MFSN: Multi-perspective Fusion Search Network For Pre-training Knowledge in Speech Emotion Recognition

0
Sign in to get full access
Overview
- This paper presents a new architecture called MFAS (Multiple Fusion Architecture Search) for emotion recognition from multimodal data.
- The key idea is to emulate human cognition by fusing information from multiple perspectives, including visual, audio, and textual cues.
- The authors use an automated architecture search to find the optimal fusion strategy, exploring different ways of combining the modalities.
- Experiments on benchmark emotion recognition datasets show the effectiveness of the MFAS approach compared to previous methods.
Plain English Explanation
The researchers developed a new system called MFAS for recognizing emotions from data like images, audio, and text. The core insight is that humans use information from multiple senses - sight, sound, and language - to understand emotions. So the MFAS system tries to mimic this by combining different types of data to make better emotion predictions.
Instead of manually designing how to fuse the data, the researchers used an automated search process to find the best way to bring the information together. They tried out different techniques for blending the visual, audio, and text cues and evaluated which one worked the best.
When tested on standard emotion recognition datasets, the MFAS system outperformed previous methods. This suggests that emulating human cognition by considering multiple modalities can be a powerful approach for building more accurate emotion recognition models.
Technical Explanation
The paper introduces the MFAS (Multiple Fusion Architecture Search) approach for multimodal emotion recognition. The key innovation is the use of an automated architecture search to find the optimal way to fuse information from different modalities - visual, audio, and text.
The authors argue that emotion recognition in humans involves integrating cues from multiple sensory inputs, so their MFAS system is designed to emulate this by learning to effectively combine the different modalities. They explore various fusion strategies, including concatenation, attention, and gating mechanisms, to determine the optimal way to fuse the information.
Experiments on benchmark emotion recognition datasets like IEMOCAP and EmoDB show that the MFAS approach outperforms previous state-of-the-art multimodal emotion recognition methods. This demonstrates the value of the automated architecture search in discovering effective fusion strategies that can leverage complementary information from different modalities.
Critical Analysis
The MFAS paper makes a compelling case for the benefits of fusing multiple modalities for emotion recognition, drawing inspiration from human cognition. The use of an automated architecture search is a novel and promising approach to discover optimal fusion strategies, going beyond manually-designed methods.
However, the paper does not provide detailed analysis of the specific fusion mechanisms and architectures that were explored and found to be most effective. More insight into this process would be helpful for understanding the key innovations and generalizing the approach to other multimodal tasks.
Additionally, the experiments are limited to a few standard emotion recognition datasets. It would be valuable to see how well the MFAS system generalizes to more diverse, real-world scenarios with noisier, less structured data. Potential biases or limitations of the approach should also be investigated.
Overall, the MFAS paper presents an interesting step forward in multimodal emotion recognition by drawing inspiration from human perception. Further research to build on these insights and explore the broader applicability of the architecture search technique could lead to important advances in this area.
Conclusion
The MFAS paper introduces a novel approach for multimodal emotion recognition that aims to emulate human cognition by fusing information from visual, audio, and textual cues. The key innovation is the use of an automated architecture search to discover the optimal way to combine these different modalities.
Experiments show that the MFAS system outperforms previous state-of-the-art methods on standard emotion recognition benchmarks, demonstrating the value of the multi-modal fusion strategy. This suggests that taking inspiration from how humans perceive and process emotional information can lead to more effective artificial intelligence systems.
