MICM: Rethinking Unsupervised Pretraining for Enhanced Few-shot Learning

0

Sign in to get full access
Overview
- This paper proposes a new unsupervised pretraining approach called Masked Image Contrastive Modeling (MICM) to enhance few-shot learning.
- MICM combines masked image modeling and contrastive learning to learn robust and transferable representations from unlabeled data.
- The authors demonstrate that MICM outperforms previous few-shot learning methods on a variety of benchmarks.
Plain English Explanation
The paper introduces a new way to train [object Object] without using labeled data. This approach, called Masked Image Contrastive Modeling (MICM), combines two popular unsupervised learning techniques: masked image modeling and contrastive learning.
The key idea is to first randomly "hide" or "mask" parts of an image, and then train the model to predict the missing information. This helps the model learn useful visual features in an unsupervised way. The contrastive learning component then encourages the model to learn representations that are distinctive and transferable across different images.
The authors show that this combined approach, MICM, outperforms previous state-of-the-art methods on few-shot learning benchmarks. This means the model can quickly learn new visual concepts from just a few examples, which is an important capability for many real-world applications.
Technical Explanation
The paper proposes a new unsupervised pretraining approach called Masked Image Contrastive Modeling (MICM) to enhance few-shot learning performance. MICM combines two popular unsupervised learning techniques: masked image modeling and contrastive learning.
In the masked image modeling stage, the model is trained to predict the content of randomly masked regions in an image. This forces the model to learn useful visual features in an unsupervised way, as it needs to understand the underlying structure of the image to perform the masking task well.
The contrastive learning component then encourages the model to learn representations that are distinctive and transferable across different images. This is achieved by training the model to bring together ("contrastive") the representations of similar images while pushing apart the representations of dissimilar images.
By combining these two complementary learning signals, MICM is able to learn robust and generalizable representations that can be effectively fine-tuned for few-shot learning tasks. The authors demonstrate the effectiveness of MICM on a variety of few-shot learning benchmarks, where it outperforms previous state-of-the-art methods.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the MICM approach, testing it on multiple few-shot learning benchmarks and comparing it to strong baselines. The authors also discuss some of the limitations and potential future directions for the research.
One potential concern is the computational cost of the pretraining stage, as masked image modeling and contrastive learning can be resource-intensive. The authors mention that they used large-scale pretraining datasets, which may not be accessible to all researchers and practitioners.
Additionally, the paper does not delve into the interpretability of the learned representations or provide much insight into the specific features that MICM learns. Further analysis in this direction could shed light on the inner workings of the model and help identify potential biases or limitations.
Overall, the paper presents a promising approach to enhancing few-shot learning through unsupervised pretraining, and the results demonstrate the potential of combining different self-supervised learning techniques. However, as with any research, there are opportunities for further exploration and refinement.
Conclusion
This paper introduces Masked Image Contrastive Modeling (MICM), a novel unsupervised pretraining approach that combines masked image modeling and contrastive learning to learn robust and transferable visual representations. The authors show that this combined approach outperforms previous state-of-the-art methods on a variety of few-shot learning benchmarks.
The key contribution of this work is demonstrating the power of integrating complementary self-supervised learning signals to enhance the few-shot learning capabilities of vision models. This has important implications for developing more sample-efficient and adaptable AI systems that can quickly learn new concepts from limited data, a crucial capability for many real-world applications.
