Meta Reasoning for Large Language Models

0

Sign in to get full access
Overview
- This paper explores the concept of "meta-reasoning" in the context of large language models (LLMs).
- The authors investigate how LLMs can be prompted to engage in higher-order reasoning about their own reasoning processes.
- The paper includes experiments on various reasoning tasks, such as meta-reasoning prompting, meta-reasoning benchmarks, and the ability of LLMs to reason about contrast and clinical scenarios.
- The paper also introduces a new benchmark called MARS to assess the metaphysical reasoning abilities of LLMs.
Plain English Explanation
The paper is about a concept called "meta-reasoning" and how it can be applied to large language models (LLMs). Meta-reasoning refers to the ability to think about your own thinking process. The researchers wanted to see if LLMs, which are powerful AI systems that can understand and generate human-like language, could be trained to engage in this higher-level reasoning.
To do this, the researchers conducted a series of experiments. They developed special prompts that would encourage the LLMs to reason about their own reasoning, rather than just providing a simple answer. For example, they might ask the model to explain its thought process for solving a problem or to compare its approach to a different way of solving the same problem.
The researchers also created new benchmarks, or standardized tests, to evaluate the meta-reasoning abilities of LLMs. One of these benchmarks, called MARS, focused on the models' ability to reason about abstract, philosophical concepts.
Overall, the paper suggests that LLMs can be trained to engage in meta-reasoning, which could have important implications for how we understand and interact with these powerful AI systems. By getting LLMs to think about their own thought processes, we may be able to gain deeper insights into how they work and how they can be improved.
Technical Explanation
The paper presents a series of experiments and benchmarks designed to explore the concept of "meta-reasoning" in the context of large language models (LLMs).
In the meta-reasoning prompting experiment, the researchers developed prompts that encouraged LLMs to engage in higher-order reasoning about their own reasoning processes. For example, they might ask the model to explain its thought process for solving a problem or to compare its approach to a different way of solving the same problem.
The meta-reasoning benchmark involved a set of tasks designed to test the ability of LLMs to reason about their own reasoning. This included evaluating the models' ability to identify logical fallacies, critique their own reasoning, and explain their reasoning process.
The researchers also investigated the ability of LLMs to reason about contrast and clinical scenarios, which are important for understanding how these models approach different types of reasoning tasks.
Finally, the paper introduces a new benchmark called MARS, which is designed to assess the metaphysical reasoning abilities of LLMs. This benchmark includes tasks that require the models to reason about abstract, philosophical concepts.
Overall, the paper presents a comprehensive investigation into the meta-reasoning capabilities of LLMs, with the goal of gaining a deeper understanding of how these models approach and engage in higher-order reasoning.
Critical Analysis
The paper presents a thoughtful and well-designed set of experiments and benchmarks for exploring the meta-reasoning capabilities of large language models (LLMs). The authors acknowledge that the field of meta-reasoning in LLMs is still in its early stages, and there are likely many open questions and areas for further research.
One potential limitation of the study is the relatively small scale of the experiments and benchmarks. While the authors have made a valuable contribution by introducing new approaches to testing meta-reasoning, it would be interesting to see how these methods scale to larger, more diverse datasets and model architectures.
Additionally, the paper does not address the potential biases or limitations that may be inherent in the language models themselves. As with any AI system, LLMs can reflect the biases and inconsistencies of the data they were trained on, which could impact their meta-reasoning abilities.
It would also be valuable to explore the implications of meta-reasoning in LLMs for real-world applications, such as in decision-making, scientific reasoning, or healthcare. The ability of these models to engage in higher-order reasoning could have significant practical applications, but the paper does not delve deeply into these potential use cases.
Overall, the paper represents an important step forward in the understanding of meta-reasoning in large language models. By continuing to explore these capabilities and their broader implications, researchers may be able to unlock new insights into the nature of intelligence, both artificial and human.
Conclusion
This paper presents a compelling exploration of the concept of "meta-reasoning" in the context of large language models (LLMs). Through a series of experiments and benchmarks, the researchers have demonstrated that LLMs can be prompted to engage in higher-order reasoning about their own reasoning processes.
The development of meta-reasoning capabilities in LLMs could have significant implications for how we understand and interact with these powerful AI systems. By gaining insights into the models' thought processes, we may be able to improve their performance, ensure their safety and reliability, and unlock new applications in areas such as decision-making, scientific reasoning, and healthcare.
