MisgenderMender: A Community-Informed Approach to Interventions for Misgendering

0
👁️
Sign in to get full access
Overview
- This paper addresses the issue of misgendering, which is the act of incorrectly addressing someone's gender, in everyday technologies.
- The researchers conducted a survey of gender-diverse individuals in the US to understand their perspectives on automated interventions for text-based misgendering.
- Based on the survey insights, the researchers introduced a new task and dataset called MisgenderMender, which focuses on detecting and correcting misgendering in text.
- The dataset comprises 3790 instances of social media content and language model-generated text about non-cisgender public figures, annotated for the presence of misgendering and with additional annotations for correcting misgendering in the language model-generated text.
Plain English Explanation
The paper focuses on the problem of misgendering, which is when someone is addressed using the wrong gender. This can be very hurtful and disrespectful to people who identify as non-binary or transgender. However, there hasn't been much research on how to address this problem, especially in technology like social media and chatbots.
To better understand this issue, the researchers surveyed people who identify as gender-diverse in the US. They wanted to know how common misgendering is, what kind of solutions people want, and what concerns they have about potential solutions.
Based on the survey results, the researchers created a new dataset called MisgenderMender. This dataset contains 3790 examples of social media posts and text generated by language models (like ChatGPT) about non-cisgender public figures. The examples are marked to show where misgendering occurs, and the dataset also includes annotations for how the misgendering should be corrected.
The researchers hope that this dataset will help develop better technology to detect and fix misgendering in text. They've released the full dataset, code, and a demo so that other researchers can build on this work. The goal is to make technology more inclusive and respectful of people's gender identity.
Technical Explanation
The paper addresses the lack of research on interventions for misgendering, which is the act of incorrectly addressing someone's gender. The researchers conducted a survey of gender-diverse individuals in the US to understand their perspectives on automated interventions for text-based misgendering.
Based on the survey insights, the researchers introduced a new task and dataset called MisgenderMender. The dataset comprises 3790 instances of social media content and language model-generated text about non-cisgender public figures, annotated for the presence of misgendering, with additional annotations for correcting misgendering in the language model-generated text.
The MisgenderMender dataset is designed for a two-part task: (i) detecting misgendering in text, and (ii) correcting misgendering where it is present in domains where editing is appropriate. The researchers set initial benchmarks by evaluating existing NLP systems on this dataset and highlighted the challenges for future models to address.
The Tokenization Matters: Navigating Data-Scarce Tokenization Gender paper explores issues with tokenization and gender, the Breaking Silence: Detecting & Mitigating Gendered Abuse in Hindi paper addresses gendered abuse in Hindi, and the Challenging Negative Gender Stereotypes: A Study of the Effectiveness of Automated Debiasing paper investigates automated methods for debiasing.
Critical Analysis
The paper provides a valuable contribution by addressing the important issue of misgendering in everyday technologies, which has received limited research attention. The survey-based approach to understanding the perspectives of gender-diverse individuals is a strength, as it ensures the research is grounded in the experiences and needs of the affected community.
However, the paper does not discuss potential limitations or challenges in the deployment of the proposed interventions. For example, it does not address potential privacy concerns or the risk of incorrect gender detection leading to further harm. Additionally, the paper does not examine the generalizability of the MisgenderMender dataset beyond the specific context of non-cisgender public figures.
Further research is needed to investigate the robustness and scalability of the proposed interventions, as well as their potential unintended consequences. The Investigating Markers and Drivers of Gender Bias in Machine Translations and Auditing Large Language Models for Enhanced Text-Based papers provide relevant insights on understanding and mitigating gender bias in language models, which could inform future work on the MisgenderMender task.
Conclusion
This paper addresses the important and often overlooked issue of misgendering in everyday technologies. By conducting a survey of gender-diverse individuals and introducing the MisgenderMender dataset, the researchers have taken a significant step towards developing more inclusive and respectful technologies.
The MisgenderMender dataset and task provide a valuable resource for researchers and practitioners to build and test models that can detect and correct misgendering in text. This work has the potential to make a real difference in the lived experiences of non-cisgender individuals and promote greater acceptance and understanding of diverse gender identities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
MisgenderMender: A Community-Informed Approach to Interventions for Misgendering
Tamanna Hossain, Sunipa Dev, Sameer Singh
Content Warning: This paper contains examples of misgendering and erasure that could be offensive and potentially triggering. Misgendering, the act of incorrectly addressing someone's gender, inflicts serious harm and is pervasive in everyday technologies, yet there is a notable lack of research to combat it. We are the first to address this lack of research into interventions for misgendering by conducting a survey of gender-diverse individuals in the US to understand perspectives about automated interventions for text-based misgendering. Based on survey insights on the prevalence of misgendering, desired solutions, and associated concerns, we introduce a misgendering interventions task and evaluation dataset, MisgenderMender. We define the task with two sub-tasks: (i) detecting misgendering, followed by (ii) correcting misgendering where misgendering is present in domains where editing is appropriate. MisgenderMender comprises 3790 instances of social media content and LLM-generations about non-cisgender public figures, annotated for the presence of misgendering, with additional annotations for correcting misgendering in LLM-generated text. Using this dataset, we set initial benchmarks by evaluating existing NLP systems and highlighting challenges for future models to address. We release the full dataset, code, and demo at https://tamannahossainkay.github.io/misgendermender/.
Read more4/24/2024

