IntrinsicAvatar: Physically Based Inverse Rendering of Dynamic Humans from Monocular Videos via Explicit Ray Tracing

0

Sign in to get full access
Overview
- This paper presents a method called "IntrinsicAvatar" for physically-based inverse rendering of dynamic human avatars from monocular videos.
- The approach uses explicit ray tracing to reconstruct 3D human models with detailed geometry, material properties, and motion from a single video input.
- The method aims to capture the intrinsic properties of human appearance and movement, enabling high-quality digital avatars that can be used for various applications.
Plain English Explanation
The researchers have developed a technique called "IntrinsicAvatar" that can create detailed 3D human models from a single video. This is done through a process called "inverse rendering," where the computer analyzes the video and reconstructs the 3D shape, materials, and motion of the person.
The key innovation is the use of "explicit ray tracing," which is a way of simulating how light interacts with the 3D scene. This allows the method to capture the intricate details of the human's appearance and movement, resulting in high-quality digital avatars.
These avatars could be used for a variety of applications, such as virtual reality, video games, animation, or visual effects. The method aims to capture the essential qualities of human appearance and movement in a way that can be faithfully reproduced digitally, opening up new possibilities for realistic human representation.
Technical Explanation
The "IntrinsicAvatar" method uses a novel inverse rendering approach to reconstruct detailed 3D human models from a single monocular video input. The key components of the technique include:
-
Geometric Reconstruction: The system first estimates the 3D shape of the human body using a parametric model and optimizes the shape parameters to fit the observed video data.
-
Material Estimation: The method then estimates the material properties of the human's skin, clothing, and other surfaces, including parameters like color, reflectivity, and roughness.
-
Motion Capture: The system tracks the human's movement over time, capturing the dynamic poses and deformations of the 3D model to match the observed motion in the video.
-
Explicit Ray Tracing: The core of the approach is the use of explicit ray tracing to simulate the interaction of light with the reconstructed 3D human model. This allows the method to accurately reproduce the subtle visual details and lighting effects observed in the input video.
The researchers validate the "IntrinsicAvatar" approach through extensive experiments, demonstrating its ability to faithfully reconstruct high-quality human avatars from monocular videos. The resulting models capture intricate geometric details, realistic material properties, and natural motion, paving the way for advanced applications in computer graphics and visualization.
Critical Analysis
The "IntrinsicAvatar" method represents an impressive advancement in the field of human reconstruction from monocular video inputs. The use of explicit ray tracing is a particularly novel and powerful technique, enabling the capture of intricate visual details that are often lost in more simplified rendering approaches.
However, the paper does acknowledge some limitations of the current system. For example, the method struggles to accurately reconstruct fine-grained details like facial expressions and hair, which are crucial for creating truly lifelike digital avatars. Additionally, the computational complexity of the ray tracing-based optimization could limit the practical deployment of the technique in real-time applications.
Further research could explore ways to address these limitations, such as by incorporating additional sensory inputs (e.g., depth cameras, multi-view videos) or leveraging advances in machine learning-based rendering techniques to improve efficiency. Exploring the potential biases and ethical implications of such highly realistic human avatars also warrants careful consideration.
Conclusion
The "IntrinsicAvatar" method presented in this paper represents a significant advancement in the field of human reconstruction from monocular video inputs. By using explicit ray tracing, the system can capture intricate details of human appearance and movement, enabling the creation of high-quality digital avatars.
These avatars have the potential to enhance a wide range of applications, from virtual reality and video games to animation and visual effects. As the technology continues to evolve, it will be important to address the remaining limitations and consider the ethical implications of such realistic human representation.
Overall, the "IntrinsicAvatar" approach is a promising step towards more accurate and immersive digital human models, with far-reaching implications for the future of computer graphics and visualization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IntrinsicAvatar: Physically Based Inverse Rendering of Dynamic Humans from Monocular Videos via Explicit Ray Tracing
Shaofei Wang, Bov{z}idar Anti'c, Andreas Geiger, Siyu Tang
We present IntrinsicAvatar, a novel approach to recovering the intrinsic properties of clothed human avatars including geometry, albedo, material, and environment lighting from only monocular videos. Recent advancements in human-based neural rendering have enabled high-quality geometry and appearance reconstruction of clothed humans from just monocular videos. However, these methods bake intrinsic properties such as albedo, material, and environment lighting into a single entangled neural representation. On the other hand, only a handful of works tackle the problem of estimating geometry and disentangled appearance properties of clothed humans from monocular videos. They usually achieve limited quality and disentanglement due to approximations of secondary shading effects via learned MLPs. In this work, we propose to model secondary shading effects explicitly via Monte-Carlo ray tracing. We model the rendering process of clothed humans as a volumetric scattering process, and combine ray tracing with body articulation. Our approach can recover high-quality geometry, albedo, material, and lighting properties of clothed humans from a single monocular video, without requiring supervised pre-training using ground truth materials. Furthermore, since we explicitly model the volumetric scattering process and ray tracing, our model naturally generalizes to novel poses, enabling animation of the reconstructed avatar in novel lighting conditions.
Read more7/12/2024

