Understanding the Capabilities and Limitations of Large Language Models for Cultural Commonsense
2405.04655
0
0
🤔
Abstract
Large language models (LLMs) have demonstrated substantial commonsense understanding through numerous benchmark evaluations. However, their understanding of cultural commonsense remains largely unexamined. In this paper, we conduct a comprehensive examination of the capabilities and limitations of several state-of-the-art LLMs in the context of cultural commonsense tasks. Using several general and cultural commonsense benchmarks, we find that (1) LLMs have a significant discrepancy in performance when tested on culture-specific commonsense knowledge for different cultures; (2) LLMs' general commonsense capability is affected by cultural context; and (3) The language used to query the LLMs can impact their performance on cultural-related tasks. Our study points to the inherent bias in the cultural understanding of LLMs and provides insights that can help develop culturally aware language models.
Create account to get full access
Overview
- This paper examines the capabilities and limitations of large language models (LLMs) in understanding cultural commonsense knowledge.
- The researchers use several benchmark evaluations to assess how well LLMs perform on tasks related to cultural commonsense, as opposed to general commonsense.
- The key findings include:
- LLMs exhibit a significant discrepancy in performance when tested on culture-specific commonsense knowledge for different cultures.
- LLMs' general commonsense capability is affected by cultural context.
- The language used to query the LLMs can impact their performance on culture-related tasks.
Plain English Explanation
Large language models (LLMs) are AI systems that can understand and generate human-like text. These models have shown impressive abilities in understanding general common sense - the kind of basic knowledge that humans take for granted. However, the paper suggests that LLMs may struggle with understanding cultural common sense, which refers to the shared knowledge and assumptions specific to a particular culture.
To investigate this, the researchers tested several state-of-the-art LLMs on a variety of commonsense tasks, including both general and culture-specific ones. They found that the LLMs performed much better on the general commonsense tasks than on the culture-specific ones. This indicates that these models have inherent biases in their cultural understanding, likely due to the data they were trained on.
Additionally, the researchers discovered that the LLMs' performance on general commonsense tasks was affected by the cultural context of the questions. And the language used to ask the LLMs about cultural topics also influenced their responses.
These findings suggest that while LLMs have made impressive strides in common sense reasoning, they still have limitations when it comes to understanding and reasoning about cultural knowledge. Developing more culturally-aware language models could be an important next step in making these AI systems more robust and applicable across diverse cultural contexts.
Technical Explanation
The researchers conducted a comprehensive evaluation of several state-of-the-art large language models (LLMs), including GPT-3, BERT, and RoBERTa, to assess their capabilities and limitations in understanding cultural commonsense knowledge. They used a variety of commonsense benchmarks, both general and culture-specific, to test the LLMs' performance.
The general commonsense benchmarks evaluated the models' understanding of common sense reasoning, while the culture-specific benchmarks focused on commonsense knowledge related to particular cultural contexts, such as Can LLMs Generate Culturally Relevant Commonsense QA and Evaluating Consistency Reasoning Capabilities of Large Language Models.
The researchers found that the LLMs exhibited a significant discrepancy in performance when tested on culture-specific commonsense knowledge for different cultures. This suggests that the models have inherent biases in their cultural understanding, likely due to the data they were trained on, which may not have adequately covered diverse cultural perspectives.
Furthermore, the researchers discovered that the LLMs' general commonsense capability was affected by cultural context. This indicates that the models' understanding of common sense is not entirely universal and can be influenced by cultural factors.
Additionally, the language used to query the LLMs was found to impact their performance on culture-related tasks. This highlights the importance of considering the cultural sensitivity of the language used when interacting with these models, as it can affect their ability to reason about cultural knowledge.
Critical Analysis
The paper provides valuable insights into the limitations of large language models (LLMs) in understanding cultural commonsense knowledge. The researchers' comprehensive evaluation across multiple benchmarks and LLM architectures lends credibility to their findings.
