StructBench: An Autogenerated Benchmark for Evaluating Large Language Model's Ability in Structure-Rich Text Understanding

0

Sign in to get full access
Overview
- This paper introduces StructBench, a new benchmark for evaluating large language models' (LLMs) ability to understand structure-rich text.
- StructBench is an autogenerated benchmark consisting of a diverse set of tasks that assess an LLM's skills in areas like logical reasoning, numerical reasoning, and understanding structured data.
- The paper compares the performance of various LLMs on StructBench, providing insights into their strengths and weaknesses in structure-rich text understanding.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have achieved impressive results on a wide range of natural language processing tasks. However, their ability to understand and reason about structured information, such as tables, lists, and logical relationships, is less well-studied.
The researchers behind this paper have developed a new benchmark called StructBench to address this gap. StructBench is a collection of diverse tasks that test an LLM's skills in areas like logical reasoning, numerical reasoning, and understanding structured data. These tasks are automatically generated, ensuring a wide range of examples and preventing models from simply memorizing solutions.
By evaluating the performance of different LLMs on StructBench, the researchers aim to gain insights into the strengths and weaknesses of these models when it comes to understanding structure-rich text. This information can help guide the development of more advanced LLMs that can better handle the complexities of real-world, structure-rich data.
Technical Explanation
The StructBench paper introduces a new benchmark for evaluating large language models' (LLMs) ability to understand structure-rich text. This benchmark, called StructBench, consists of a diverse set of automatically generated tasks that assess an LLM's skills in areas like logical reasoning, numerical reasoning, and understanding structured data.
The tasks in StructBench are designed to be challenging for current LLMs, which tend to excel at natural language processing but struggle with structure-rich text understanding. The researchers use a template-based approach to generate a large number of unique examples for each task, preventing models from simply memorizing solutions.
The paper presents the results of evaluating several popular LLMs, including GPT-3, BERT, and T5, on the StructBench tasks. The findings suggest that while these models perform well on many natural language processing benchmarks, they still have significant room for improvement when it comes to structure-rich text understanding.
The researchers also introduce a new LLM architecture called StructLM, which is designed to better handle structure-rich text by incorporating specialized modules for tasks like logical reasoning and numerical reasoning. StructLM outperforms the other LLMs on the StructBench tasks, demonstrating the potential benefits of incorporating structured reasoning capabilities into language models.
Overall, the StructBench paper provides a valuable contribution to the field of natural language processing by highlighting the limitations of current LLMs in structure-rich text understanding and proposing new approaches to address this challenge.
Critical Analysis
The StructBench paper makes a valuable contribution to the field of natural language processing by introducing a new benchmark for evaluating LLMs' ability to understand structure-rich text. However, the paper also acknowledges some limitations and areas for further research.
One potential limitation is the specific tasks included in the StructBench benchmark. While the researchers have made efforts to ensure a diverse set of examples, it's possible that the tasks may not fully capture the nuances of real-world structure-rich text understanding. As the authors suggest, it would be valuable to explore how well the models perform on tasks derived from actual documents, such as scientific papers or legal contracts.
Additionally, the paper focuses on evaluating the performance of existing LLM architectures, but it does not delve deeply into the underlying reasons for their strengths and weaknesses. Further research could investigate the specific model components or training approaches that contribute to better structure-rich text understanding, which could inform the development of even more advanced LLMs.
Another area for potential exploration is the generalization of the StructBench benchmark across different languages and cultural contexts. The current version of the benchmark is focused on English, but it would be interesting to see how well the tasks and findings translate to other languages, where the structure and logic of text may differ.
Overall, the StructBench paper represents an important step forward in the assessment of LLMs' capabilities, and the insights it provides can help drive the development of more versatile and structure-aware language models in the future.
Conclusion
The StructBench paper introduces a new benchmark for evaluating the structure-rich text understanding capabilities of large language models (LLMs). The benchmark, called StructBench, consists of a diverse set of automatically generated tasks that assess an LLM's skills in areas like logical reasoning, numerical reasoning, and understanding structured data.
By comparing the performance of various LLMs on StructBench, the researchers have uncovered important insights into the strengths and weaknesses of these models when it comes to structure-rich text understanding. The findings suggest that while current LLMs excel at many natural language processing tasks, they still have significant room for improvement in this critical area.
