Visual Tuning
2305.06061
0
0
🌿
Abstract
Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
Create account to get full access
Overview
- The paper discusses recent advancements in fine-tuning visual machine learning models, which can lead to improved performance on various visual tasks.
- It highlights the emergence of pre-trained visual foundation models, which have enabled new approaches to visual model tuning beyond the standard full model fine-tuning.
- The paper aims to provide a comprehensive overview of the different visual tuning techniques, categorizing them into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning.
- It also suggests exciting research directions for future work in pre-training and various interactions in visual tuning.
Plain English Explanation
Machine learning models trained on large datasets, known as foundation models, have become increasingly powerful at tackling a wide range of tasks. When it comes to visual tasks, like recognizing objects in images, these pre-trained models have shown promising performance.
Rather than training a new model from scratch for each task, researchers have found that fine-tuning these pre-trained models can be an effective approach. Fine-tuning involves taking the pre-trained model and adjusting its parameters to perform well on a specific task, like object recognition.
Recently, new techniques have emerged that go beyond the standard full model fine-tuning. These newer approaches can achieve better performance while updating fewer parameters of the pre-trained model. This is particularly important for edge devices (like smartphones) and other applications that need to reuse the large foundation models deployed in the cloud.
The paper provides a detailed overview of these different visual tuning techniques, grouping them into five categories:
- Prompt Tuning: Adjusting the input prompt or instructions to the pre-trained model, rather than changing the model itself.
- Adapter Tuning: Adding small, task-specific neural network layers to the pre-trained model, which can be trained efficiently.
- Parameter Tuning: Selectively updating only certain parameters of the pre-trained model, rather than the entire set.
- Remapping Tuning: Modifying the mapping between the pre-trained model's outputs and the desired task outputs.
The paper also highlights some exciting research directions for the future, such as exploring new ways to pre-train these visual models and investigating how the different tuning techniques can work together.
Technical Explanation
The paper begins by acknowledging the promising performance of fine-tuning pre-trained visual models on various downstream tasks. This standard approach of fine-tuning the entire pre-trained model or just the final fully connected layer has been widely used.
However, the paper notes the surprising development of pre-trained visual foundation models, which has led to the emergence of new visual tuning techniques that go beyond the standard fine-tuning approach. These newer techniques can achieve superior performance compared to full model fine-tuning, while only updating a small number of parameters. This is particularly beneficial for edge devices and other applications that need to reuse large foundation models deployed in the cloud.
To help researchers understand the current landscape and future directions of visual tuning, the paper provides a systematic and comprehensive overview of recent work in this area. It categorizes the various visual tuning techniques into five groups:
- Prompt Tuning: Adjusting the input prompt or instructions to the pre-trained model, rather than changing the model itself. Examples of this approach can be found in work like When Do Prompting and Prefix Tuning Work?.
- Adapter Tuning: Adding small, task-specific neural network layers to the pre-trained model, which can be trained efficiently. This is similar to techniques like Supervised Fine-Tuning Can Turn Unsupervised Pre-Training Into A Strong Supervised Baseline.
- Parameter Tuning: Selectively updating only certain parameters of the pre-trained model, rather than the entire set. This approach is explored in works like L-Tuning: Synchronized Label Tuning for Prompt and Prefix.
- Remapping Tuning: Modifying the mapping between the pre-trained model's outputs and the desired task outputs.
The paper also suggests several exciting research directions for the future, such as exploring new ways to pre-train these visual models and investigating how the different tuning techniques can work together.
Critical Analysis
The paper provides a thorough and well-structured overview of the recent advancements in visual model tuning. It effectively categorizes the various techniques and highlights their respective strengths and potential applications.
One key strength of the paper is its emphasis on the importance of parameter-efficient tuning approaches, which can enable the reuse of large foundation models on edge devices and other applications. This is a crucial consideration as the size and complexity of these pre-trained models continue to grow.
However, the paper does not delve deeply into the limitations or potential drawbacks of the various tuning techniques. For example, it could have discussed the trade-offs between performance, model size, and computational requirements for each approach, or the potential biases that could be introduced by the tuning process.
Additionally, the paper could have challenged certain assumptions or aspects of the existing research more explicitly. For instance, it could have questioned whether the current categorization of tuning techniques is comprehensive or if there are other approaches that warrant consideration.
