MARS: Benchmarking the Metaphysical Reasoning Abilities of Language Models with a Multi-task Evaluation Dataset

0

Sign in to get full access
Overview
- This paper introduces a new evaluation dataset called MARS (Metaphysical Reasoning Semantics) to benchmark the metaphysical reasoning abilities of large language models.
- MARS covers a wide range of metaphysical concepts and reasoning tasks, allowing for a comprehensive assessment of language models' performance in this domain.
- The authors evaluate several popular language models on the MARS dataset and analyze the results to gain insights into the models' strengths, weaknesses, and limitations when it comes to metaphysical reasoning.
Plain English Explanation
The paper focuses on evaluating the metaphysical reasoning abilities of large language models, which are AI systems trained on vast amounts of text data to understand and generate human-like language. The researchers created a new dataset called MARS (Metaphysical Reasoning Semantics) that covers a broad range of metaphysical concepts and reasoning tasks, such as understanding the nature of reality, knowledge, and existence.
By testing various language models on the MARS dataset, the researchers aimed to gain insights into how well these models can perform when it comes to metaphysical reasoning - an area that is considered particularly challenging for AI systems. The results of their evaluation provide valuable information about the strengths, weaknesses, and limitations of these language models in this domain, which can help guide future research and development efforts in AI reasoning and semantics.
Technical Explanation
The researchers created the MARS dataset, which consists of a diverse set of metaphysical reasoning tasks, including questions about the nature of reality, knowledge, and existence. These tasks cover a wide range of metaphysical concepts and require language models to engage in complex reasoning and understanding.
The authors evaluated several popular language models, such as GPT-3, BERT, and RoBERTa, on the MARS dataset. They analyzed the models' performance across different types of tasks and metaphysical concepts, as well as their ability to handle different levels of complexity and abstraction. The results of their evaluation provide insights into the models' strengths and limitations in the domain of metaphysical reasoning.
For example, the authors found that while the language models performed reasonably well on some simpler tasks, they struggled with more complex metaphysical reasoning, such as understanding the relationship between mind and matter or grappling with the nature of consciousness. The study also highlighted the models' difficulties in generalizing their knowledge and reasoning abilities across different metaphysical concepts and contexts.
Critical Analysis
The researchers acknowledge that the MARS dataset and their evaluation methodology have certain limitations. For instance, the dataset may not capture the full breadth and complexity of metaphysical reasoning, and the language models may perform differently on other types of metaphysical tasks or datasets. Additionally, the researchers note that the models' performance may be influenced by the specific training data and architectures used, and further research is needed to explore the underlying factors that contribute to their strengths and weaknesses in this domain.
It is also worth considering whether the current state-of-the-art language models are the most appropriate tools for tackling metaphysical reasoning tasks, which often involve abstract, conceptual, and subjective elements that may not be easily captured by language models trained primarily on textual data. Exploring alternative approaches, such as integrating symbolic reasoning or incorporating additional modalities, may be necessary to make further progress in this area.
Conclusion
This paper presents a novel evaluation dataset, MARS, and uses it to assess the metaphysical reasoning abilities of several prominent language models. The results highlight the current limitations of these models in grappling with complex metaphysical concepts and tasks, suggesting that more work is needed to develop AI systems that can engage in more sophisticated and nuanced reasoning about the nature of reality, knowledge, and existence. The insights gained from this study can inform future research directions and help drive the development of more advanced AI reasoning and semantics capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MARS: Benchmarking the Metaphysical Reasoning Abilities of Language Models with a Multi-task Evaluation Dataset
Weiqi Wang, Yangqiu Song
To enable Large Language Models (LLMs) to function as conscious agents with generalizable reasoning capabilities, it is crucial that they possess the reasoning ability to comprehend situational changes (transitions) in distribution triggered by environmental factors or actions from other agents. Despite its fundamental significance, this ability remains underexplored due to the complexity of modeling infinite possible changes in an event and their associated distributions, coupled with the lack of benchmark data with situational transitions. Addressing these gaps, we propose a novel formulation of reasoning with distributional changes as a three-step discriminative process, termed as MetAphysical ReaSoning. We then introduce the first-ever benchmark, MARS, comprising three tasks corresponding to each step. These tasks systematically assess LLMs' capabilities in reasoning the plausibility of (i) changes in actions, (ii) states caused by changed actions, and (iii) situational transitions driven by changes in action. Extensive evaluations with 20 (L)LMs of varying sizes and methods indicate that all three tasks in this process pose significant challenges, even for state-of-the-art LLMs and LMs after fine-tuning. Further analyses reveal potential causes for the underperformance of LLMs and demonstrate that pre-training them on large-scale conceptualization taxonomies can potentially enhance their metaphysical reasoning capabilities. Our data and models are publicly accessible at https://github.com/HKUST-KnowComp/MARS.
