scene with ten people in only 25 seconds of training.
Read more7/30/2024

0
IntrinsicAvatar: Physically Based Inverse Rendering of Dynamic Humans from Monocular Videos via Explicit Ray Tracing
Shaofei Wang, Bov{z}idar Anti'c, Andreas Geiger, Siyu Tang
We present IntrinsicAvatar, a novel approach to recovering the intrinsic properties of clothed human avatars including geometry, albedo, material, and environment lighting from only monocular videos. Recent advancements in human-based neural rendering have enabled high-quality geometry and appearance reconstruction of clothed humans from just monocular videos. However, these methods bake intrinsic properties such as albedo, material, and environment lighting into a single entangled neural representation. On the other hand, only a handful of works tackle the problem of estimating geometry and disentangled appearance properties of clothed humans from monocular videos. They usually achieve limited quality and disentanglement due to approximations of secondary shading effects via learned MLPs. In this work, we propose to model secondary shading effects explicitly via Monte-Carlo ray tracing. We model the rendering process of clothed humans as a volumetric scattering process, and combine ray tracing with body articulation. Our approach can recover high-quality geometry, albedo, material, and lighting properties of clothed humans from a single monocular video, without requiring supervised pre-training using ground truth materials. Furthermore, since we explicitly model the volumetric scattering process and ray tracing, our model naturally generalizes to novel poses, enabling animation of the reconstructed avatar in novel lighting conditions.
Read more7/12/2024