While the field of meta-reasoning in LLMs is still in its early stages, this paper represents an important step forward. By continuing to explore these capabilities and their broader implications, researchers may be able to push the boundaries of what is possible with large language models and advance the state of the art in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Meta Reasoning for Large Language Models
Peizhong Gao, Ao Xie, Shaoguang Mao, Wenshan Wu, Yan Xia, Haipeng Mi, Furu Wei
We introduce Meta-Reasoning Prompting (MRP), a novel and efficient system prompting method for large language models (LLMs) inspired by human meta-reasoning. Traditional in-context learning-based reasoning techniques, such as Tree-of-Thoughts, show promise but lack consistent state-of-the-art performance across diverse tasks due to their specialized nature. MRP addresses this limitation by guiding LLMs to dynamically select and apply different reasoning methods based on the specific requirements of each task, optimizing both performance and computational efficiency. With MRP, LLM reasoning operates in two phases. Initially, the LLM identifies the most appropriate reasoning method using task input cues and objective descriptions of available methods. Subsequently, it applies the chosen method to complete the task. This dynamic strategy mirrors human meta-reasoning, allowing the model to excel in a wide range of problem domains. We evaluate the effectiveness of MRP through comprehensive benchmarks. The results demonstrate that MRP achieves or approaches state-of-the-art performance across diverse tasks. MRP represents a significant advancement in enabling LLMs to identify cognitive challenges across problems and leverage benefits across different reasoning approaches, enhancing their ability to handle diverse and complex problem domains efficiently. Every LLM deserves a Meta-Reasoning Prompting to unlock its full potential and ensure adaptability in an ever-evolving landscape of challenges and applications.
Read more6/18/2024

0
Reasoning with Large Language Models, a Survey
Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, Thomas Back
Scaling up language models to billions of parameters has opened up possibilities for in-context learning, allowing instruction tuning and few-shot learning on tasks that the model was not specifically trained for. This has achieved breakthrough performance on language tasks such as translation, summarization, and question-answering. Furthermore, in addition to these associative System 1 tasks, recent advances in Chain-of-thought prompt learning have demonstrated strong System 2 reasoning abilities, answering a question in the field of artificial general intelligence whether LLMs can reason. The field started with the question whether LLMs can solve grade school math word problems. This paper reviews the rapidly expanding field of prompt-based reasoning with LLMs. Our taxonomy identifies different ways to generate, evaluate, and control multi-step reasoning. We provide an in-depth coverage of core approaches and open problems, and we propose a research agenda for the near future. Finally, we highlight the relation between reasoning and prompt-based learning, and we discuss the relation between reasoning, sequential decision processes, and reinforcement learning. We find that self-improvement, self-reflection, and some metacognitive abilities of the reasoning processes are possible through the judicious use of prompts. True self-improvement and self-reasoning, to go from reasoning with LLMs to reasoning by LLMs, remains future work.
