MFE-ETP: A Comprehensive Evaluation Benchmark for Multi-modal Foundation Models on Embodied Task Planning

0
Sign in to get full access
Overview
- Proposes a new benchmark called MFM-ETP for evaluating the task planning capabilities of multi-modal foundation models in embodied environments
- Aims to assess how well these models can understand and execute high-level instructions in simulated 3D environments
- Combines visual, linguistic, and physical reasoning to mimic real-world task planning challenges
Plain English Explanation
The paper introduces a new test called MFM-ETP that is designed to evaluate how well advanced artificial intelligence (AI) models can plan and carry out tasks in simulated 3D environments. These models, known as "multi-modal foundation models," are trained on a wide range of data including images, text, and even physical interactions.
The goal of MFM-ETP is to see how effectively these models can understand and execute high-level instructions in a virtual world. For example, the model might be asked to "clean up the living room" and would need to break that down into a sequence of specific actions like moving furniture, picking up objects, and putting things away. This requires the model to combine visual, linguistic, and physical reasoning skills.
The benchmark is meant to mimic the types of task planning challenges that humans face in the real world, providing a more realistic assessment of these models' capabilities compared to existing tests. Developers can use the results to identify strengths and weaknesses in their AI systems and work to improve them.
Technical Explanation
The MFM-ETP benchmark assesses the task planning abilities of multi-modal foundation models in simulated 3D environments. It builds on prior work in embodied instruction following and 3D benchmark development.
The benchmark presents models with a series of high-level instructions, such as "clean up the living room." To succeed, the model must break down the task into sequences of low-level actions, reason about the visual and physical properties of the environment, and execute those actions to complete the goal.
Evaluation metrics include task completion rate, planning efficiency, and grounded language understanding. The testbed covers a diverse range of household tasks, object interactions, and environments to provide a holistic assessment of the models' capabilities.
Critical Analysis
The MFM-ETP benchmark represents a valuable step forward in evaluating the real-world applicability of multi-modal foundation models. By focusing on embodied task planning, it goes beyond traditional language-only benchmarks and surfaces important limitations in current models.
