Mistral-SPLADE: LLMs for for better Learned Sparse Retrieval

0

Sign in to get full access
Overview
- The provided paper presents Mistral-SPLADE, a new approach that leverages large language models (LLMs) for better sparse retrieval.
- It builds upon SPLADE, a state-of-the-art sparse retrieval model, and aims to improve its performance by incorporating the language understanding capabilities of LLMs.
- The key ideas include using LLMs for query encoding, document encoding, and relevance scoring, while maintaining the benefits of sparse retrieval.
Plain English Explanation
Mistral-SPLADE: Leveraging Large Language Models for Better Sparse Retrieval
Searching through large databases of information, like the internet, can be challenging. Traditional search methods may struggle to understand the nuanced meaning of queries and find the most relevant documents.
This research paper introduces Mistral-SPLADE, a new approach that combines the strengths of large language models (LLMs) and sparse retrieval techniques. LLMs are advanced AI models that can understand and generate human-like text. The researchers use these LLMs to better encode the meaning of search queries and documents, which helps identify the most relevant information.
At the same time, Mistral-SPLADE maintains the benefits of sparse retrieval, which uses compact representations of text to quickly search through large datasets. This hybrid approach aims to deliver more accurate and efficient search results compared to previous methods.
The key innovations of Mistral-SPLADE include:
- Using LLMs to encode search queries and document content in a way that captures their semantic meaning.
- Integrating the LLM-based encodings with sparse retrieval techniques to leverage their complementary strengths.
- Careful model design and training to balance effectiveness and efficiency for real-world search applications.
By combining the language understanding power of LLMs with the speed and scalability of sparse retrieval, Mistral-SPLADE represents a promising step forward in making large-scale search and information retrieval more accurate and useful.
Technical Explanation
Mistral-SPLADE: Leveraging Large Language Models for Better Sparse Retrieval
The core idea behind Mistral-SPLADE is to leverage the powerful language understanding capabilities of large language models (LLMs) to enhance the performance of sparse retrieval models, specifically SPLADE.
The researchers first use an LLM to encode search queries and document content into dense vector representations that capture their semantic meaning. These dense encodings are then combined with the sparse representations used by SPLADE to compute relevance scores between queries and documents.
The architecture of Mistral-SPLADE consists of several key components:
- Query Encoding: An LLM is used to encode the input query into a dense vector representation.
- Document Encoding: The LLM is also used to encode document content into dense vectors, which are then combined with the sparse representations from SPLADE.
- Relevance Scoring: The dense and sparse representations are jointly used to compute the relevance score between the query and each document.
The researchers carefully design the training process to ensure that Mistral-SPLADE maintains the efficiency and scalability advantages of sparse retrieval, while leveraging the language understanding capabilities of LLMs to improve retrieval effectiveness.
Experiments on standard retrieval benchmarks show that Mistral-SPLADE outperforms both traditional sparse retrieval methods and previous LLM-based approaches, demonstrating the benefits of this hybrid approach.
Critical Analysis
The Mistral-SPLADE paper presents a compelling approach to enhancing sparse retrieval models with the power of large language models. The key strengths of this work include:
-
Leveraging Complementary Strengths: By combining dense LLM-based encodings with sparse representations, Mistral-SPLADE effectively leverages the strengths of both approaches, leading to improvements in retrieval performance.
-
Maintaining Efficiency: The researchers carefully design the model and training process to preserve the efficiency and scalability advantages of sparse retrieval, an important consideration for real-world search applications.
-
Rigorous Evaluation: The paper includes a thorough experimental evaluation on standard retrieval benchmarks, demonstrating the benefits of Mistral-SPLADE over relevant baselines.
However, the paper also acknowledges some limitations and areas for further research:
-
Generalization to Other Domains: The evaluation is primarily focused on standard academic retrieval datasets, and it would be valuable to assess the performance of Mistral-SPLADE on a broader range of real-world search scenarios.
-
Interpretability and Explainability: As with many LLM-based approaches, the inner workings of Mistral-SPLADE may be less interpretable than traditional retrieval models. Investigating ways to improve the transparency of the system could be a valuable direction.
-
Computational Costs: While the researchers aim to maintain efficiency, the inclusion of LLM-based components may still incur higher computational costs compared to pure sparse retrieval methods, which could be a consideration for certain applications.