Read more6/5/2024

0
MR-GSM8K: A Meta-Reasoning Benchmark for Large Language Model Evaluation
Zhongshen Zeng, Pengguang Chen, Shu Liu, Haiyun Jiang, Jiaya Jia
In this work, we introduce a novel evaluation paradigm for Large Language Models (LLMs) that compels them to transition from a traditional question-answering role, akin to a student, to a solution-scoring role, akin to a teacher. This paradigm, focusing on reasoning about reasoning, hence termed meta-reasoning, shifts the emphasis from result-oriented assessments, which often neglect the reasoning process, to a more comprehensive evaluation that effectively distinguishes between the cognitive capabilities of different models. By applying this paradigm in the GSM8K dataset, we have developed the MR-GSM8K benchmark. Our extensive analysis includes several state-of-the-art models from both open-source and commercial domains, uncovering fundamental deficiencies in their training and evaluation methodologies. Notably, while models like Deepseek-v2 and Claude3-Sonnet closely competed with GPT-4 in GSM8K, their performance disparities expanded dramatically in MR-GSM8K, with differences widening to over 20 absolute points, underscoring the significant challenge posed by our meta-reasoning approach.
Read more6/6/2024

0
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Zhongshen Zeng, Yinhong Liu, Yingjia Wan, Jingyao Li, Pengguang Chen, Jianbo Dai, Yuxuan Yao, Rongwu Xu, Zehan Qi, Wanru Zhao, Linling Shen, Jianqiao Lu, Haochen Tan, Yukang Chen, Hao Zhang, Zhan Shi, Bailin Wang, Zhijiang Guo, Jiaya Jia
