Hallucination Detection: Robustly Discerning Reliable Answers in Large Language Models

0

Sign in to get full access
Overview
- Developing techniques to reliably detect hallucinations in large language models
- Hallucinations are when models generate plausible-sounding but factually incorrect information
- Detecting hallucinations is crucial for ensuring the reliability of language model outputs
Plain English Explanation
Large language models like GPT-3 are incredibly powerful, but they can sometimes generate hallucinations - statements that sound convincing but are actually false or made up. This can be a big problem when we rely on these models for important information.
This paper explores ways to detect these hallucinations and ensure we can trust the outputs of large language models. The key idea is to look for inconsistencies or contradictions in the model's responses that might indicate it is hallucinating rather than drawing on real information.
By developing robust hallucination detection techniques, the researchers hope to make large language models more reliable and trustworthy for a wide range of applications, from summarization to question answering.
Technical Explanation
The paper proposes a novel approach for detecting hallucinations in the outputs of large language models. The key insight is that hallucinations tend to exhibit certain patterns, such as internal inconsistencies or contradictions, that can be leveraged to identify them.
The researchers first construct a large dataset of human-written text and model-generated text, with labels indicating whether each piece of text is a hallucination or not. They then use this dataset to train a classifier that can detect hallucinations based on textual features.
The classifier looks at factors like grammatical structure, semantic coherence, and factual correctness to determine whether a given piece of text is likely to be a hallucination. By combining these signals, the model can reliably identify when a language model is generating unreliable or made-up information.
Critical Analysis
The paper presents a promising approach for detecting hallucinations in large language models, but it also acknowledges several limitations and areas for future work. For example, the dataset used to train the classifier is relatively small and may not capture the full diversity of hallucinations that can occur in real-world settings.
Additionally, the paper doesn't explore how the hallucination detection system might be integrated into the language model itself, to provide real-time feedback and improve the model's reliability during generation. Unsupervised or internal detection methods could be valuable in this regard.
Overall, the research represents an important step towards enhancing the trustworthiness of large language models, but further work is needed to fully address the hallucination problem and ensure these powerful AI systems can be reliably deployed in high-stakes applications.
Conclusion
This paper presents a novel approach for detecting hallucinations in the outputs of large language models, a crucial challenge for ensuring the reliability and trustworthiness of these AI systems. By leveraging textual features to identify inconsistencies and contradictions, the researchers have developed a classifier that can reliably distinguish between genuine and hallucinated information.
While the proposed method has limitations and areas for further exploration, it represents an important step towards enhancing the trustworthiness of large language models and paving the way for their safe and responsible deployment in real-world applications. As the field of AI continues to advance, the ability to detect and mitigate hallucinations will only become more critical for maintaining the integrity and reliability of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hallucination Detection: Robustly Discerning Reliable Answers in Large Language Models
Yuyan Chen, Qiang Fu, Yichen Yuan, Zhihao Wen, Ge Fan, Dayiheng Liu, Dongmei Zhang, Zhixu Li, Yanghua Xiao
Large Language Models (LLMs) have gained widespread adoption in various natural language processing tasks, including question answering and dialogue systems. However, a major drawback of LLMs is the issue of hallucination, where they generate unfaithful or inconsistent content that deviates from the input source, leading to severe consequences. In this paper, we propose a robust discriminator named RelD to effectively detect hallucination in LLMs' generated answers. RelD is trained on the constructed RelQA, a bilingual question-answering dialogue dataset along with answers generated by LLMs and a comprehensive set of metrics. Our experimental results demonstrate that the proposed RelD successfully detects hallucination in the answers generated by diverse LLMs. Moreover, it performs well in distinguishing hallucination in LLMs' generated answers from both in-distribution and out-of-distribution datasets. Additionally, we also conduct a thorough analysis of the types of hallucinations that occur and present valuable insights. This research significantly contributes to the detection of reliable answers generated by LLMs and holds noteworthy implications for mitigating hallucination in the future work.
Read more7/8/2024
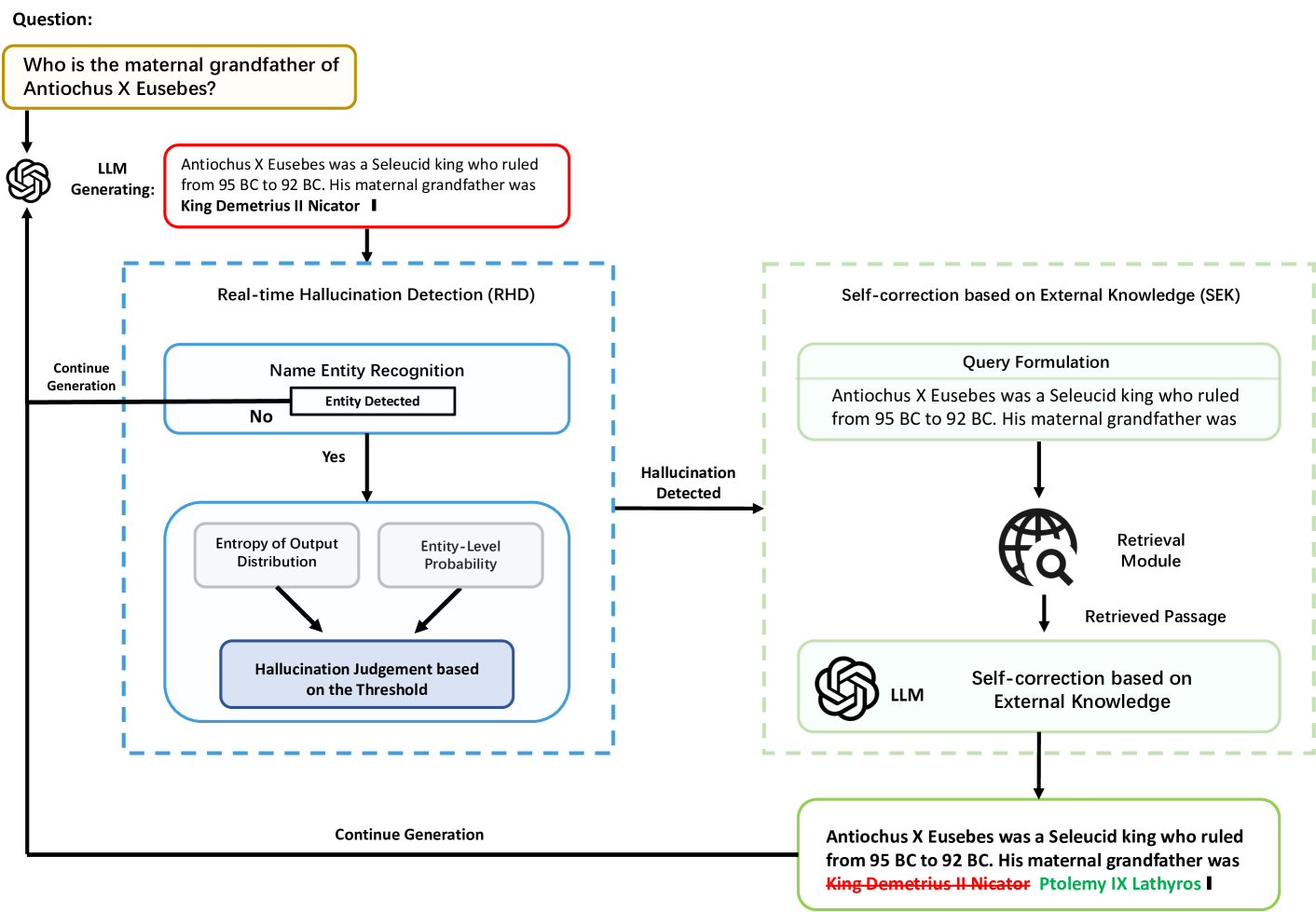
0
Mitigating Entity-Level Hallucination in Large Language Models
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, Yiqun Liu
The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
Read more7/23/2024

