MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis

0
Sign in to get full access
Overview
- The paper introduces MindBench, a comprehensive benchmark for evaluating mind map structure recognition and analysis models.
- Mind maps are visual tools that help organize information and ideas in a hierarchical, node-based structure.
- MindBench provides a diverse dataset of real-world mind maps, along with a set of tasks and metrics to assess the performance of models in this domain.
Plain English Explanation
Mind maps are a popular way of visually organizing information and ideas. They use a branching, node-based structure to represent concepts and their relationships. Imagine a central topic in the middle, with connected sub-topics, and those sub-topics having their own sub-topics, and so on. This visual format can help people understand and remember information more effectively.
The researchers who created the MindBench benchmark recognized that while mind maps are widely used, there hasn't been a comprehensive way to evaluate the performance of AI models in recognizing and analyzing the structure of these mind maps. That's where MindBench comes in.
MindBench provides a large, diverse dataset of real-world mind maps, along with a set of tasks and evaluation metrics to assess how well AI models can understand the hierarchical structure and content of these mind maps. This allows researchers and developers to thoroughly test their models and compare their performance to others.
By having a standardized benchmark like MindBench, the field of mind map analysis can progress more rapidly, as researchers will be able to build on each other's work and identify the most promising approaches.
Technical Explanation
The MindBench dataset consists of over 10,000 mind maps collected from various online sources. These mind maps cover a wide range of topics, such as business planning, education, and personal development. The dataset includes both the visual representation of the mind maps as well as the textual content associated with each node.
The paper defines several key tasks for evaluating mind map understanding, including node classification (identifying the type of each node), edge classification (recognizing the relationships between nodes), and structure reconstruction (generating a hierarchical representation of the mind map). The researchers also propose a set of evaluation metrics, such as accuracy, F1-score, and structural similarity, to assess model performance on these tasks.
The authors benchmark several state-of-the-art models, including transformer-based architectures and graph neural networks, on the MindBench dataset. Their results show that while existing models can achieve reasonable performance, there is still significant room for improvement, particularly in capturing the complex, hierarchical structure of mind maps.
Critical Analysis
The MindBench benchmark is a valuable contribution to the field of mind map understanding, as it provides a standardized way to evaluate the performance of AI models in this domain. However, the paper acknowledges several limitations of the current dataset and tasks.
For example, the mind maps in the dataset are mostly static images, which may not capture the full dynamic and interactive nature of real-world mind mapping tools. Additionally, the dataset is predominantly in English, which may limit its applicability to mind maps in other languages.
The paper also suggests that future work could explore more advanced tasks, such as generating or summarizing mind maps from text, or leveraging the temporal evolution of mind maps over time. Incorporating these elements could lead to more comprehensive and realistic benchmarks for mind map understanding.
As with any benchmark, it will be important for the research community to continue updating and expanding the MindBench dataset and tasks to keep pace with the rapid advancements in AI and mind mapping technologies.
Conclusion
The MindBench benchmark represents an important step forward in the field of mind map structure recognition and analysis. By providing a standardized dataset and evaluation framework, the benchmark enables researchers and developers to systematically assess the performance of their models and drive progress in this area.