Overall, the Mistral-SPLADE paper presents a well-designed and promising approach to enhancing sparse retrieval using large language models. The results suggest that this hybrid approach can lead to improved search performance, and the researchers have thoughtfully addressed key practical considerations. Further exploration of the approach on diverse real-world scenarios and continued efforts to improve interpretability and efficiency could further strengthen the contributions of this work.
Conclusion
The Mistral-SPLADE paper introduces a novel approach that leverages the language understanding capabilities of large language models (LLMs) to enhance the performance of sparse retrieval models. By combining dense LLM-based encodings with the sparse representations used in SPLADE, the researchers are able to achieve improved retrieval effectiveness while maintaining the efficiency and scalability advantages of sparse retrieval.
The key innovations of Mistral-SPLADE include the use of LLMs for query and document encoding, as well as the careful design of the model architecture and training process to balance effectiveness and efficiency. Experimental results on standard retrieval benchmarks demonstrate the benefits of this hybrid approach over traditional sparse retrieval methods and previous LLM-based techniques.
While the paper acknowledges some limitations and areas for further research, such as generalization to other domains and improving interpretability, the Mistral-SPLADE approach represents a promising step forward in the field of large-scale search and information retrieval. By combining the strengths of LLMs and sparse retrieval, this work has the potential to make search more accurate, efficient, and accessible for a wide range of applications and users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mistral-SPLADE: LLMs for for better Learned Sparse Retrieval
Meet Doshi, Vishwajeet Kumar, Rudra Murthy, Vignesh P, Jaydeep Sen
Learned Sparse Retrievers (LSR) have evolved into an effective retrieval strategy that can bridge the gap between traditional keyword-based sparse retrievers and embedding-based dense retrievers. At its core, learned sparse retrievers try to learn the most important semantic keyword expansions from a query and/or document which can facilitate better retrieval with overlapping keyword expansions. LSR like SPLADE has typically been using encoder only models with MLM (masked language modeling) style objective in conjunction with known ways of retrieval performance improvement such as hard negative mining, distillation, etc. In this work, we propose to use decoder-only model for learning semantic keyword expansion. We posit, decoder only models that have seen much higher magnitudes of data are better equipped to learn keyword expansions needed for improved retrieval. We use Mistral as the backbone to develop our Learned Sparse Retriever