While the paper provides a solid technical foundation, further research is needed to fully understand the specific architectural choices discovered by the search process and to evaluate the system's robustness across a wider range of real-world scenarios. Nonetheless, the MFAS work represents an intriguing step towards building AI systems that can leverage multiple sensory modalities in a human-like manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
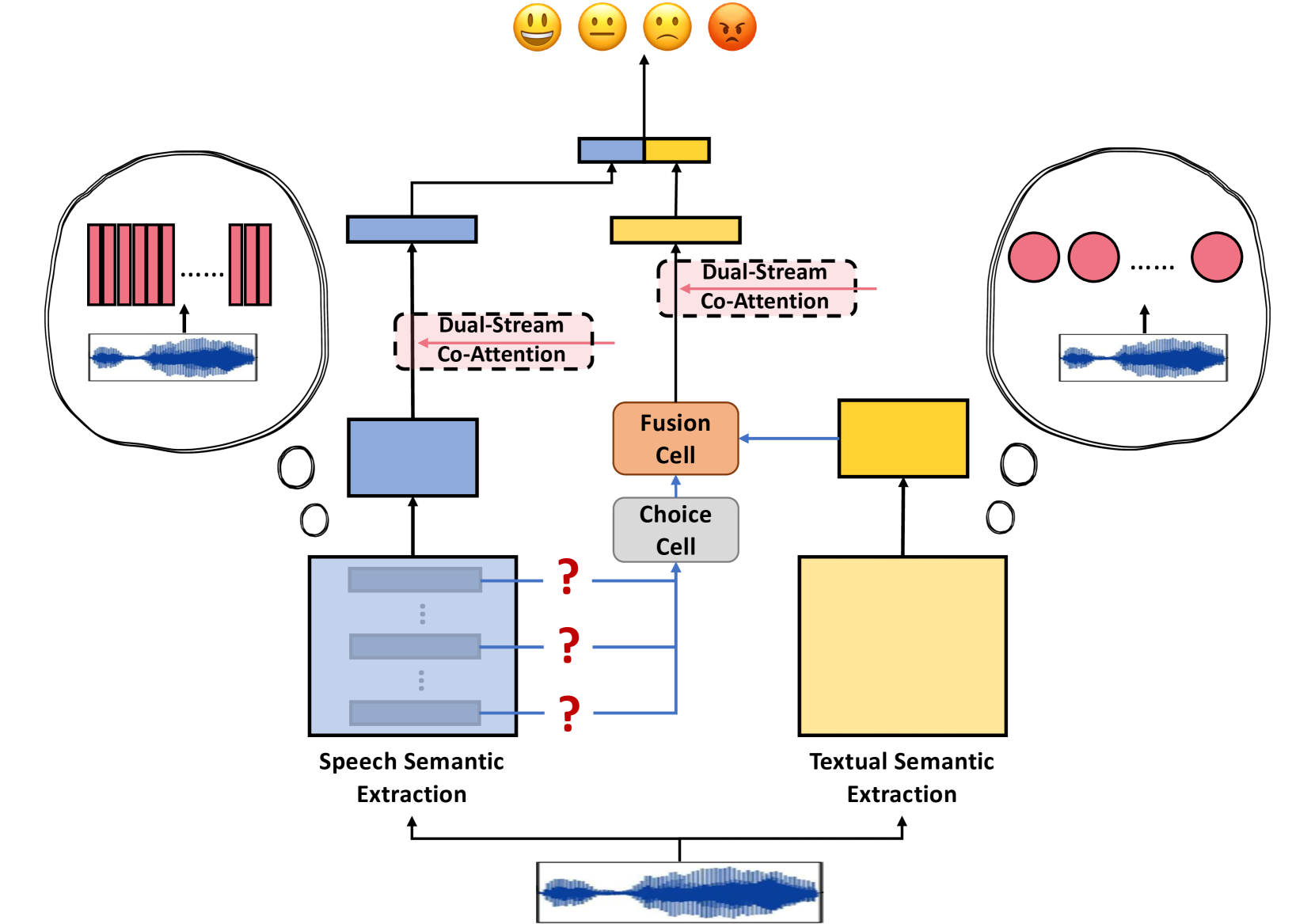
MFSN: Multi-perspective Fusion Search Network For Pre-training Knowledge in Speech Emotion Recognition
Haiyang Sun, Fulin Zhang, Yingying Gao, Zheng Lian, Shilei Zhang, Junlan Feng
Speech Emotion Recognition (SER) is an important research topic in human-computer interaction. Many recent works focus on directly extracting emotional cues through pre-trained knowledge, frequently overlooking considerations of appropriateness and comprehensiveness. Therefore, we propose a novel framework for pre-training knowledge in SER, called Multi-perspective Fusion Search Network (MFSN). Considering comprehensiveness, we partition speech knowledge into Textual-related Emotional Content (TEC) and Speech-related Emotional Content (SEC), capturing cues from both semantic and acoustic perspectives, and we design a new architecture search space to fully leverage them. Considering appropriateness, we verify the efficacy of different modeling approaches in capturing SEC and fills the gap in current research. Experimental results on multiple datasets demonstrate the superiority of MFSN.
Read more6/27/2024

0
Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
Read more6/13/2024
🌐
0
CFN-ESA: A Cross-Modal Fusion Network with Emotion-Shift Awareness for Dialogue Emotion Recognition
Jiang Li, Xiaoping Wang, Yingjian Liu, Zhigang Zeng
Multimodal emotion recognition in conversation (ERC) has garnered growing attention from research communities in various fields. In this paper, we propose a Cross-modal Fusion Network with Emotion-Shift Awareness (CFN-ESA) for ERC. Extant approaches employ each modality equally without distinguishing the amount of emotional information in these modalities, rendering it hard to adequately extract complementary information from multimodal data. To cope with this problem, in CFN-ESA, we treat textual modality as the primary source of emotional information, while visual and acoustic modalities are taken as the secondary sources. Besides, most multimodal ERC models ignore emotion-shift information and overfocus on contextual information, leading to the failure of emotion recognition under emotion-shift scenario. We elaborate an emotion-shift module to address this challenge. CFN-ESA mainly consists of unimodal encoder (RUME), cross-modal encoder (ACME), and emotion-shift module (LESM). RUME is applied to extract conversation-level contextual emotional cues while pulling together data distributions between modalities; ACME is utilized to perform multimodal interaction centered on textual modality; LESM is used to model emotion shift and capture emotion-shift information, thereby guiding the learning of the main task. Experimental results demonstrate that CFN-ESA can effectively promote performance for ERC and remarkably outperform state-of-the-art models.