As mind maps become increasingly prevalent in various domains, from education to business, the ability to automatically understand and manipulate these visual representations of knowledge can have significant practical implications. The MindBench benchmark lays the groundwork for further advancements in this direction, ultimately leading to more powerful and versatile tools for organizing, sharing, and leveraging information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis
Lei Chen, Feng Yan, Yujie Zhong, Shaoxiang Chen, Zequn Jie, Lin Ma
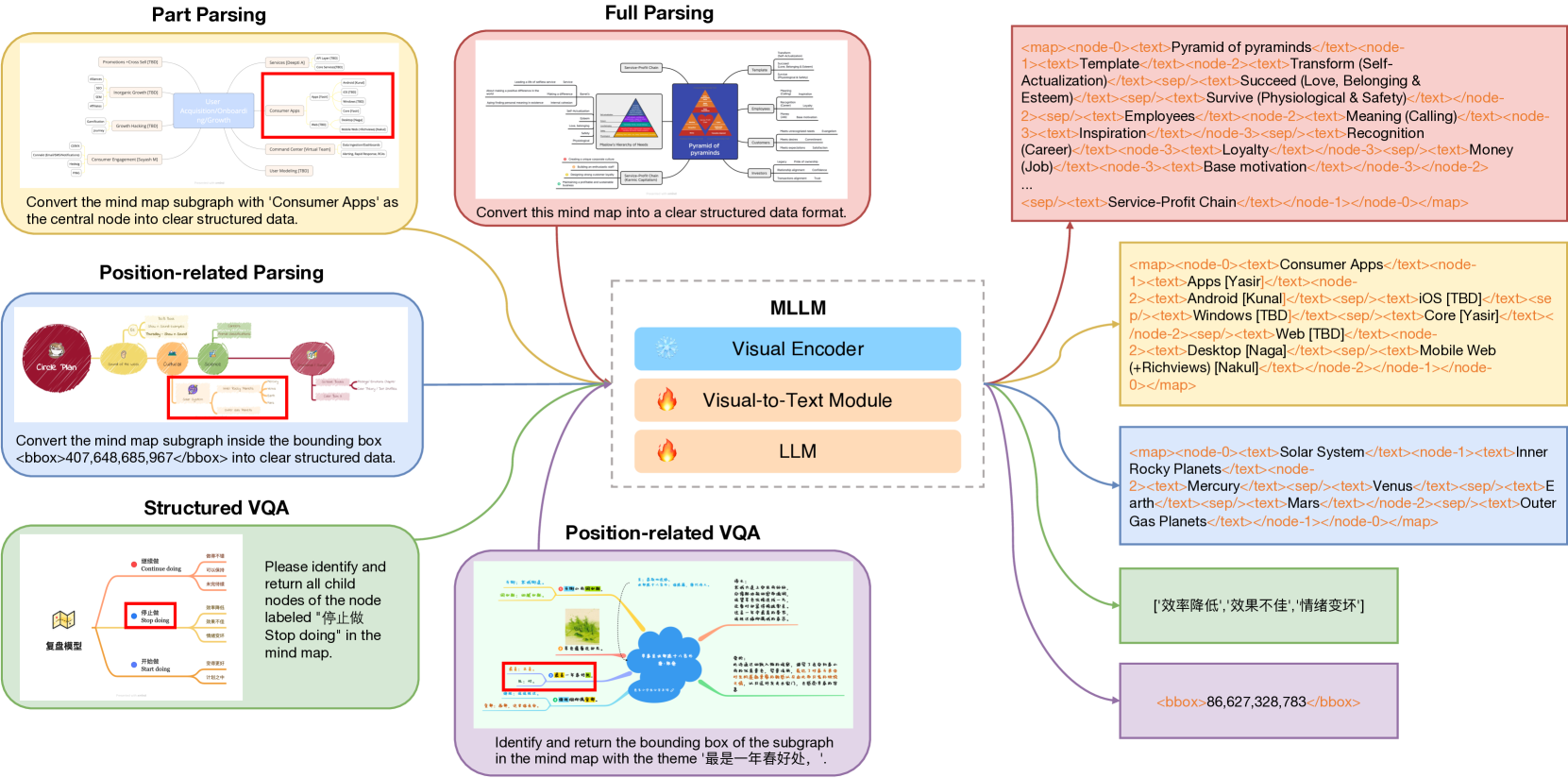
Multimodal Large Language Models (MLLM) have made significant progress in the field of document analysis. Despite this, existing benchmarks typically focus only on extracting text and simple layout information, neglecting the complex interactions between elements in structured documents such as mind maps and flowcharts. To address this issue, we introduce the new benchmark named MindBench, which not only includes meticulously constructed bilingual authentic or synthetic images, detailed annotations, evaluation metrics and baseline models, but also specifically designs five types of structured understanding and parsing tasks. These tasks include full parsing, partial parsing, position-related parsing, structured Visual Question Answering (VQA), and position-related VQA, covering key areas such as text recognition, spatial awareness, relationship discernment, and structured parsing. Extensive experimental results demonstrate the substantial potential and significant room for improvement in current models' ability to handle structured document information. We anticipate that the launch of MindBench will significantly advance research and application development in structured document analysis technology. MindBench is available at: https://miasanlei.github.io/MindBench.github.io/.