The introduction of the StructBench benchmark and the exploration of specialized architectures like StructLM represent important steps towards building more versatile and structure-aware language models. As the field of natural language processing continues to evolve, benchmarks like StructBench will play a crucial role in guiding the development of advanced AI systems that can better handle the complexities of real-world, structure-rich data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
StructBench: An Autogenerated Benchmark for Evaluating Large Language Model's Ability in Structure-Rich Text Understanding
Zhouhong Gu, Haoning Ye, Zeyang Zhou, Hongwei Feng, Yanghua Xiao
Given the substantial volumes of structured data held by many companies, enabling Large Language Models (LLMs) to directly understand structured text in non-structured forms could significantly enhance their capabilities across various business scenarios. To this end, we propose evaluation data generation method for assessing LLM's ability in understanding the structure-rich text, which generates structured data of controllable complexity based on manually crafted question templates and generation rules. Building on this generation method, we introduce StrucText-Eval, a benchmark comprising 6,032 questions across 8 different structured languages and 29 specific tasks. Furthermore, considering human proficiency in rule-based tasks, we also present StrucText-Eval-Hard, which includes 3,016 questions designed to further examine the gap between LLMs and human performance. Results indicate that the best-performing LLM currently achieve an accuracy of 65.0% on StrucText-Eval-Hard, while human accuracy reaches up to 95.7%. Moreover, while fine-tuning using StrucText-Eval can enhance existing LLMs' understanding of all structured languages, it does not necessarily improve performance across all task types. The benchmark and generation codes are open sourced in https://github.com/MikeGu721/StrucText-Eval
Read more7/2/2024
💬
0
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?
Xiangru Tang, Yiming Zong, Jason Phang, Yilun Zhao, Wangchunshu Zhou, Arman Cohan, Mark Gerstein
Despite the remarkable capabilities of Large Language Models (LLMs) like GPT-4, producing complex, structured tabular data remains challenging. Our study assesses LLMs' proficiency in structuring tables and introduces a novel fine-tuning method, cognizant of data structures, to bolster their performance. We unveil Struc-Bench, a comprehensive benchmark featuring prominent LLMs (GPT-NeoX-20B, GPT-3.5, GPT-4, and Vicuna), which spans text tables, HTML, and LaTeX formats. Our proposed FormatCoT aids in crafting format-specific instructions from the intended outputs to populate this benchmark. Addressing the gap in task-centered evaluation, we propose two innovative metrics, P-Score (Prompting Score) and H-Score (Heuristical Score), to more accurately gauge LLM performance. Our experiments show that applying our structure-aware fine-tuning to LLaMA-7B leads to substantial performance gains, outshining its LLM counterparts across most measures. In-depth error analysis and creating an ability map across six dimensions -- coverage, formatting, reasoning, comprehension, pragmatics, and hallucination -- highlight areas for future enhancements and suggest forthcoming research trajectories. Our code and models can be found at https://github.com/gersteinlab/Struc-Bench.
Read more4/8/2024

0
StructEval: Deepen and Broaden Large Language Model Assessment via Structured Evaluation
Boxi Cao, Mengjie Ren, Hongyu Lin, Xianpei Han, Feng Zhang, Junfeng Zhan, Le Sun
Evaluation is the baton for the development of large language models. Current evaluations typically employ a single-item assessment paradigm for each atomic test objective, which struggles to discern whether a model genuinely possesses the required capabilities or merely memorizes/guesses the answers to specific questions. To this end, we propose a novel evaluation framework referred to as StructEval. Starting from an atomic test objective, StructEval deepens and broadens the evaluation by conducting a structured assessment across multiple cognitive levels and critical concepts, and therefore offers a comprehensive, robust and consistent evaluation for LLMs. Experiments on three widely-used benchmarks demonstrate that StructEval serves as a reliable tool for resisting the risk of data contamination and reducing the interference of potential biases, thereby providing more reliable and consistent conclusions regarding model capabilities. Our framework also sheds light on the design of future principled and trustworthy LLM evaluation protocols.
