DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs
2406.04334
0
0
Abstract
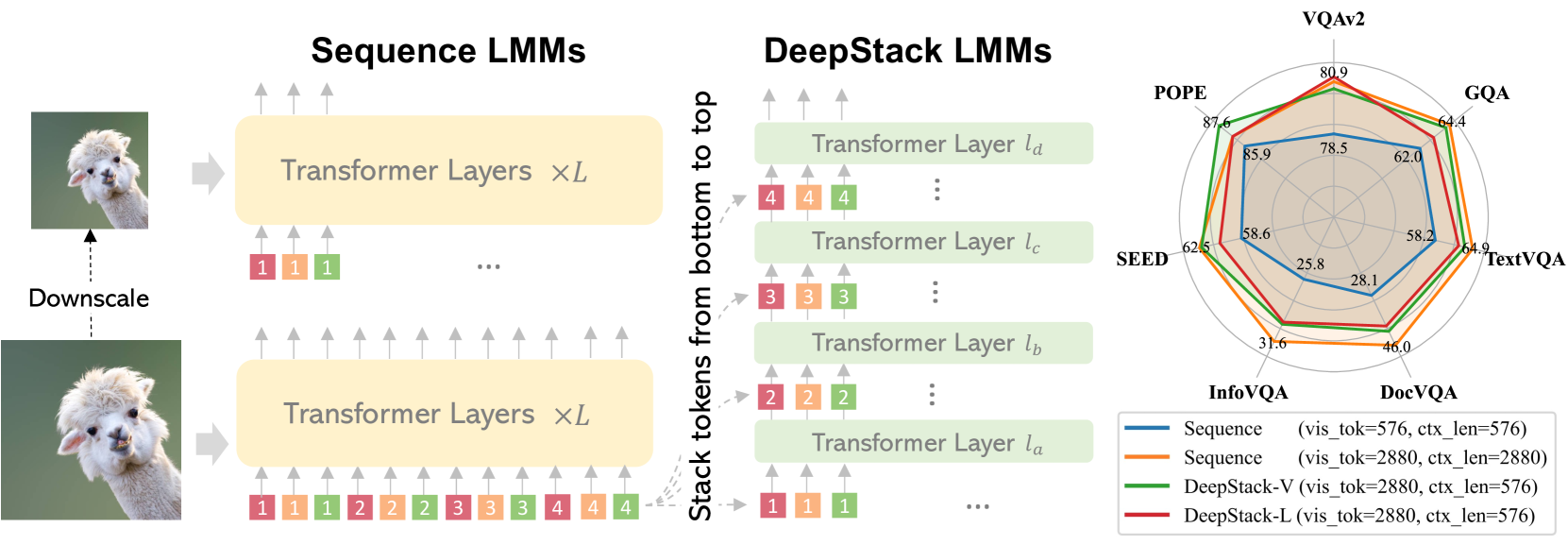
Most large multimodal models (LMMs) are implemented by feeding visual tokens as a sequence into the first layer of a large language model (LLM). The resulting architecture is simple but significantly increases computation and memory costs, as it has to handle a large number of additional tokens in its input layer. This paper presents a new architecture DeepStack for LMMs. Considering $N$ layers in the language and vision transformer of LMMs, we stack the visual tokens into $N$ groups and feed each group to its aligned transformer layer textit{from bottom to top}. Surprisingly, this simple method greatly enhances the power of LMMs to model interactions among visual tokens across layers but with minimal additional cost. We apply DeepStack to both language and vision transformer in LMMs, and validate the effectiveness of DeepStack LMMs with extensive empirical results. Using the same context length, our DeepStack 7B and 13B parameters surpass their counterparts by textbf{2.7} and textbf{2.9} on average across textbf{9} benchmarks, respectively. Using only one-fifth of the context length, DeepStack rivals closely to the counterparts that use the full context length. These gains are particularly pronounced on high-resolution tasks, e.g., textbf{4.2}, textbf{11.0}, and textbf{4.0} improvements on TextVQA, DocVQA, and InfoVQA compared to LLaVA-1.5-7B, respectively. We further apply DeepStack to vision transformer layers, which brings us a similar amount of improvements, textbf{3.8} on average compared with LLaVA-1.5-7B.