However, the paper acknowledges that the simulated environments may still lack the complexity and uncertainty of the physical world. Additional work is needed to bridge the reality gap and ensure these models can handle the full richness of real-world task planning challenges.
Furthermore, the authors note that the benchmark primarily focuses on household tasks. Expanding the scope to include a wider range of domains, such as enterprise workflows, could yield additional important insights.
Conclusion
The MFM-ETP benchmark represents a significant advance in assessing the task planning capabilities of multi-modal foundation models. By incorporating visual, linguistic, and physical reasoning, it provides a more holistic and realistic evaluation of these models' abilities.
The results from this benchmark can help drive further progress in developing AI systems that can understand and execute complex, real-world tasks. As the field continues to evolve, benchmarks like MFM-ETP will be crucial for ensuring that multi-modal models can reliably interact with and assist humans in their daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MFE-ETP: A Comprehensive Evaluation Benchmark for Multi-modal Foundation Models on Embodied Task Planning
Min Zhang, Jianye Hao, Xian Fu, Peilong Han, Hao Zhang, Lei Shi, Hongyao Tang, Yan Zheng
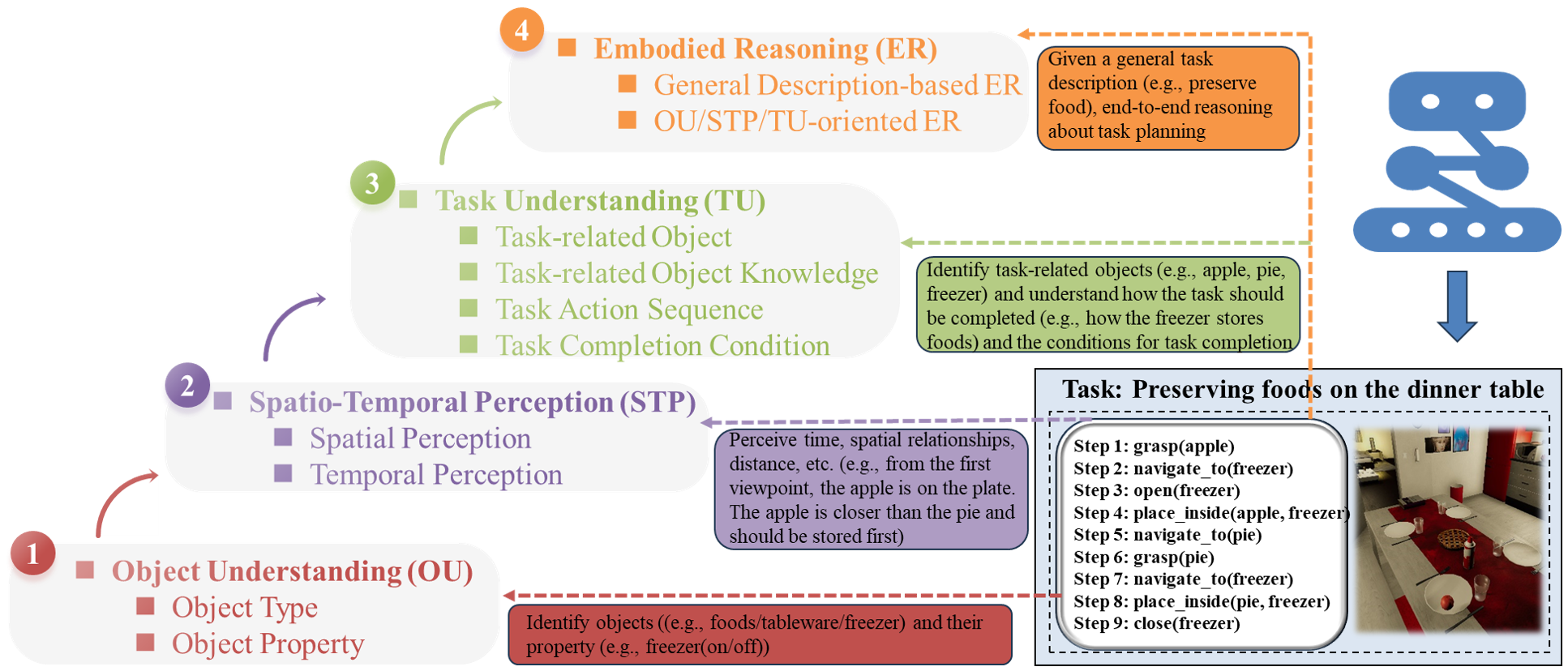
In recent years, Multi-modal Foundation Models (MFMs) and Embodied Artificial Intelligence (EAI) have been advancing side by side at an unprecedented pace. The integration of the two has garnered significant attention from the AI research community. In this work, we attempt to provide an in-depth and comprehensive evaluation of the performance of MFM s on embodied task planning, aiming to shed light on their capabilities and limitations in this domain. To this end, based on the characteristics of embodied task planning, we first develop a systematic evaluation framework, which encapsulates four crucial capabilities of MFMs: object understanding, spatio-temporal perception, task understanding, and embodied reasoning. Following this, we propose a new benchmark, named MFE-ETP, characterized its complex and variable task scenarios, typical yet diverse task types, task instances of varying difficulties, and rich test case types ranging from multiple embodied question answering to embodied task reasoning. Finally, we offer a simple and easy-to-use automatic evaluation platform that enables the automated testing of multiple MFMs on the proposed benchmark. Using the benchmark and evaluation platform, we evaluated several state-of-the-art MFMs and found that they significantly lag behind human-level performance. The MFE-ETP is a high-quality, large-scale, and challenging benchmark relevant to real-world tasks.