Overall, the paper serves as a valuable resource for researchers and practitioners interested in the field of visual model tuning. However, a more critical and nuanced analysis of the strengths, weaknesses, and future research directions could have further enhanced the contribution of this work.
Conclusion
This paper provides a comprehensive overview of the recent advancements in visual model tuning, a field that has seen significant progress with the emergence of pre-trained visual foundation models. By categorizing the different tuning techniques into five groups, the paper offers researchers and practitioners a structured way to understand the current landscape and explore new directions.
The key takeaway is that these parameter-efficient tuning approaches, such as prompt tuning, adapter tuning, and selective parameter updates, can enable the reuse of large foundation models in a wide range of applications, including edge devices. This is particularly important as the size and complexity of these pre-trained models continue to grow.
While the paper could have delved deeper into the limitations and potential trade-offs of the various tuning techniques, it still serves as a valuable resource for the research community. By highlighting the exciting research directions in this field, the paper lays the groundwork for further advancements in visual model tuning and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Supervised Fine-tuning in turn Improves Visual Foundation Models
Xiaohu Jiang, Yixiao Ge, Yuying Ge, Dachuan Shi, Chun Yuan, Ying Shan
0
0
Image-text training like CLIP has dominated the pretraining of vision foundation models in recent years. Subsequent efforts have been made to introduce region-level visual learning into CLIP's pretraining but face scalability challenges due to the lack of large-scale region-level datasets. Drawing inspiration from supervised fine-tuning (SFT) in natural language processing such as instruction tuning, we explore the potential of fine-grained SFT in enhancing the generation of vision foundation models after their pretraining. Thus a two-stage method ViSFT (Vision SFT) is proposed to unleash the fine-grained knowledge of vision foundation models. In ViSFT, the vision foundation model is enhanced by performing visual joint learning on some in-domain tasks and then tested on out-of-domain benchmarks. With updating using ViSFT on 8 V100 GPUs in less than 2 days, a vision transformer with over 4.4B parameters shows improvements across various out-of-domain benchmarks including vision and vision-linguistic scenarios.
4/12/2024

Minimal Interaction Edge Tuning: A New Paradigm for Visual Adaptation
Ningyuan Tang, Minghao Fu, Jianxin Wu
0
0
The rapid scaling of large vision pretrained models makes fine-tuning tasks more and more difficult on edge devices with low computational resources. We explore a new visual adaptation paradigm called edge tuning, which treats large pretrained models as standalone feature extractors that run on powerful cloud servers. The fine-tuning carries out on edge devices with small networks which require low computational resources. Existing methods that are potentially suitable for our edge tuning paradigm are discussed. But, three major drawbacks hinder their application in edge tuning: low adaptation capability, large adapter network, and high information transfer overhead. To address these issues, we propose Minimal Interaction Edge Tuning, or MIET, which reveals that the sum of intermediate features from pretrained models not only has minimal information transfer but also has high adaptation capability. With a lightweight attention-based adaptor network, MIET achieves information transfer efficiency, parameter efficiency, computational and memory efficiency, and at the same time demonstrates competitive results on various visual adaptation benchmarks.