However, the paper acknowledges that the cultural commonsense benchmarks used in the study may not be exhaustive, and there may be other aspects of cultural knowledge that were not explored. Additionally, the paper does not delve into the specific biases or inaccuracies exhibited by the LLMs in their cultural understanding, which could be an area for further investigation.
Another potential limitation is that the paper focuses on the LLMs' performance on cultural commonsense tasks, but does not address how these models might perform on more complex cultural reasoning or contextual understanding tasks. Adapting Large Language Models for Education: Foundational Capabilities and Using Large Language Models to Generate Capability provide additional insights into the broader capabilities and limitations of LLMs.
It would also be valuable to explore whether the observed cultural biases in LLMs can be mitigated through techniques such as Evaluating Deductive Competence of Large Language Models or other targeted fine-tuning or data augmentation approaches.
Conclusion
This paper highlights the need for a deeper understanding of the cultural commonsense knowledge possessed by large language models (LLMs). The findings suggest that while LLMs have made significant strides in general commonsense reasoning, they still struggle with culture-specific knowledge, exhibiting inherent biases and limitations.
Developing more culturally-aware language models could be an important step in making these AI systems more robust and applicable across diverse cultural contexts. This research provides valuable insights that can inform the continued advancement of LLMs and their ability to engage with and reason about cultural knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, Chulin Xie, Chiyuan Zhang
0
0
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
6/26/2024

Can large language models understand uncommon meanings of common words?
Jinyang Wu, Feihu Che, Xinxin Zheng, Shuai Zhang, Ruihan Jin, Shuai Nie, Pengpeng Shao, Jianhua Tao
0
0
Large language models (LLMs) like ChatGPT have shown significant advancements across diverse natural language understanding (NLU) tasks, including intelligent dialogue and autonomous agents. Yet, lacking widely acknowledged testing mechanisms, answering `whether LLMs are stochastic parrots or genuinely comprehend the world' remains unclear, fostering numerous studies and sparking heated debates. Prevailing research mainly focuses on surface-level NLU, neglecting fine-grained explorations. However, such explorations are crucial for understanding their unique comprehension mechanisms, aligning with human cognition, and finally enhancing LLMs' general NLU capacities. To address this gap, our study delves into LLMs' nuanced semantic comprehension capabilities, particularly regarding common words with uncommon meanings. The idea stems from foundational principles of human communication within psychology, which underscore accurate shared understandings of word semantics. Specifically, this paper presents the innovative construction of a Lexical Semantic Comprehension (LeSC) dataset with novel evaluation metrics, the first benchmark encompassing both fine-grained and cross-lingual dimensions. Introducing models of both open-source and closed-source, varied scales and architectures, our extensive empirical experiments demonstrate the inferior performance of existing models in this basic lexical-meaning understanding task. Notably, even the state-of-the-art LLMs GPT-4 and GPT-3.5 lag behind 16-year-old humans by 3.9% and 22.3%, respectively. Additionally, multiple advanced prompting techniques and retrieval-augmented generation are also introduced to help alleviate this trouble, yet limitations persist. By highlighting the above critical shortcomings, this research motivates further investigation and offers novel insights for developing more intelligent LLMs.