Read more7/31/2024
0
EFM3D: A Benchmark for Measuring Progress Towards 3D Egocentric Foundation Models
Julian Straub, Daniel DeTone, Tianwei Shen, Nan Yang, Chris Sweeney, Richard Newcombe
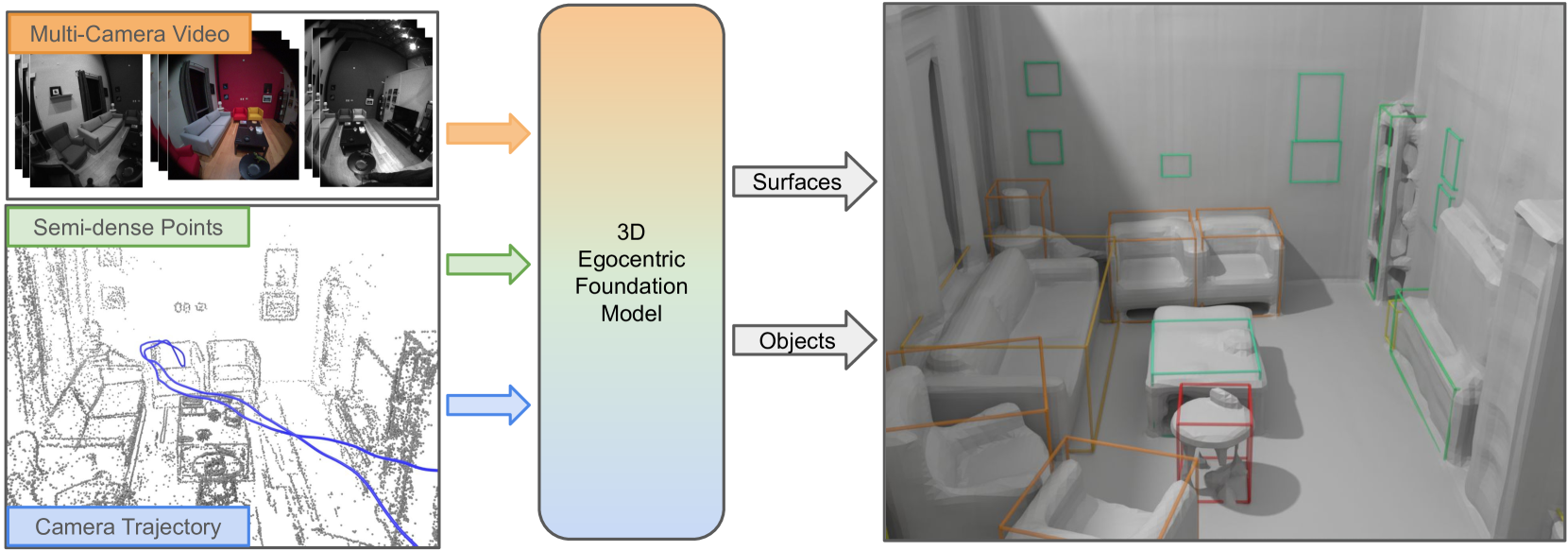
The advent of wearable computers enables a new source of context for AI that is embedded in egocentric sensor data. This new egocentric data comes equipped with fine-grained 3D location information and thus presents the opportunity for a novel class of spatial foundation models that are rooted in 3D space. To measure progress on what we term Egocentric Foundation Models (EFMs) we establish EFM3D, a benchmark with two core 3D egocentric perception tasks. EFM3D is the first benchmark for 3D object detection and surface regression on high quality annotated egocentric data of Project Aria. We propose Egocentric Voxel Lifting (EVL), a baseline for 3D EFMs. EVL leverages all available egocentric modalities and inherits foundational capabilities from 2D foundation models. This model, trained on a large simulated dataset, outperforms existing methods on the EFM3D benchmark.
Read more6/17/2024

0
Embodied Instruction Following in Unknown Environments
Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, Haibin Yan
Enabling embodied agents to complete complex human instructions from natural language is crucial to autonomous systems in household services. Conventional methods can only accomplish human instructions in the known environment where all interactive objects are provided to the embodied agent, and directly deploying the existing approaches for the unknown environment usually generates infeasible plans that manipulate non-existing objects. On the contrary, we propose an embodied instruction following (EIF) method for complex tasks in the unknown environment, where the agent efficiently explores the unknown environment to generate feasible plans with existing objects to accomplish abstract instructions. Specifically, we build a hierarchical embodied instruction following framework including the high-level task planner and the low-level exploration controller with multimodal large language models. We then construct a semantic representation map of the scene with dynamic region attention to demonstrate the known visual clues, where the goal of task planning and scene exploration is aligned for human instruction. For the task planner, we generate the feasible step-by-step plans for human goal accomplishment according to the task completion process and the known visual clues. For the exploration controller, the optimal navigation or object interaction policy is predicted based on the generated step-wise plans and the known visual clues. The experimental results demonstrate that our method can achieve 45.09% success rate in 204 complex human instructions such as making breakfast and tidying rooms in large house-level scenes.