0
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Song Wang, Xun Wang, Jie Mei, Yujia Xie, Sean Muarray, Zhang Li, Lingfeng Wu, Si-Qing Chen, Wayne Xiong
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
Read more7/23/2024
🔎
0
Unified Hallucination Detection for Multimodal Large Language Models
Xiang Chen, Chenxi Wang, Yida Xue, Ningyu Zhang, Xiaoyan Yang, Qiang Li, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen
Despite significant strides in multimodal tasks, Multimodal Large Language Models (MLLMs) are plagued by the critical issue of hallucination. The reliable detection of such hallucinations in MLLMs has, therefore, become a vital aspect of model evaluation and the safeguarding of practical application deployment. Prior research in this domain has been constrained by a narrow focus on singular tasks, an inadequate range of hallucination categories addressed, and a lack of detailed granularity. In response to these challenges, our work expands the investigative horizons of hallucination detection. We present a novel meta-evaluation benchmark, MHaluBench, meticulously crafted to facilitate the evaluation of advancements in hallucination detection methods. Additionally, we unveil a novel unified multimodal hallucination detection framework, UNIHD, which leverages a suite of auxiliary tools to validate the occurrence of hallucinations robustly. We demonstrate the effectiveness of UNIHD through meticulous evaluation and comprehensive analysis. We also provide strategic insights on the application of specific tools for addressing various categories of hallucinations.
Read more5/28/2024