While the paper provides a strong technical foundation, there are opportunities for further research to address limitations around computational cost and interpretability. Overall, the MICM approach represents an exciting step forward in the field of unsupervised pretraining for enhanced few-shot learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MICM: Rethinking Unsupervised Pretraining for Enhanced Few-shot Learning
Zhenyu Zhang, Guangyao Chen, Yixiong Zou, Zhimeng Huang, Yuhua Li, Ruixuan Li
Humans exhibit a remarkable ability to learn quickly from a limited number of labeled samples, a capability that starkly contrasts with that of current machine learning systems. Unsupervised Few-Shot Learning (U-FSL) seeks to bridge this divide by reducing reliance on annotated datasets during initial training phases. In this work, we first quantitatively assess the impacts of Masked Image Modeling (MIM) and Contrastive Learning (CL) on few-shot learning tasks. Our findings highlight the respective limitations of MIM and CL in terms of discriminative and generalization abilities, which contribute to their underperformance in U-FSL contexts. To address these trade-offs between generalization and discriminability in unsupervised pretraining, we introduce a novel paradigm named Masked Image Contrastive Modeling (MICM). MICM creatively combines the targeted object learning strength of CL with the generalized visual feature learning capability of MIM, significantly enhancing its efficacy in downstream few-shot learning inference. Extensive experimental analyses confirm the advantages of MICM, demonstrating significant improvements in both generalization and discrimination capabilities for few-shot learning. Our comprehensive quantitative evaluations further substantiate the superiority of MICM, showing that our two-stage U-FSL framework based on MICM markedly outperforms existing leading baselines.
Read more8/27/2024

0
Learning the Unlearned: Mitigating Feature Suppression in Contrastive Learning
Jihai Zhang, Xiang Lan, Xiaoye Qu, Yu Cheng, Mengling Feng, Bryan Hooi
Self-Supervised Contrastive Learning has proven effective in deriving high-quality representations from unlabeled data. However, a major challenge that hinders both unimodal and multimodal contrastive learning is feature suppression, a phenomenon where the trained model captures only a limited portion of the information from the input data while overlooking other potentially valuable content. This issue often leads to indistinguishable representations for visually similar but semantically different inputs, adversely affecting downstream task