Read more6/18/2024
0
Do Multimodal Foundation Models Understand Enterprise Workflows? A Benchmark for Business Process Management Tasks
Michael Wornow, Avanika Narayan, Ben Viggiano, Ishan S. Khare, Tathagat Verma, Tibor Thompson, Miguel Angel Fuentes Hernandez, Sudharsan Sundar, Chloe Trujillo, Krrish Chawla, Rongfei Lu, Justin Shen, Divya Nagaraj, Joshua Martinez, Vardhan Agrawal, Althea Hudson, Nigam H. Shah, Christopher Re
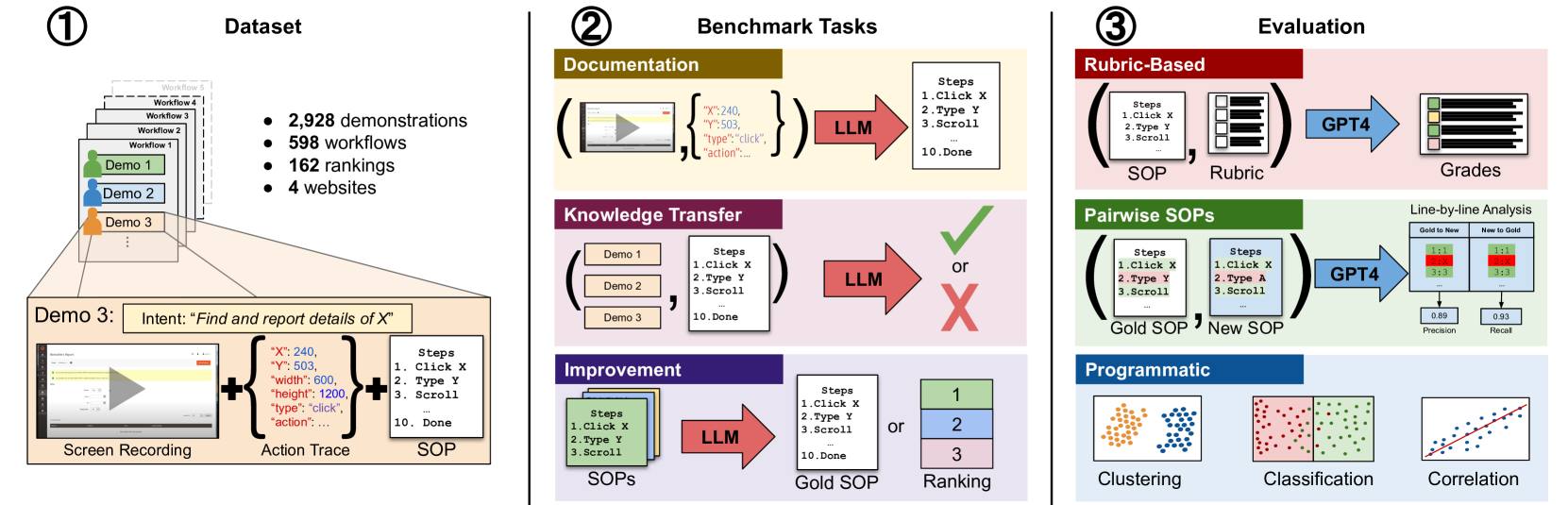
Existing ML benchmarks lack the depth and diversity of annotations needed for evaluating models on business process management (BPM) tasks. BPM is the practice of documenting, measuring, improving, and automating enterprise workflows. However, research has focused almost exclusively on one task - full end-to-end automation using agents based on multimodal foundation models (FMs) like GPT-4. This focus on automation ignores the reality of how most BPM tools are applied today - simply documenting the relevant workflow takes 60% of the time of the typical process optimization project. To address this gap we present WONDERBREAD, the first benchmark for evaluating multimodal FMs on BPM tasks beyond automation. Our contributions are: (1) a dataset containing 2928 documented workflow demonstrations; (2) 6 novel BPM tasks sourced from real-world applications ranging from workflow documentation to knowledge transfer to process improvement; and (3) an automated evaluation harness. Our benchmark shows that while state-of-the-art FMs can automatically generate documentation (e.g. recalling 88% of the steps taken in a video demonstration of a workflow), they struggle to re-apply that knowledge towards finer-grained validation of workflow completion (F1 < 0.3). We hope WONDERBREAD encourages the development of more human-centered AI tooling for enterprise applications and furthers the exploration of multimodal FMs for the broader universe of BPM tasks. We publish our dataset and experiments here: https://github.com/HazyResearch/wonderbread
Read more6/21/2024