Read more8/9/2024
0
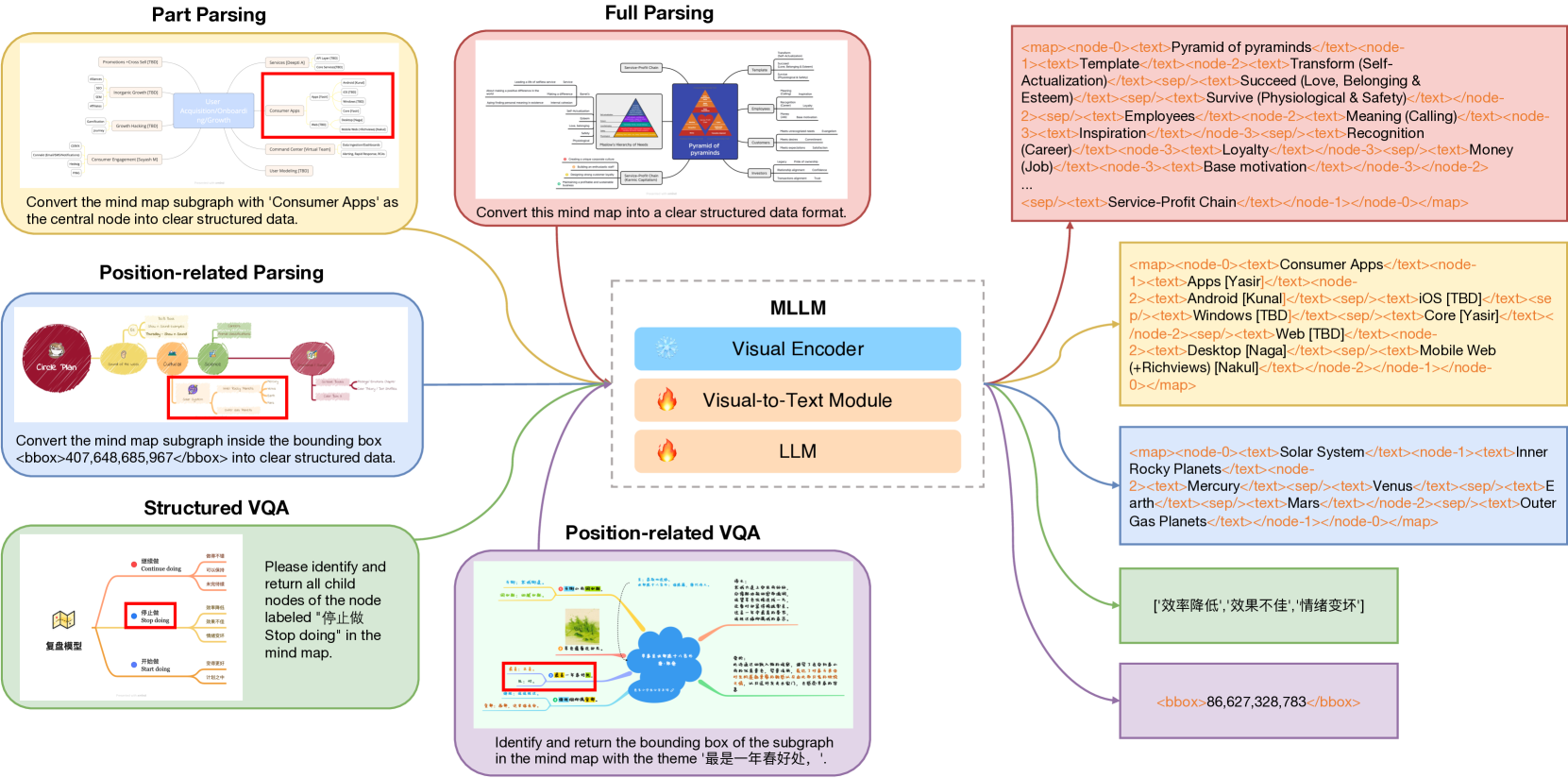
MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis
Lei Chen, Feng Yan, Yujie Zhong, Shaoxiang Chen, Zequn Jie, Lin Ma
Multimodal Large Language Models (MLLM) have made significant progress in the field of document analysis. Despite this, existing benchmarks typically focus only on extracting text and simple layout information, neglecting the complex interactions between elements in structured documents such as mind maps and flowcharts. To address this issue, we introduce the new benchmark named MindBench, which not only includes meticulously constructed bilingual authentic or synthetic images, detailed annotations, evaluation metrics and baseline models, but also specifically designs five types of structured understanding and parsing tasks. These tasks include full parsing, partial parsing, position-related parsing, structured Visual Question Answering (VQA), and position-related VQA, covering key areas such as text recognition, spatial awareness, relationship discernment, and structured parsing. Extensive experimental results demonstrate the substantial potential and significant room for improvement in current models' ability to handle structured document information. We anticipate that the launch of MindBench will significantly advance research and application development in structured document analysis technology. MindBench is available at: https://miasanlei.github.io/MindBench.github.io/.
Read more7/4/2024