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
Read more6/21/2024
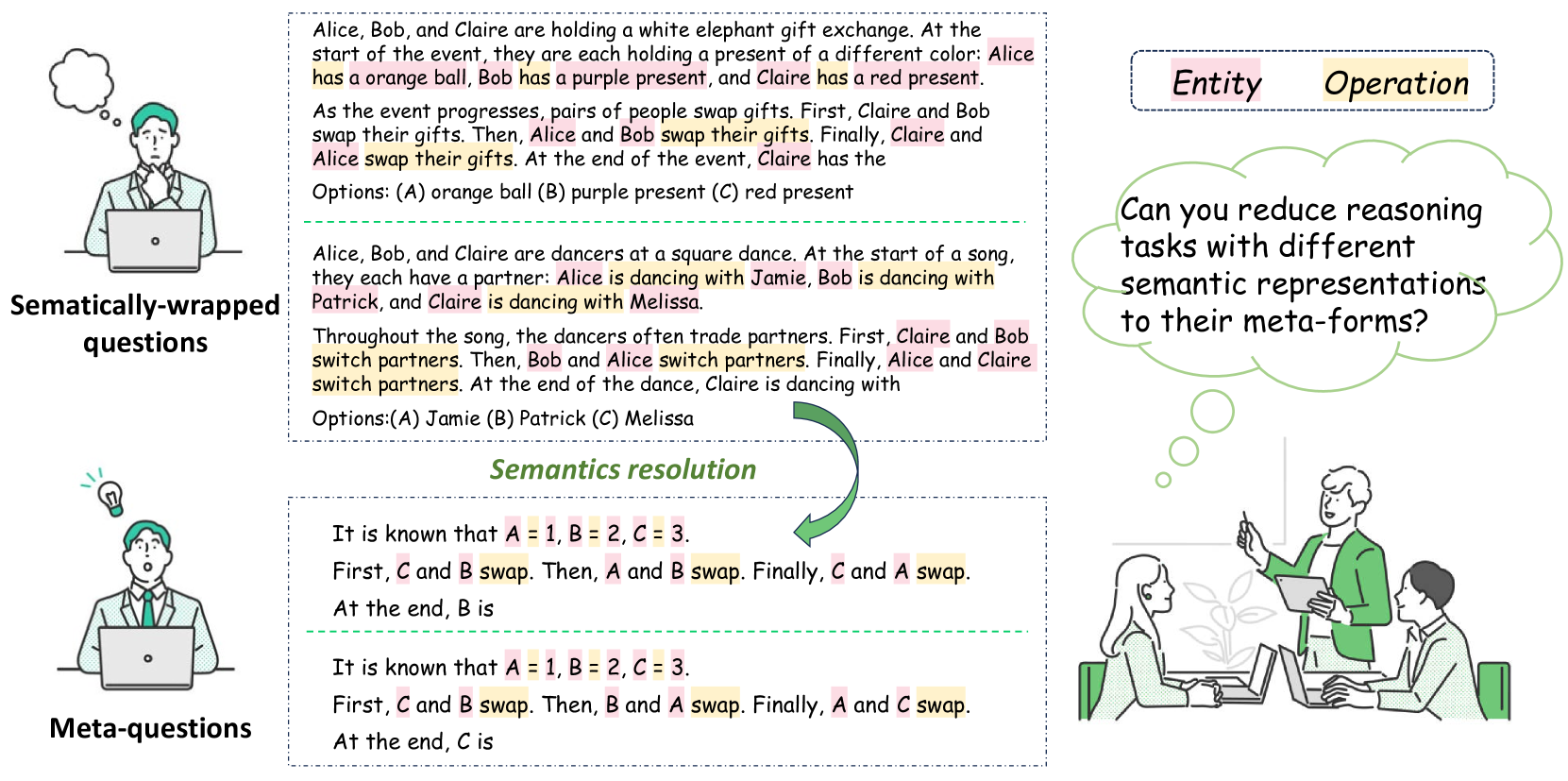
0
Meta-Reasoning: Semantics-Symbol Deconstruction for Large Language Models
Yiming Wang, Zhuosheng Zhang, Pei Zhang, Baosong Yang, Rui Wang
Neural-symbolic methods have demonstrated efficiency in enhancing the reasoning abilities of large language models (LLMs). However, existing methods mainly rely on syntactically mapping natural languages to complete formal languages like Python and SQL. Those methods require that reasoning tasks be convertible into programs, which cater to the computer execution mindset and deviate from human reasoning habits. To broaden symbolic methods' applicability and adaptability in the real world, we propose the Meta-Reasoning from a linguistic perspective. This method empowers LLMs to deconstruct reasoning-independent semantic information into generic symbolic representations, thereby efficiently capturing more generalized reasoning knowledge. We conduct extensive experiments on more than ten datasets encompassing conventional reasoning tasks like arithmetic, symbolic, and logical reasoning, and the more complex interactive reasoning tasks like theory-of-mind reasoning. Experimental results demonstrate that Meta-Reasoning significantly enhances in-context reasoning accuracy, learning efficiency, out-of-domain generalization, and output stability compared to the Chain-of-Thought technique. Code and data are publicly available at url{https://github.com/Alsace08/Meta-Reasoning}.
Read more6/4/2024