Minimal Interaction Edge Tuning: A New Paradigm for Visual Adaptation

0

Sign in to get full access
Overview
- This paper introduces a new approach called "Minimal Interaction Edge Tuning" for visually adapting machine learning models with minimal user interaction.
- The key idea is to fine-tune the edge features of a pre-trained model, rather than the entire model, to adapt it to a new task or domain.
- This can enable more efficient and effective visual adaptation compared to traditional fine-tuning approaches.
Plain English Explanation
Machine learning models, especially for computer vision tasks, are often pre-trained on large datasets like ImageNet to learn general visual features. However, when applying these models to new tasks or domains, their performance may not be optimal. Traditionally, researchers have fine-tuned the entire model on the new data, which can be computationally expensive and require a lot of data.
The "Minimal Interaction Edge Tuning" approach proposed in this paper offers a more efficient alternative. Instead of fine-tuning the entire model, the researchers focus on fine-tuning just the edge features - the low-level visual features that detect edges, lines, and other basic shapes. This requires much less data and computational resources, while still allowing the model to adapt to the new task or domain.
The key insight is that the higher-level features learned by the model during pre-training are often quite general and transferable, so they don't need to be extensively fine-tuned. By only tuning the edge features, the model can capture the unique visual characteristics of the new task or domain while preserving the general visual knowledge learned during pre-training.
This approach can be particularly useful for adapting large multimodal models to new visual domains, or for fine-tuning vision transformers in a more efficient and hierarchical way. It can also help enable more robust and efficient cloud-edge elastic model deployment.
Technical Explanation
The paper introduces a new approach called "Minimal Interaction Edge Tuning" (MIET) for visually adapting machine learning models. The key idea is to fine-tune only the edge features of a pre-trained model, rather than the entire model, to adapt it to a new task or domain.
The researchers start with a pre-trained model, such as a convolutional neural network (CNN) or a vision transformer (ViT), that has been trained on a large dataset like ImageNet. They then freeze all the layers of the model except for the early convolutional layers that capture low-level edge features.
Only these edge feature layers are fine-tuned on the new task or domain data, while the rest of the model remains fixed. This allows the model to adapt to the unique visual characteristics of the new data while preserving the general visual knowledge learned during pre-training.
The researchers evaluate MIET on several computer vision tasks, including image classification, object detection, and semantic segmentation. They show that MIET can achieve comparable or better performance than traditional fine-tuning approaches, while using significantly less data and computational resources.
The key advantage of MIET is that it enables more efficient and effective visual adaptation by focusing the fine-tuning process on the most relevant parts of the model. This can be particularly useful for adapting large multimodal models to new visual domains, fine-tuning vision transformers in a more hierarchical way, and enabling more robust and efficient cloud-edge elastic model deployment.
Critical Analysis
The "Minimal Interaction Edge Tuning" approach proposed in this paper offers a promising new paradigm for visual adaptation of machine learning models. By focusing the fine-tuning process on the edge features of the model, the researchers demonstrate that it is possible to achieve comparable or better performance than traditional fine-tuning, while using significantly less data and computational resources.
One potential limitation of the MIET approach is that it may not be as effective for tasks or domains that require more significant changes to the higher-level features of the model. The researchers acknowledge this and suggest that MIET could be combined with other fine-tuning techniques, such as hierarchical side-tuning, to address this issue.
Another area for further research could be exploring the optimal depth and number of edge feature layers to fine-tune, as this may vary depending on the task, domain, and pre-trained model architecture. The researchers provide some guidance on this, but more systematic exploration could yield additional insights.
Overall, the "Minimal Interaction Edge Tuning" approach represents an important step forward in the field of visual adaptation, offering a more efficient and effective alternative to traditional fine-tuning techniques. As machine learning models continue to grow in size and complexity, approaches like MIET will become increasingly crucial for enabling robust and efficient cloud-edge elastic model deployment.