0
MiTTenS: A Dataset for Evaluating Gender Mistranslation
Kevin Robinson, Sneha Kudugunta, Romina Stella, Sunipa Dev, Jasmijn Bastings
Translation systems, including foundation models capable of translation, can produce errors that result in gender mistranslation, and such errors can be especially harmful. To measure the extent of such potential harms when translating into and out of English, we introduce a dataset, MiTTenS, covering 26 languages from a variety of language families and scripts, including several traditionally under-represented in digital resources. The dataset is constructed with handcrafted passages that target known failure patterns, longer synthetically generated passages, and natural passages sourced from multiple domains. We demonstrate the usefulness of the dataset by evaluating both neural machine translation systems and foundation models, and show that all systems exhibit gender mistranslation and potential harm, even in high resource languages.
Read more8/15/2024
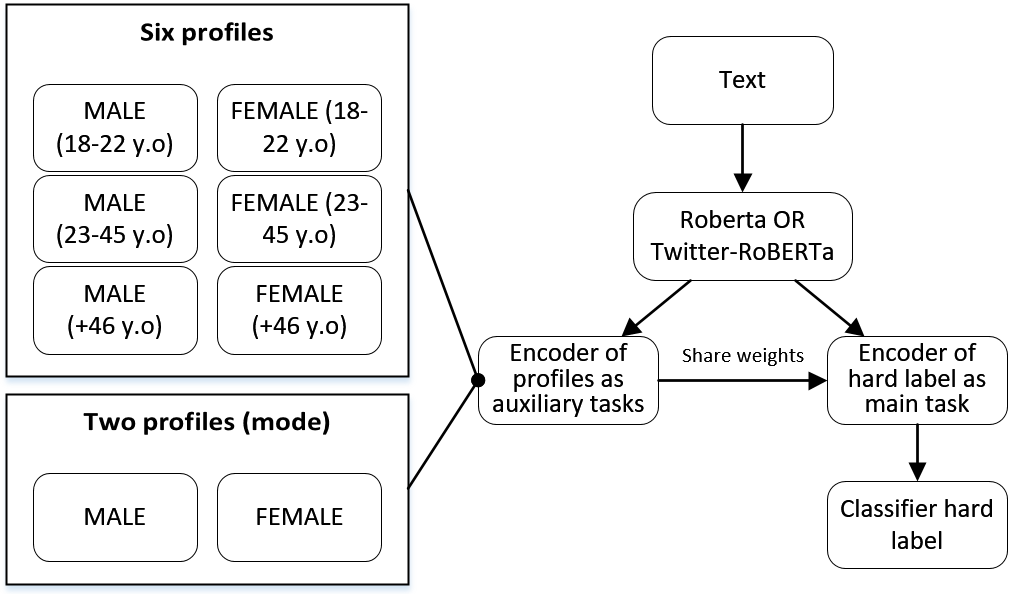
0
A multitask learning framework for leveraging subjectivity of annotators to identify misogyny
Jason Angel, Segun Taofeek Aroyehun, Grigori Sidorov, Alexander Gelbukh
Identifying misogyny using artificial intelligence is a form of combating online toxicity against women. However, the subjective nature of interpreting misogyny poses a significant challenge to model the phenomenon. In this paper, we propose a multitask learning approach that leverages the subjectivity of this task to enhance the performance of the misogyny identification systems. We incorporated diverse perspectives from annotators in our model design, considering gender and age across six profile groups, and conducted extensive experiments and error analysis using two language models to validate our four alternative designs of the multitask learning technique to identify misogynistic content in English tweets. The results demonstrate that incorporating various viewpoints enhances the language models' ability to interpret different forms of misogyny. This research advances content moderation and highlights the importance of embracing diverse perspectives to build effective online moderation systems.
Read more6/26/2024

0
Generating Gender Alternatives in Machine Translation
Sarthak Garg, Mozhdeh Gheini, Clara Emmanuel, Tatiana Likhomanenko, Qin Gao, Matthias Paulik
Machine translation (MT) systems often translate terms with ambiguous gender (e.g., English term the nurse) into the gendered form that is most prevalent in the systems' training data (e.g., enfermera, the Spanish term for a female nurse). This often reflects and perpetuates harmful stereotypes present in society. With MT user interfaces in mind that allow for resolving gender ambiguity in a frictionless manner, we study the problem of generating all grammatically correct gendered translation alternatives. We open source train and test datasets for five language pairs and establish benchmarks for this task. Our key technical contribution is a novel semi-supervised solution for generating alternatives that integrates seamlessly with standard MT models and maintains high performance without requiring additional components or increasing inference overhead.
Read more7/31/2024