5/10/2024
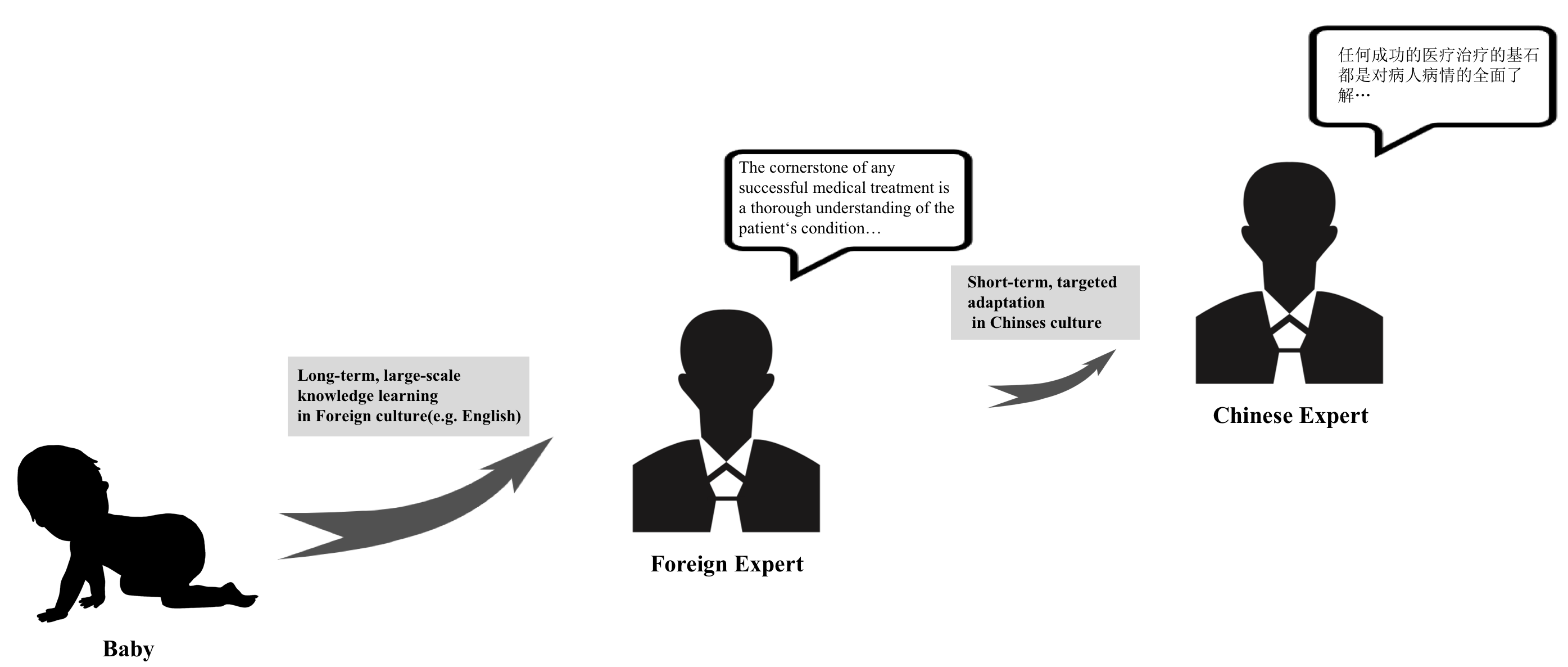
Methodology of Adapting Large English Language Models for Specific Cultural Contexts
Wenjing Zhang, Siqi Xiao, Xuejiao Lei, Ning Wang, Huazheng Zhang, Meijuan An, Bikun Yang, Zhaoxiang Liu, Kai Wang, Shiguo Lian
0
0
The rapid growth of large language models(LLMs) has emerged as a prominent trend in the field of artificial intelligence. However, current state-of-the-art LLMs are predominantly based on English. They encounter limitations when directly applied to tasks in specific cultural domains, due to deficiencies in domain-specific knowledge and misunderstandings caused by differences in cultural values. To address this challenge, our paper proposes a rapid adaptation method for large models in specific cultural contexts, which leverages instruction-tuning based on specific cultural knowledge and safety values data. Taking Chinese as the specific cultural context and utilizing the LLaMA3-8B as the experimental English LLM, the evaluation results demonstrate that the adapted LLM significantly enhances its capabilities in domain-specific knowledge and adaptability to safety values, while maintaining its original expertise advantages.
6/28/2024

CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jie Feng, Jun Zhang, Junbo Yan, Xin Zhang, Tianjian Ouyang, Tianhui Liu, Yuwei Du, Siqi Guo, Yong Li
0
0
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
6/21/2024