Conclusion
The "Minimal Interaction Edge Tuning" (MIET) approach introduced in this paper offers a new paradigm for visually adapting machine learning models with minimal user interaction. By fine-tuning only the edge features of a pre-trained model, rather than the entire model, MIET can achieve comparable or better performance than traditional fine-tuning approaches while using significantly less data and computational resources.
This efficient and effective visual adaptation technique can have important implications for a variety of computer vision applications, from adapting large multimodal models to new domains to fine-tuning vision transformers in a more hierarchical way. As the demand for robust and efficient machine learning models continues to grow, especially in the context of cloud-edge elastic deployment, the MIET approach represents an important step forward in the field of visual adaptation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Minimal Interaction Edge Tuning: A New Paradigm for Visual Adaptation
Ningyuan Tang, Minghao Fu, Jianxin Wu
The rapid scaling of large vision pretrained models makes fine-tuning tasks more and more difficult on edge devices with low computational resources. We explore a new visual adaptation paradigm called edge tuning, which treats large pretrained models as standalone feature extractors that run on powerful cloud servers. The fine-tuning carries out on edge devices with small networks which require low computational resources. Existing methods that are potentially suitable for our edge tuning paradigm are discussed. But, three major drawbacks hinder their application in edge tuning: low adaptation capability, large adapter network, and high information transfer overhead. To address these issues, we propose Minimal Interaction Edge Tuning, or MIET, which reveals that the sum of intermediate features from pretrained models not only has minimal information transfer but also has high adaptation capability. With a lightweight attention-based adaptor network, MIET achieves information transfer efficiency, parameter efficiency, computational and memory efficiency, and at the same time demonstrates competitive results on various visual adaptation benchmarks.
Read more6/27/2024

0
Multiple-Exit Tuning: Towards Inference-Efficient Adaptation for Vision Transformer
Zheng Liu, Jinchao Zhu, Nannan Li, Gao Huang
Parameter-efficient transfer learning (PETL) has shown great potential in adapting a vision transformer (ViT) pre-trained on large-scale datasets to various downstream tasks. Existing studies primarily focus on minimizing the number of learnable parameters. Although these methods are storage-efficient, they allocate excessive computational resources to easy samples, leading to inefficient inference. To address this issue, we introduce an inference-efficient tuning method termed multiple-exit tuning (MET). MET integrates multiple exits into the pre-trained ViT backbone. Since the predictions in ViT are made by a linear classifier, each exit is equipped with a linear prediction head. In inference stage, easy samples will exit at early exits and only hard enough samples will flow to the last exit, thus saving the computational cost for easy samples. MET consists of exit-specific adapters (E-adapters) and graph regularization. E-adapters are designed to extract suitable representations for different exits. To ensure parameter efficiency, all E-adapters share the same down-projection and up-projection matrices. As the performances of linear classifiers are influenced by the relationship among samples, we employ graph regularization to improve the representations fed into the classifiers at early exits. Finally, we conduct extensive experiments to verify the performance of MET. Experimental results show that MET has an obvious advantage over the state-of-the-art methods in terms of both accuracy and inference efficiency.