Read more7/4/2024

0
StructBench: An Autogenerated Benchmark for Evaluating Large Language Model's Ability in Structure-Rich Text Understanding
Zhouhong Gu, Haoning Ye, Zeyang Zhou, Hongwei Feng, Yanghua Xiao
Given the substantial volumes of structured data held by many companies, enabling Large Language Models (LLMs) to directly understand structured text in non-structured forms could significantly enhance their capabilities across various business scenarios. To this end, we propose evaluation data generation method for assessing LLM's ability in understanding the structure-rich text, which generates structured data of controllable complexity based on manually crafted question templates and generation rules. Building on this generation method, we introduce StrucText-Eval, a benchmark comprising 6,032 questions across 8 different structured languages and 29 specific tasks. Furthermore, considering human proficiency in rule-based tasks, we also present StrucText-Eval-Hard, which includes 3,016 questions designed to further examine the gap between LLMs and human performance. Results indicate that the best-performing LLM currently achieve an accuracy of 65.0% on StrucText-Eval-Hard, while human accuracy reaches up to 95.7%. Moreover, while fine-tuning using StrucText-Eval can enhance existing LLMs' understanding of all structured languages, it does not necessarily improve performance across all task types. The benchmark and generation codes are open sourced in https://github.com/MikeGu721/StrucText-Eval
Read more7/2/2024

0
Structsum Generation for Faster Text Comprehension
Parag Jain, Andreea Marzoca, Francesco Piccinno
We consider the task of generating structured representations of text using large language models (LLMs). We focus on tables and mind maps as representative modalities. Tables are more organized way of representing data, while mind maps provide a visually dynamic and flexible approach, particularly suitable for sparse content. Despite the effectiveness of LLMs on different tasks, we show that current models struggle with generating structured outputs. In response, we present effective prompting strategies for both of these tasks. We introduce a taxonomy of problems around factuality, global and local structure, common to both modalities and propose a set of critiques to tackle these issues resulting in an absolute improvement in accuracy of +37pp (79%) for mind maps and +15pp (78%) for tables. To evaluate semantic coverage of generated structured representations we propose Auto-QA, and we verify the adequacy of Auto-QA using SQuAD dataset. We further evaluate the usefulness of structured representations via a text comprehension user study. The results show a significant reduction in comprehension time compared to text when using table (42.9%) and mind map (31.9%), without loss in accuracy.
Read more6/21/2024
🤯
0
ChartBench: A Benchmark for Complex Visual Reasoning in Charts
Zhengzhuo Xu, Sinan Du, Yiyan Qi, Chengjin Xu, Chun Yuan, Jian Guo
Multimodal Large Language Models (MLLMs) have shown impressive capabilities in image understanding and generation. However, current benchmarks fail to accurately evaluate the chart comprehension of MLLMs due to limited chart types and inappropriate metrics. To address this, we propose ChartBench, a comprehensive benchmark designed to assess chart comprehension and data reliability through complex visual reasoning. ChartBench includes 42 categories, 66.6k charts, and 600k question-answer pairs. Notably, many charts lack data point annotations, which requires MLLMs to derive values similar to human understanding by leveraging inherent chart elements such as color, legends, and coordinate systems. We also design an enhanced evaluation metric, Acc+, to evaluate MLLMs without extensive manual or costly LLM-based evaluations. Furthermore, we propose two baselines based on the chain of thought and supervised fine-tuning to improve model performance on unannotated charts. Extensive experimental evaluations of 18 open-sourced and 3 proprietary MLLMs reveal their limitations in chart comprehension and offer valuable insights for further research. Code and dataset are publicly available at https://chartbench.github.io.
Read more6/21/2024