6/27/2024
An Empirical Study of Parameter Efficient Fine-tuning on Vision-Language Pre-train Model
Yuxin Tian, Mouxing Yang, Yunfan Li, Dayiheng Liu, Xingzhang Ren, Xi Peng, Jiancheng Lv
0
0
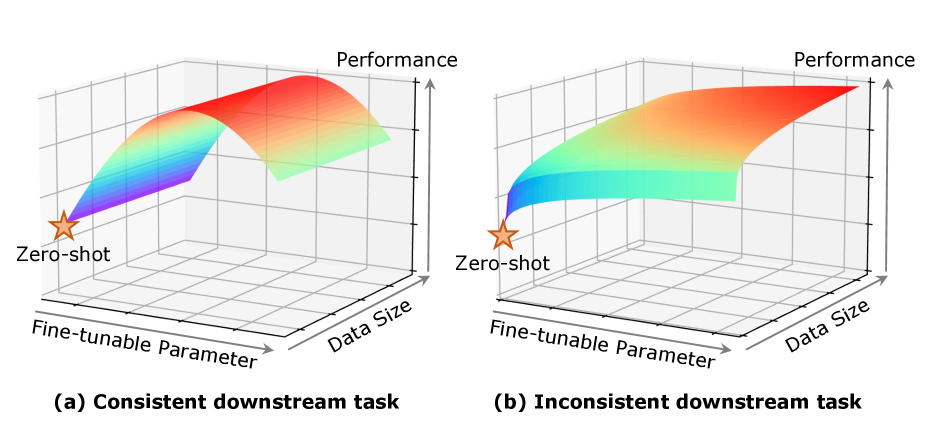
Recent studies applied Parameter Efficient Fine-Tuning techniques (PEFTs) to efficiently narrow the performance gap between pre-training and downstream. There are two important factors for various PEFTs, namely, the accessible data size and fine-tunable parameter size. A natural expectation for PEFTs is that the performance of various PEFTs is positively related to the data size and fine-tunable parameter size. However, according to the evaluation of five PEFTs on two downstream vision-language (VL) tasks, we find that such an intuition holds only if the downstream data and task are not consistent with pre-training. For downstream fine-tuning consistent with pre-training, data size no longer affects the performance, while the influence of fine-tunable parameter size is not monotonous. We believe such an observation could guide the choice of training strategy for various PEFTs.
5/21/2024
Parameter-Efficient Active Learning for Foundational models
Athmanarayanan Lakshmi Narayanan, Ranganath Krishnan, Amrutha Machireddy, Mahesh Subedar
0
0
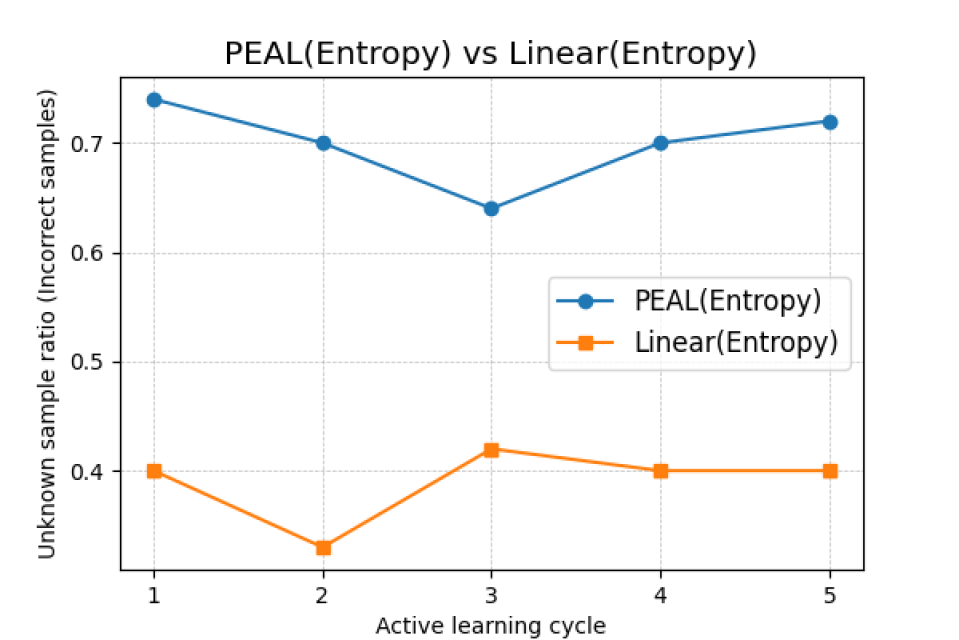
Foundational vision transformer models have shown impressive few shot performance on many vision tasks. This research presents a novel investigation into the application of parameter efficient fine-tuning methods within an active learning (AL) framework, to advance the sampling selection process in extremely budget constrained classification tasks. The focus on image datasets, known for their out-of-distribution characteristics, adds a layer of complexity and relevance to our study. Through a detailed evaluation, we illustrate the improved AL performance on these challenging datasets, highlighting the strategic advantage of merging parameter efficient fine tuning methods with foundation models. This contributes to the broader discourse on optimizing AL strategies, presenting a promising avenue for future exploration in leveraging foundation models for efficient and effective data annotation in specialized domains.
6/17/2024