Read more9/24/2024
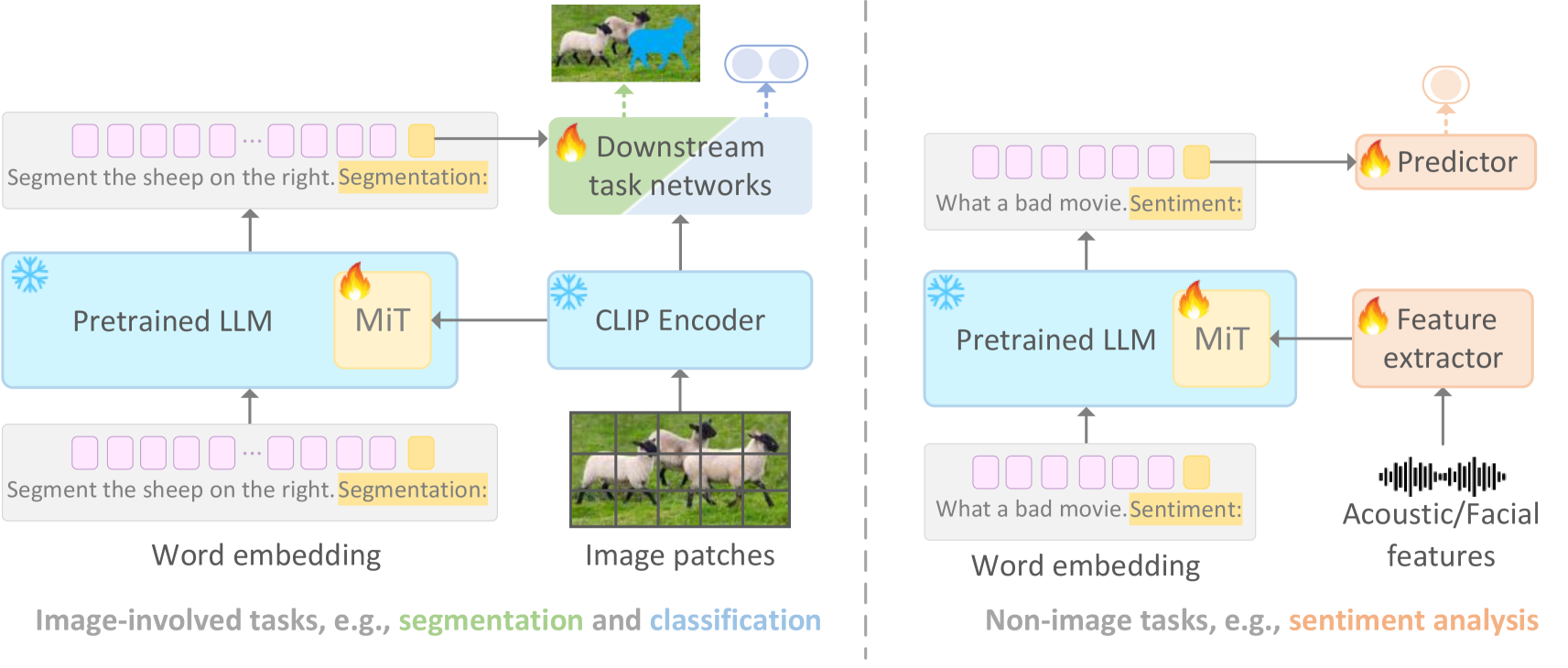
0
Multimodal Infusion Tuning for Large Models
Hao Sun, Yu Song, Xinyao Yu, Jiaqing Liu, Yen-Wei Chen, Lanfen Lin
Recent advancements in large-scale models have showcased remarkable generalization capabilities in various tasks. However, integrating multimodal processing into these models presents a significant challenge, as it often comes with a high computational burden. To address this challenge, we introduce a new parameter-efficient multimodal tuning strategy for large models in this paper, referred to as Multimodal Infusion Tuning (MiT). MiT leverages decoupled self-attention mechanisms within large language models to effectively integrate information from diverse modalities such as images and acoustics. In MiT, we also design a novel adaptive rescaling strategy at the attention head level, which optimizes the representation of infused multimodal features. Notably, all foundation models are kept frozen during the tuning process to reduce the computational burden and only 2.5% parameters are tunable. We conduct experiments across a range of multimodal tasks, including image-related tasks like referring segmentation and non-image tasks such as sentiment analysis. Our results showcase that MiT achieves state-of-the-art performance in multimodal understanding while significantly reducing computational overhead(10% of previous methods). Moreover, our tuned model exhibits robust reasoning abilities even in complex scenarios.
Read more7/17/2024
🌿
0
Visual Tuning
Bruce X. B. Yu, Jianlong Chang, Haixin Wang, Lingbo Liu, Shijie Wang, Zhiyu Wang, Junfan Lin, Lingxi Xie, Haojie Li, Zhouchen Lin, Qi Tian, Chang Wen Chen
Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
Read more4/16/2024