Meta-Whisper: Speech-Based Meta-ICL for ASR on Low-Resource Languages

0

Sign in to get full access
Overview
- Proposes "Meta-Whisper", a speech-based meta-in-context learning (meta-ICL) approach for automatic speech recognition (ASR) on low-resource languages
- Leverages the pre-trained Whisper model to enable efficient and effective fine-tuning on low-data tasks
- Demonstrates improved performance over direct fine-tuning of Whisper on various low-resource ASR benchmarks
Plain English Explanation
The researchers have developed a new technique called "Meta-Whisper" that can help improve automatic speech recognition (ASR) for languages that don't have a lot of training data available. ASR is the process of converting spoken audio into written text, and it's an important technology for things like voice assistants and transcription.
The key idea behind Meta-Whisper is to leverage a powerful pre-trained model called Whisper, which has been trained on a huge amount of multilingual speech data. Instead of directly fine-tuning Whisper on the low-resource language, Meta-Whisper uses a "meta-learning" approach. This means it learns how to efficiently adapt Whisper to the target language, rather than just doing a standard fine-tuning process.
By using this meta-learning technique, the researchers were able to achieve better ASR performance on various low-resource language benchmarks, compared to simply fine-tuning Whisper directly. The key advantage is that Meta-Whisper can learn to adapt the pre-trained Whisper model in a more efficient and effective way, even when there is limited training data available for the target language.
Technical Explanation
The core of the Meta-Whisper approach is a meta-learning framework that enables efficient fine-tuning of the pre-trained Whisper model on low-resource ASR tasks. The key steps are:
-
Whisper Pretraining: The researchers start with the publicly available Whisper model, which has been pre-trained on a huge multilingual speech dataset.
-
Meta-Training: They then train a "meta-learner" that can learn to adapt the Whisper model to new low-resource ASR tasks quickly and efficiently. This meta-learner is trained on simulated low-resource ASR tasks, learning an initialization and update strategy that enables fast adaptation.
-
Fine-Tuning: For a target low-resource ASR task, the researchers initialize the Whisper model using the meta-learned parameters, then fine-tune it on the limited training data available.
The meta-learning approach allows the model to capitalize on the rich knowledge captured by the pre-trained Whisper, while learning an efficient fine-tuning strategy that works well even with small datasets. The researchers evaluate Meta-Whisper on several low-resource ASR benchmarks, demonstrating significant performance improvements over direct fine-tuning of Whisper.
Critical Analysis
The Meta-Whisper paper presents a well-designed and technically sound approach for addressing the challenge of low-resource ASR. The key strengths of the work include:
-
Leveraging Pre-Trained Models: By building upon the powerful Whisper model, the researchers are able to tap into rich multilingual speech representations, overcoming the data scarcity issue in low-resource settings.
-
Principled Meta-Learning: The meta-learning framework is a principled way to learn an efficient fine-tuning strategy, going beyond simple fine-tuning techniques.
-
Comprehensive Evaluation: The researchers evaluate Meta-Whisper on a diverse set of low-resource ASR benchmarks, demonstrating consistent performance improvements.
However, the paper also raises a few areas for further consideration:
-
Computational Efficiency: While Meta-Whisper outperforms direct fine-tuning, the meta-learning process itself can be computationally intensive. The researchers could explore ways to further optimize the training efficiency.
-
Applicability to Truly Low-Resource Settings: The paper's evaluation focuses on simulated low-resource settings, where some data is still available. It would be valuable to also test Meta-Whisper in scenarios with even more extreme data scarcity.
-
Interpretability: As with many deep learning models, the internal workings of Meta-Whisper may be opaque. Improving the interpretability of the meta-learning process could provide additional insights.
Overall, the Meta-Whisper work represents an important advance in the field of multilingual ASR, with the potential to democratize high-performance speech recognition for underserved languages and communities. Further research into its practical applications and limitations would be a valuable next step.