similar to SPLADE and train it on a subset of sentence-transformer data which is often used for training text embedding models. Our experiments support the hypothesis that a sparse retrieval model based on decoder only large language model (LLM) surpasses the performance of existing LSR systems, including SPLADE and all its variants. The LLM based model (Echo-Mistral-SPLADE) now stands as a state-of-the-art learned sparse retrieval model on the BEIR text retrieval benchmark.
Read more8/23/2024
0
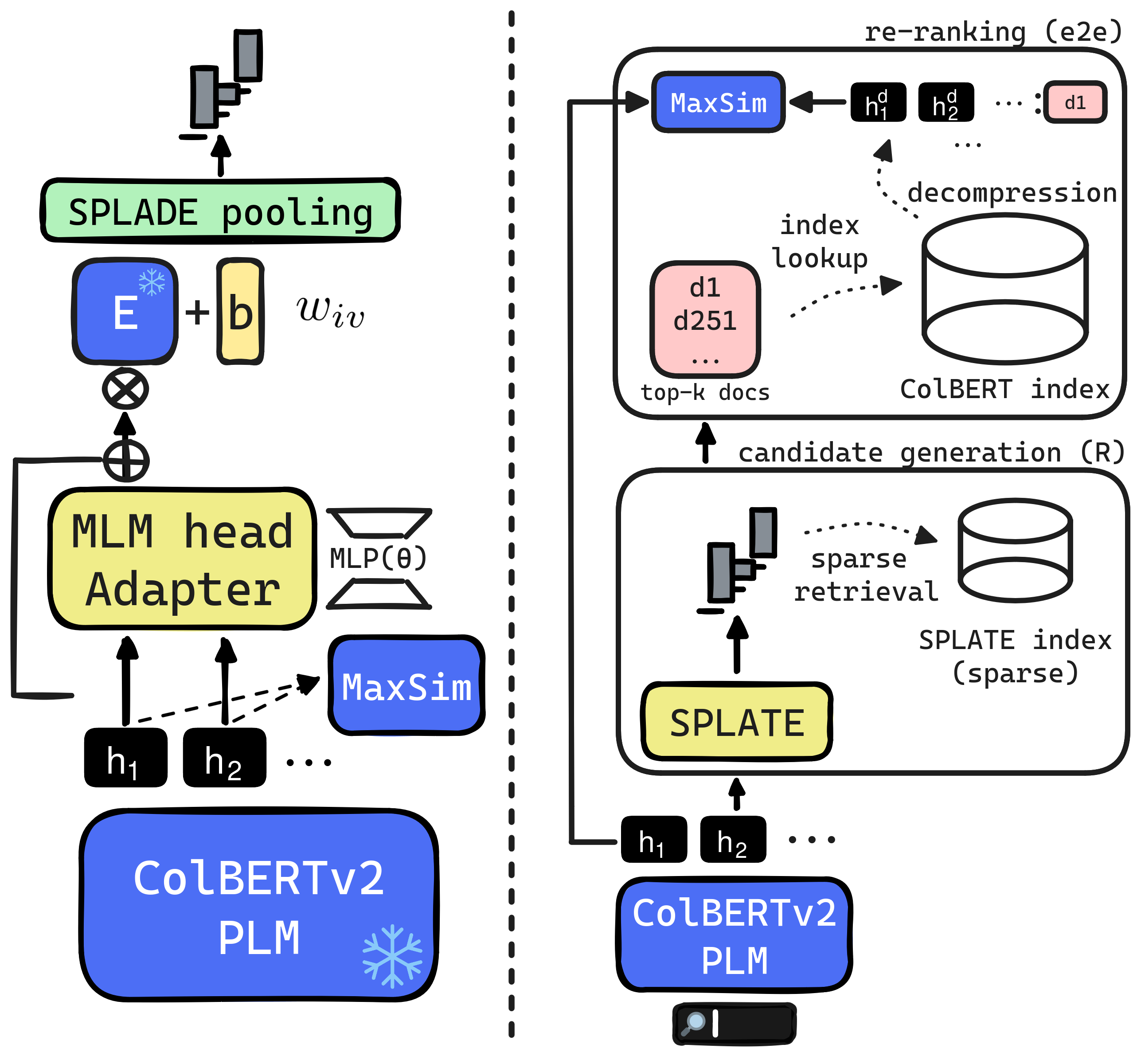
SPLATE: Sparse Late Interaction Retrieval
Thibault Formal, St'ephane Clinchant, Herv'e D'ejean, Carlos Lassance
The late interaction paradigm introduced with ColBERT stands out in the neural Information Retrieval space, offering a compelling effectiveness-efficiency trade-off across many benchmarks. Efficient late interaction retrieval is based on an optimized multi-step strategy, where an approximate search first identifies a set of candidate documents to re-rank exactly. In this work, we introduce SPLATE, a simple and lightweight adaptation of the ColBERTv2 model which learns an ``MLM adapter'', mapping its frozen token embeddings to a sparse vocabulary space with a partially learned SPLADE module. This allows us to perform the candidate generation step in late interaction pipelines with traditional sparse retrieval techniques, making it particularly appealing for running ColBERT in CPU environments. Our SPLATE ColBERTv2 pipeline achieves the same effectiveness as the PLAID ColBERTv2 engine by re-ranking 50 documents that can be retrieved under 10ms.
Read more4/23/2024

0
Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
Read more7/11/2024
0
Contextualization with SPLADE for High Recall Retrieval
Eugene Yang
High Recall Retrieval (HRR), such as eDiscovery and medical systematic review, is a search problem that optimizes the cost of retrieving most relevant documents in a given collection. Iterative approaches, such as iterative relevance feedback and uncertainty sampling, are shown to be effective under various operational scenarios. Despite neural models demonstrating success in other text-related tasks, linear models such as logistic regression, in general, are still more effective and efficient in HRR since the model is trained and retrieves documents from the same fixed collection. In this work, we leverage SPLADE, an efficient retrieval model that transforms documents into contextualized sparse vectors, for HRR. Our approach combines the best of both worlds, leveraging both the contextualization from pretrained language models and the efficiency of linear models. It reduces 10% and 18% of the review cost in two HRR evaluation collections under a one-phase review workflow with a target recall of 80%. The experiment is implemented with TARexp and is available at https://github.com/eugene-yang/LSR-for-TAR.
Read more5/8/2024