Create account to get full access
Overview
- The paper presents a novel deep learning model called DeepStack, which leverages a simple yet effective technique of deeply stacking visual tokens to improve the performance of large language models (LLMs) on multimodal tasks.
- The authors demonstrate that DeepStack can outperform leading multimodal LLMs on a variety of benchmarks, including image-text retrieval, visual question answering, and multimodal reasoning.
- The key innovation of DeepStack is its ability to deeply integrate visual information into the language model, allowing the model to better understand and reason about the relationships between text and visual content.
Plain English Explanation
The paper introduces a new deep learning model called DeepStack that combines language and visual information in a powerful way. The core idea is to "stack" visual information, or visual "tokens," very deeply into the language model, allowing the model to better understand and reason about the connections between text and images.
Typically, language models and vision models are trained separately and then combined for multimodal tasks like image captioning or visual question answering. DeepStack takes a different approach by integrating the visual tokens deeply into the language model. This allows the model to learn richer representations that capture the relationships between text and visual content.
The authors show that this simple but effective technique allows DeepStack to outperform leading multimodal language models on a variety of benchmarks. For example, DeepStack does better at retrieving relevant images given text and answering questions about images. This suggests that deeply integrating visual information into language models can be a powerful way to leverage visual contexts to enhance language understanding.
Technical Explanation
The key innovation of DeepStack is its approach to integrating visual information into the language model. Rather than just concatenating visual features to the language model input, DeepStack stacks visual tokens deeply into the transformer layers. This allows the model to learn richer representations that capture the complex relationships between text and visual content.
Specifically, DeepStack takes visual features extracted from an image and converts them into "visual tokens" that can be processed by the transformer layers of the language model. These visual tokens are then stacked alongside the text tokens at multiple layers of the transformer, allowing the model to learn multimodal representations.
The authors evaluate DeepStack on a range of multimodal benchmarks, including image-text retrieval, visual question answering, and multimodal reasoning. They show that DeepStack significantly outperforms leading multimodal language models like Frozen Transformers and LXMERT, demonstrating the power of their simple yet effective approach to integrating visual information.
Critical Analysis
The paper presents a strong technical contribution, demonstrating the benefits of deeply integrating visual information into language models. However, the authors do not delve deeply into the limitations or potential caveats of their approach.
For example, it would be valuable to understand how the performance of DeepStack scales with the amount of visual information available, and whether there are diminishing returns or an optimal level of visual integration. Additionally, the paper does not explore the computational cost or inference time of DeepStack compared to other multimodal models, which could be an important practical consideration.
Furthermore, the paper does not discuss the potential biases or ethical implications of using such a powerful multimodal model, which is an increasingly important consideration as these technologies become more widely deployed.
Overall, the paper makes a compelling case for the effectiveness of DeepStack, but there is room for further exploration and analysis to fully understand the strengths, limitations, and broader implications of this approach.
Conclusion
The DeepStack paper presents a novel and effective technique for integrating visual information into large language models, demonstrating significant performance improvements on a variety of multimodal benchmarks. By deeply stacking visual tokens into the transformer architecture, the model is able to learn richer representations that capture the complex relationships between text and visual content.