Read more4/16/2024
0
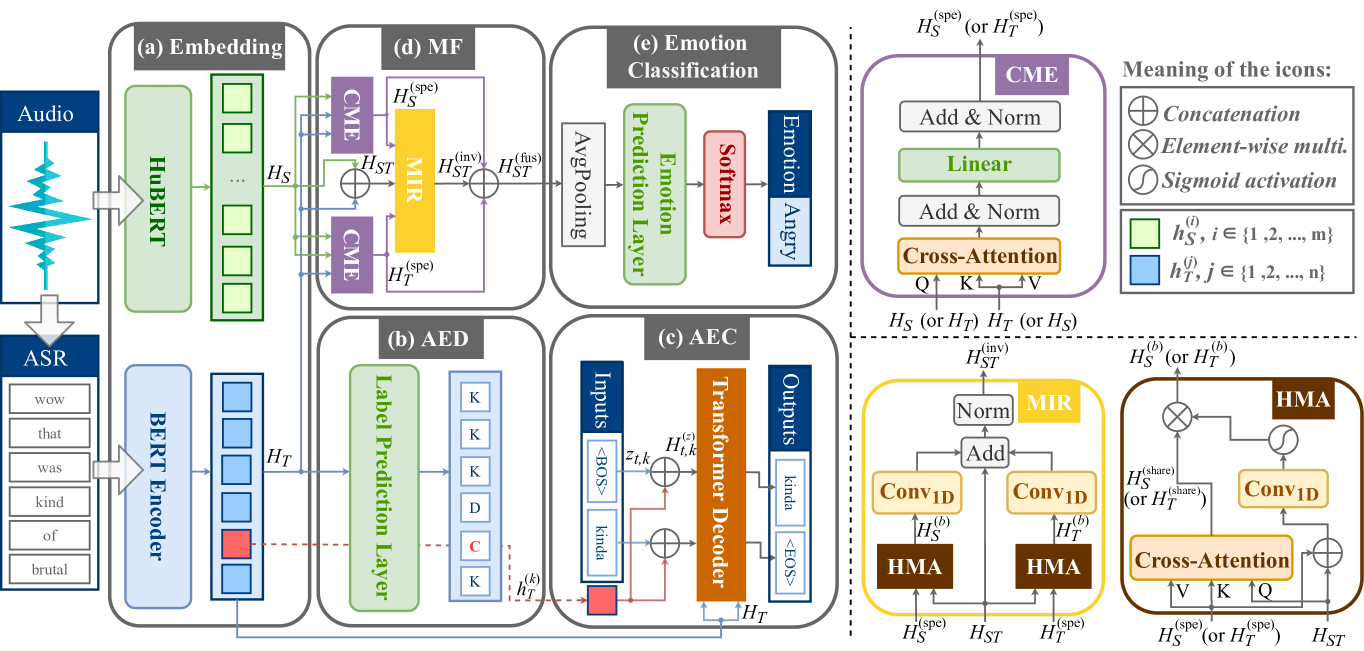
MF-AED-AEC: Speech Emotion Recognition by Leveraging Multimodal Fusion, Asr Error Detection, and Asr Error Correction
Jiajun He, Xiaohan Shi, Xingfeng Li, Tomoki Toda
The prevalent approach in speech emotion recognition (SER) involves integrating both audio and textual information to comprehensively identify the speaker's emotion, with the text generally obtained through automatic speech recognition (ASR). An essential issue of this approach is that ASR errors from the text modality can worsen the performance of SER. Previous studies have proposed using an auxiliary ASR error detection task to adaptively assign weights of each word in ASR hypotheses. However, this approach has limited improvement potential because it does not address the coherence of semantic information in the text. Additionally, the inherent heterogeneity of different modalities leads to distribution gaps between their representations, making their fusion challenging. Therefore, in this paper, we incorporate two auxiliary tasks, ASR error detection (AED) and ASR error correction (AEC), to enhance the semantic coherence of ASR text, and further introduce a novel multi-modal fusion (MF) method to learn shared representations across modalities. We refer to our method as MF-AED-AEC. Experimental results indicate that MF-AED-AEC significantly outperforms the baseline model by a margin of 4.1%.
Read more5/29/2024