0
PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
Yang Zheng, Qingqing Zhao, Guandao Yang, Wang Yifan, Donglai Xiang, Florian Dubost, Dmitry Lagun, Thabo Beeler, Federico Tombari, Leonidas Guibas, Gordon Wetzstein
Modeling and rendering photorealistic avatars is of crucial importance in many applications. Existing methods that build a 3D avatar from visual observations, however, struggle to reconstruct clothed humans. We introduce PhysAvatar, a novel framework that combines inverse rendering with inverse physics to automatically estimate the shape and appearance of a human from multi-view video data along with the physical parameters of the fabric of their clothes. For this purpose, we adopt a mesh-aligned 4D Gaussian technique for spatio-temporal mesh tracking as well as a physically based inverse renderer to estimate the intrinsic material properties. PhysAvatar integrates a physics simulator to estimate the physical parameters of the garments using gradient-based optimization in a principled manner. These novel capabilities enable PhysAvatar to create high-quality novel-view renderings of avatars dressed in loose-fitting clothes under motions and lighting conditions not seen in the training data. This marks a significant advancement towards modeling photorealistic digital humans using physically based inverse rendering with physics in the loop. Our project website is at: https://qingqing-zhao.github.io/PhysAvatar
Read more4/10/2024
0
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
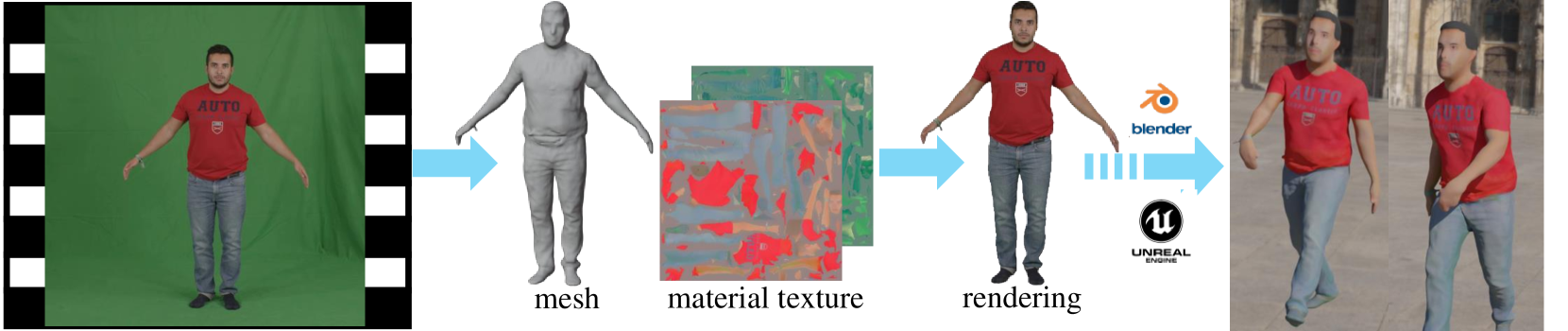
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
Read more5/21/2024

0
Surfel-based Gaussian Inverse Rendering for Fast and Relightable Dynamic Human Reconstruction from Monocular Video
Yiqun Zhao, Chenming Wu, Binbin Huang, Yihao Zhi, Chen Zhao, Jingdong Wang, Shenghua Gao
Efficient and accurate reconstruction of a relightable, dynamic clothed human avatar from a monocular video is crucial for the entertainment industry. This paper introduces the Surfel-based Gaussian Inverse Avatar (SGIA) method, which introduces efficient training and rendering for relightable dynamic human reconstruction. SGIA advances previous Gaussian Avatar methods by comprehensively modeling Physically-Based Rendering (PBR) properties for clothed human avatars, allowing for the manipulation of avatars into novel poses under diverse lighting conditions. Specifically, our approach integrates pre-integration and image-based lighting for fast light calculations that surpass the performance of existing implicit-based techniques. To address challenges related to material lighting disentanglement and accurate geometry reconstruction, we propose an innovative occlusion approximation strategy and a progressive training approach. Extensive experiments demonstrate that SGIA not only achieves highly accurate physical properties but also significantly enhances the realistic relighting of dynamic human avatars, providing a substantial speed advantage. We exhibit more results in our project page: https://GS-IA.github.io.
Read more7/24/2024