This work suggests that leveraging visual contexts can be a powerful way to enhance language understanding, and that simple but effective techniques like deep token stacking can be surprisingly effective for improving the performance of large language models on multimodal tasks. As the field of multimodal AI continues to evolve, the insights and techniques presented in this paper may prove influential in the development of more powerful and versatile language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Matryoshka Multimodal Models
Mu Cai, Jianwei Yang, Jianfeng Gao, Yong Jae Lee
0
0
Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM). However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency. While token pruning/merging methods do exist, they produce a single length output for each image and do not afford flexibility in trading off information density v.s. efficiency. Inspired by the concept of Matryoshka Dolls, we propose M3: Matryoshka Multimodal Models, which learns to represent visual content as nested sets of visual tokens that capture information across multiple coarse-to-fine granularities. Our approach offers several unique benefits for LMMs: (1) One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image based on the anticipated complexity or simplicity of the content; (2) M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens; (3) Our approach provides a foundation to explore the best trade-off between performance and visual token length at sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.
5/28/2024
New!LLaVolta: Efficient Multi-modal Models via Stage-wise Visual Context Compression
Jieneng Chen, Luoxin Ye, Ju He, Zhao-Yang Wang, Daniel Khashabi, Alan Yuille
0
0
While significant advancements have been made in compressed representations for text embeddings in large language models (LLMs), the compression of visual tokens in large multi-modal models (LMMs) has remained a largely overlooked area. In this work, we present the study on the analysis of redundancy concerning visual tokens and efficient training within these models. Our initial experiments show that eliminating up to 70% of visual tokens at the testing stage by simply average pooling only leads to a minimal 3% reduction in visual question answering accuracy on the GQA benchmark, indicating significant redundancy in visual context. Addressing this, we introduce Visual Context Compressor, which reduces the number of visual tokens during training to enhance training efficiency without sacrificing performance. To minimize information loss caused by the compression on visual tokens while maintaining training efficiency, we develop LLaVolta as a lite training scheme. LLaVolta incorporates stage-wise visual context compression to progressively compress the visual tokens from heavily to lightly, and finally no compression at the end of training, yielding no loss of information when testing. Extensive experiments demonstrate that our approach enhances the performance of MLLMs in both image-language and video-language understanding, while also significantly cutting training costs. Code is available at https://github.com/Beckschen/LLaVolta
7/1/2024

Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, Ziwei Liu
0
0
Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
6/26/2024
📈
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
Wenyu Du, Tongxu Luo, Zihan Qiu, Zeyu Huang, Yikang Shen, Reynold Cheng, Yike Guo, Jie Fu
0
0
LLMs are computationally expensive to pre-train due to their large scale. Model growth emerges as a promising approach by leveraging smaller models to accelerate the training of larger ones. However, the viability of these model growth methods in efficient LLM pre-training remains underexplored. This work identifies three critical $underline{textit{O}}$bstacles: ($textit{O}$1) lack of comprehensive evaluation, ($textit{O}$2) untested viability for scaling, and ($textit{O}$3) lack of empirical guidelines. To tackle $textit{O}$1, we summarize existing approaches into four atomic growth operators and systematically evaluate them in a standardized LLM pre-training setting. Our findings reveal that a depthwise stacking operator, called $G_{text{stack}}$, exhibits remarkable acceleration in training, leading to decreased loss and improved overall performance on eight standard NLP benchmarks compared to strong baselines. Motivated by these promising results, we conduct extensive experiments to delve deeper into $G_{text{stack}}$ to address $textit{O}$2 and $textit{O}$3. For $textit{O}$2 (untested scalability), our study shows that $G_{text{stack}}$ is scalable and consistently performs well, with experiments up to 7B LLMs after growth and pre-training LLMs with 750B tokens. For example, compared to a conventionally trained 7B model using 300B tokens, our $G_{text{stack}}$ model converges to the same loss with 194B tokens, resulting in a 54.6% speedup. We further address $textit{O}$3 (lack of empirical guidelines) by formalizing guidelines to determine growth timing and growth factor for $G_{text{stack}}$, making it practical in general LLM pre-training. We also provide in-depth discussions and comprehensive ablation studies of $G_{text{stack}}$. Our code and pre-trained model are available at $href{https://llm-stacking.github.io/}{https://llm-stacking.github.io/}$.
5/27/2024