Related work in this area includes efforts to develop efficient compression techniques for multitask, multilingual speech models and adaptive, incremental ASR frameworks that can handle diverse deployment scenarios.
Conclusion
The Meta-Whisper paper presents a novel speech-based meta-in-context learning (meta-ICL) approach for improving automatic speech recognition (ASR) performance on low-resource languages. By leveraging the pre-trained Whisper model and learning an efficient fine-tuning strategy through meta-learning, the researchers were able to achieve significant performance gains over direct fine-tuning on various low-resource ASR benchmarks.
This work has important implications for expanding the reach of high-quality speech recognition technology to a wider range of languages and communities around the world, especially those that have been historically underserved by existing systems. The meta-learning framework represents an exciting advance in the field of multilingual ASR, and further research into its practical applications and limitations could yield valuable insights.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Meta-Whisper: Speech-Based Meta-ICL for ASR on Low-Resource Languages
Ming-Hao Hsu, Kuan Po Huang, Hung-yi Lee
This paper presents Meta-Whisper, a novel approach to improve automatic speech recognition (ASR) for low-resource languages using the Whisper model. By leveraging Meta In-Context Learning (Meta-ICL) and a k-Nearest Neighbors (KNN) algorithm for sample selection, Meta-Whisper enhances Whisper's ability to recognize speech in unfamiliar languages without extensive fine-tuning. Experiments on the ML-SUPERB dataset show that Meta-Whisper significantly reduces the Character Error Rate (CER) for low-resource languages compared to the original Whisper model. This method offers a promising solution for developing more adaptable multilingual ASR systems, particularly for languages with limited resources.
Read more9/17/2024
0
New!M2R-Whisper: Multi-stage and Multi-scale Retrieval Augmentation for Enhancing Whisper
Jiaming Zhou, Shiwan Zhao, Jiabei He, Hui Wang, Wenjia Zeng, Yong Chen, Haoqin Sun, Aobo Kong, Yong Qin
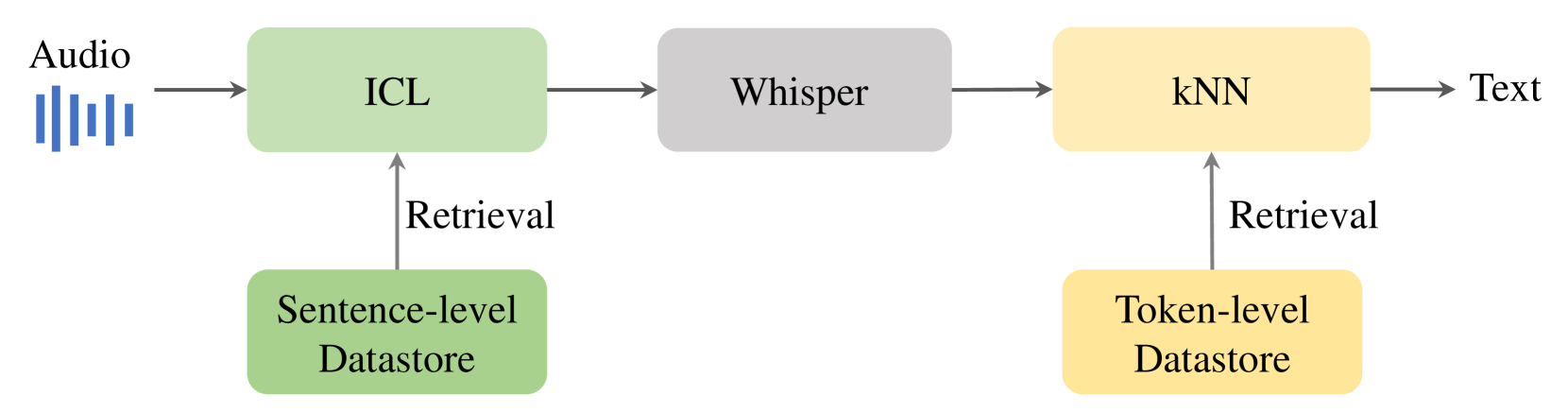
State-of-the-art models like OpenAI's Whisper exhibit strong performance in multilingual automatic speech recognition (ASR), but they still face challenges in accurately recognizing diverse subdialects. In this paper, we propose M2R-whisper, a novel multi-stage and multi-scale retrieval augmentation approach designed to enhance ASR performance in low-resource settings. Building on the principles of in-context learning (ICL) and retrieval-augmented techniques, our method employs sentence-level ICL in the pre-processing stage to harness contextual information, while integrating token-level k-Nearest Neighbors (kNN) retrieval as a post-processing step to further refine the final output distribution. By synergistically combining sentence-level and token-level retrieval strategies, M2R-whisper effectively mitigates various types of recognition errors. Experiments conducted on Mandarin and subdialect datasets, including AISHELL-1 and KeSpeech, demonstrate substantial improvements in ASR accuracy, all achieved without any parameter updates.
Read more9/19/2024
0
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Read more5/3/2024

0
LoRA-Whisper: Parameter-Efficient and Extensible Multilingual ASR
Zheshu Song, Jianheng Zhuo, Yifan Yang, Ziyang Ma, Shixiong Zhang, Xie Chen
Recent years have witnessed significant progress in multilingual automatic speech recognition (ASR), driven by the emergence of end-to-end (E2E) models and the scaling of multilingual datasets. Despite that, two main challenges persist in multilingual ASR: language interference and the incorporation of new languages without degrading the performance of the existing ones. This paper proposes LoRA-Whisper, which incorporates LoRA matrix into Whisper for multilingual ASR, effectively mitigating language interference. Furthermore, by leveraging LoRA and the similarities between languages, we can achieve better performance on new languages while upholding consistent performance on original ones. Experiments on a real-world task across eight languages demonstrate that our proposed LoRA-Whisper yields a relative gain of 18.5% and 23.0% over the baseline system for multilingual ASR and language expansion respectively.
Read more6/12/2024