Read more7/17/2024
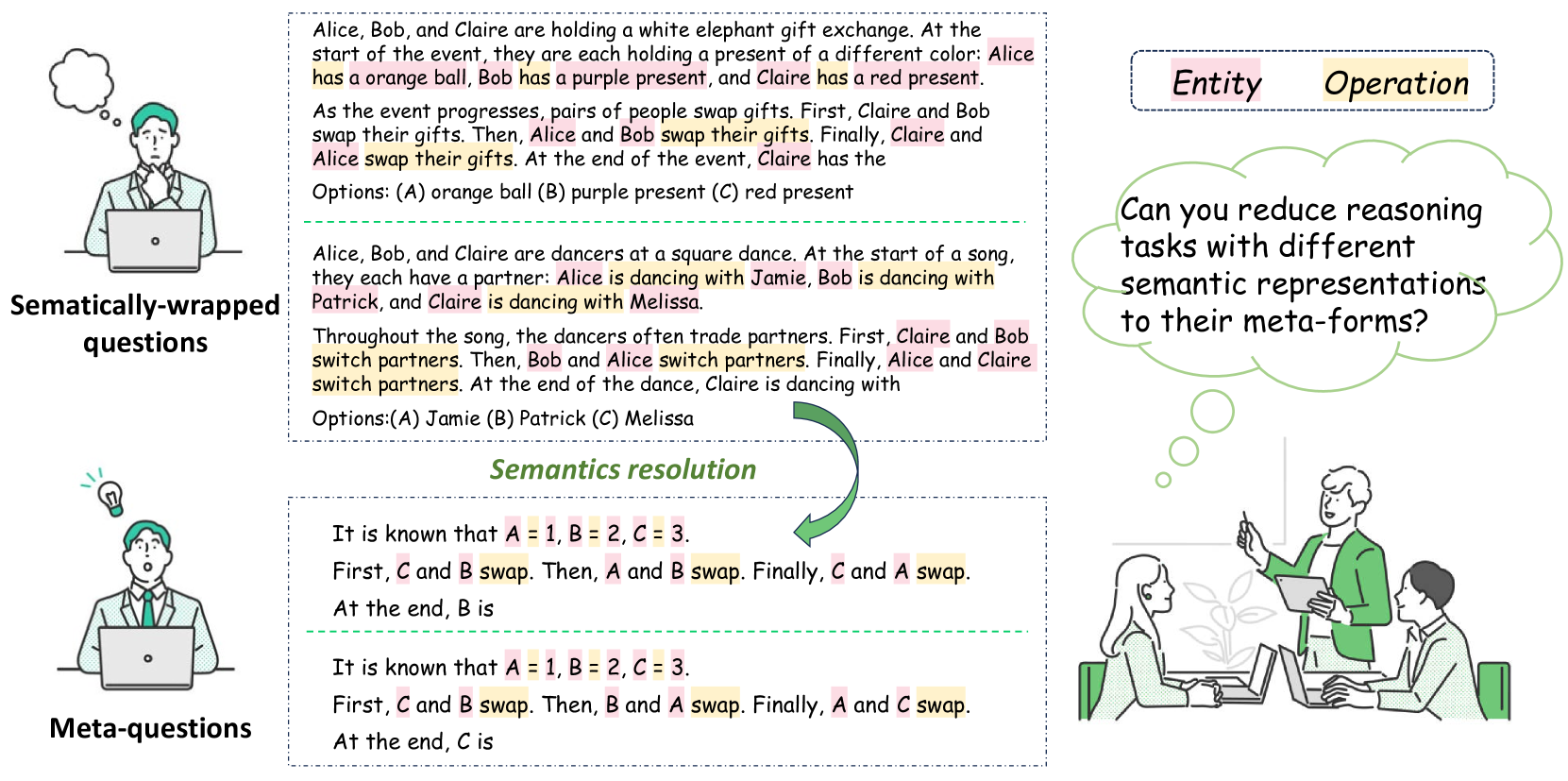
0
Meta-Reasoning: Semantics-Symbol Deconstruction for Large Language Models
Yiming Wang, Zhuosheng Zhang, Pei Zhang, Baosong Yang, Rui Wang
Neural-symbolic methods have demonstrated efficiency in enhancing the reasoning abilities of large language models (LLMs). However, existing methods mainly rely on syntactically mapping natural languages to complete formal languages like Python and SQL. Those methods require that reasoning tasks be convertible into programs, which cater to the computer execution mindset and deviate from human reasoning habits. To broaden symbolic methods' applicability and adaptability in the real world, we propose the Meta-Reasoning from a linguistic perspective. This method empowers LLMs to deconstruct reasoning-independent semantic information into generic symbolic representations, thereby efficiently capturing more generalized reasoning knowledge. We conduct extensive experiments on more than ten datasets encompassing conventional reasoning tasks like arithmetic, symbolic, and logical reasoning, and the more complex interactive reasoning tasks like theory-of-mind reasoning. Experimental results demonstrate that Meta-Reasoning significantly enhances in-context reasoning accuracy, learning efficiency, out-of-domain generalization, and output stability compared to the Chain-of-Thought technique. Code and data are publicly available at url{https://github.com/Alsace08/Meta-Reasoning}.
Read more6/4/2024

0
MR-GSM8K: A Meta-Reasoning Benchmark for Large Language Model Evaluation
Zhongshen Zeng, Pengguang Chen, Shu Liu, Haiyun Jiang, Jiaya Jia
In this work, we introduce a novel evaluation paradigm for Large Language Models (LLMs) that compels them to transition from a traditional question-answering role, akin to a student, to a solution-scoring role, akin to a teacher. This paradigm, focusing on reasoning about reasoning, hence termed meta-reasoning, shifts the emphasis from result-oriented assessments, which often neglect the reasoning process, to a more comprehensive evaluation that effectively distinguishes between the cognitive capabilities of different models. By applying this paradigm in the GSM8K dataset, we have developed the MR-GSM8K benchmark. Our extensive analysis includes several state-of-the-art models from both open-source and commercial domains, uncovering fundamental deficiencies in their training and evaluation methodologies. Notably, while models like Deepseek-v2 and Claude3-Sonnet closely competed with GPT-4 in GSM8K, their performance disparities expanded dramatically in MR-GSM8K, with differences widening to over 20 absolute points, underscoring the significant challenge posed by our meta-reasoning approach.
Read more6/6/2024