performance, particularly those requiring rigorous semantic comprehension. To address this challenge, we propose a novel model-agnostic Multistage Contrastive Learning (MCL) framework. Unlike standard contrastive learning which inherently captures one single biased feature distribution, MCL progressively learns previously unlearned features through feature-aware negative sampling at each stage, where the negative samples of an anchor are exclusively selected from the cluster it was assigned to in preceding stages. Meanwhile, MCL preserves the previously well-learned features by cross-stage representation integration, integrating features across all stages to form final representations. Our comprehensive evaluation demonstrates MCL's effectiveness and superiority across both unimodal and multimodal contrastive learning, spanning a range of model architectures from ResNet to Vision Transformers (ViT). Remarkably, in tasks where the original CLIP model has shown limitations, MCL dramatically enhances performance, with improvements up to threefold on specific attributes in the recently proposed MMVP benchmark.
Read more7/16/2024
43
Many-Shot In-Context Learning
Rishabh Agarwal, Avi Singh, Lei M. Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, John D. Co-Reyes, Eric Chu, Feryal Behbahani, Aleksandra Faust, Hugo Larochelle
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
Read more5/24/2024
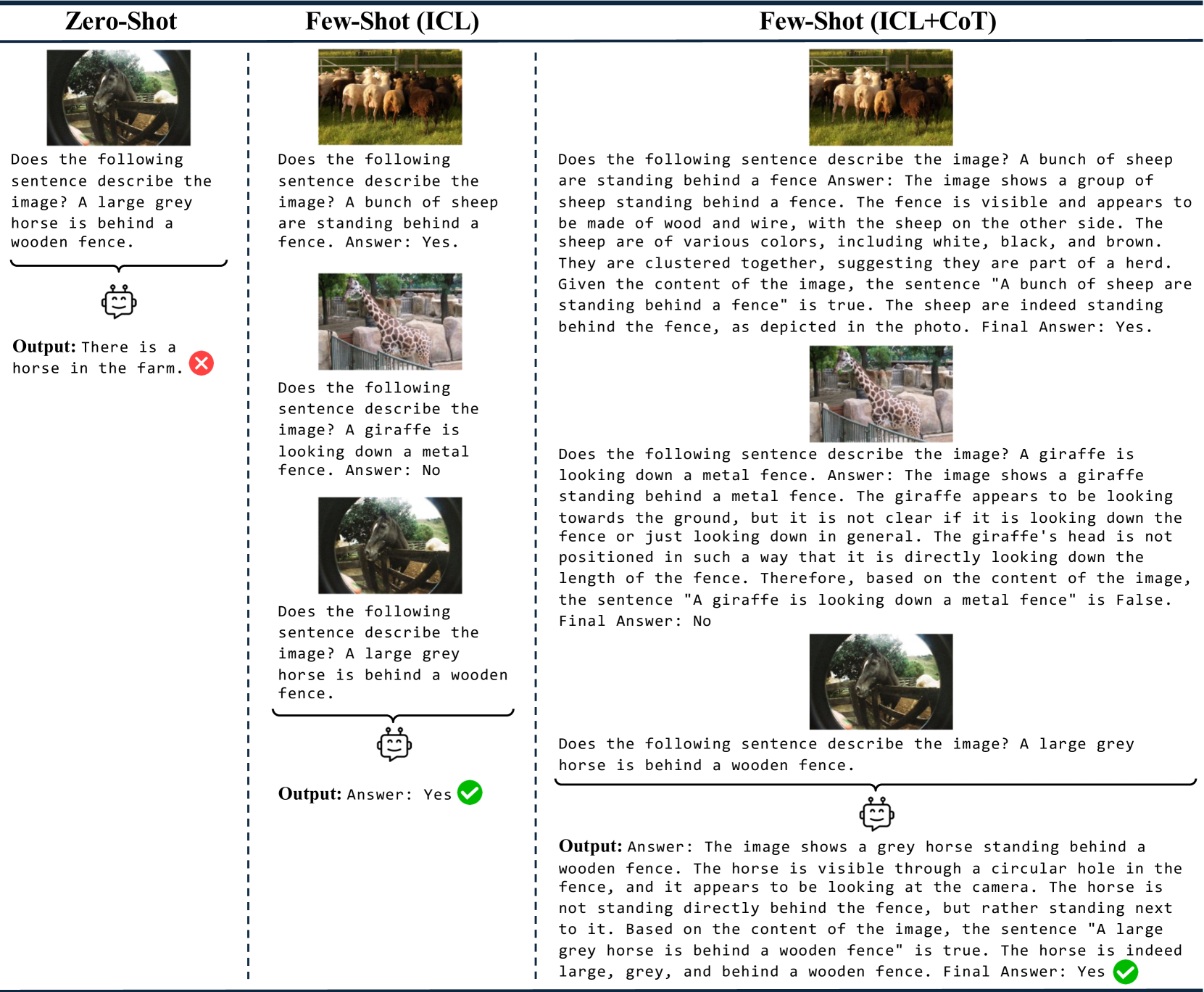
0
Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning
Mustafa Dogan, Ilker Kesen, Iacer Calixto, Aykut Erdem, Erkut Erdem
The linguistic capabilities of Multimodal Large Language Models (MLLMs) are critical for their effective application across diverse tasks. This study aims to evaluate the performance of MLLMs on the VALSE benchmark, focusing on the efficacy of few-shot In-Context Learning (ICL), and Chain-of-Thought (CoT) prompting. We conducted a comprehensive assessment of state-of-the-art MLLMs, varying in model size and pretraining datasets. The experimental results reveal that ICL and CoT prompting significantly boost model performance, particularly in tasks requiring complex reasoning and contextual understanding. Models pretrained on captioning datasets show superior zero-shot performance, while those trained on interleaved image-text data benefit from few-shot learning. Our findings provide valuable insights into optimizing MLLMs for better grounding of language in visual contexts, highlighting the importance of the composition of pretraining data and the potential of few-shot learning strategies to improve the reasoning abilities of MLLMs.
Read more7/18/2024