Mitigating Malicious Attacks in Federated Learning via Confidence-aware Defense

0
🔎
Sign in to get full access
Overview
- Federated learning is a collaborative AI training approach where multiple devices or organizations train a shared model without sharing their raw data.
- However, federated learning is vulnerable to malicious attacks where some participants provide bad data or model updates to corrupt the final model.
- This paper proposes a "confidence-aware defense" to mitigate such malicious attacks in federated learning environments.
Plain English Explanation
Federated learning allows different devices or organizations to work together to train a shared AI model, without having to share their private data. This is really useful for applications where data privacy is important, like healthcare or finance.
However, federated learning has a weakness - some participants could try to sabotage the training process by providing bad or malicious data and model updates. This can corrupt the final AI model and make it unreliable.
The researchers in this paper have come up with a new defense mechanism called "confidence-aware defense" to protect against these kinds of malicious attacks in federated learning. The key idea is to give more weight to model updates that the participants are more confident about, and less weight to updates that seem suspicious or unreliable.
By doing this, the final AI model can be kept safe and accurate, even if some of the participants are trying to attack the system. This is an important advance that could help make federated learning more secure and trustworthy for real-world applications.
Technical Explanation
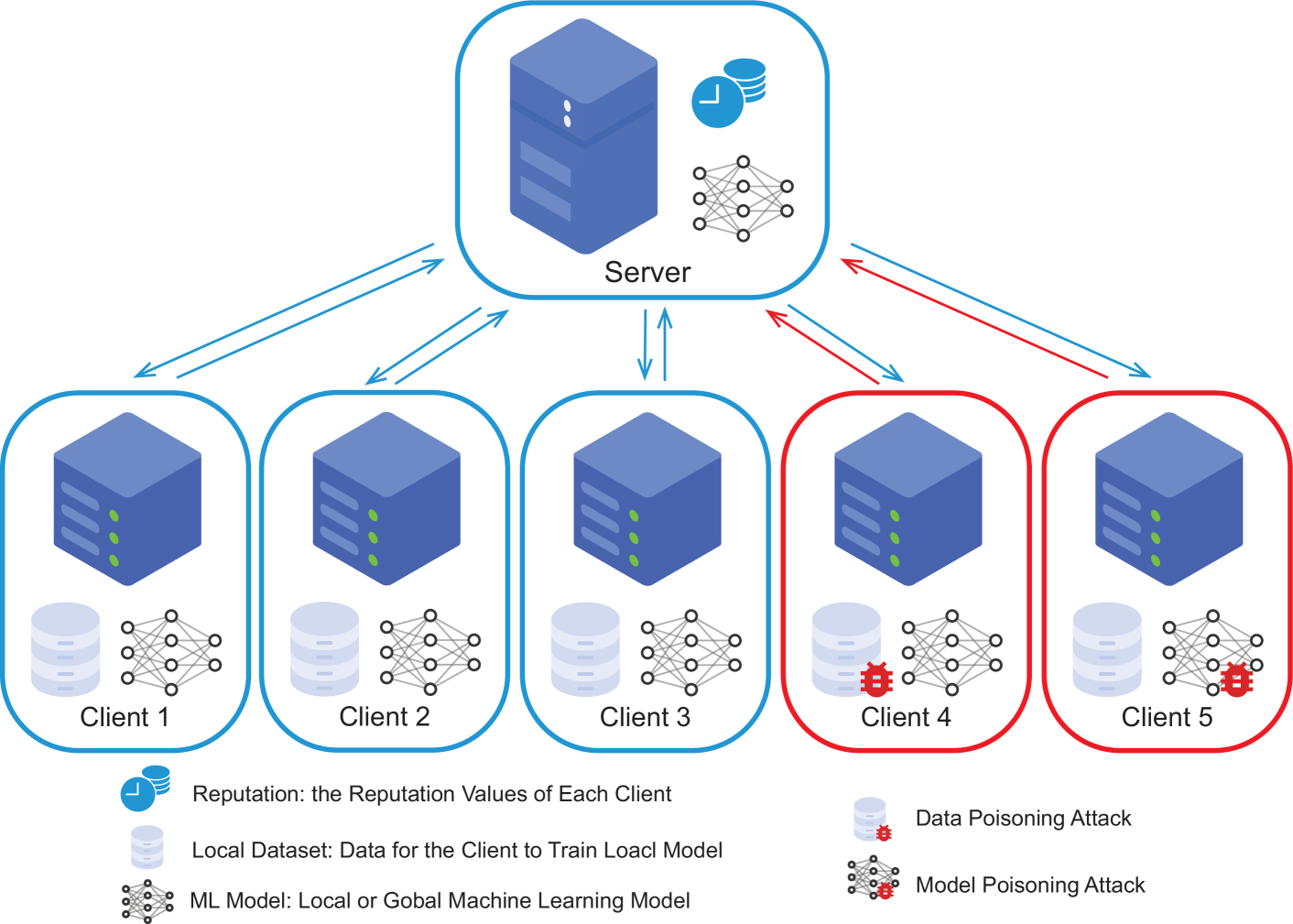
The paper proposes a confidence-aware defense mechanism to mitigate malicious attacks in federated learning environments. The core idea is to assign higher weights to model updates that are accompanied by higher participant confidence scores, and lower weights to updates with lower confidence.
Specifically, the authors introduce a client-side credibility management module that estimates the credibility of each participant based on the consistency of their past updates. During the federated learning process, the central server applies a precision-guided aggregation scheme, weighting each participant's update proportionally to their estimated credibility.
The authors evaluate their approach on image classification and language modeling tasks, and demonstrate its effectiveness in mitigating data poisoning attacks and model poisoning attacks compared to baseline federated learning methods. They also show that their approach is able to identify and isolate malicious participants even in the presence of adaptive attacks.
Critical Analysis
The paper presents a promising approach to enhancing the security and reliability of federated learning systems. The confidence-aware defense mechanism seems effective at mitigating a variety of malicious attacks by selectively weighting participant updates based on their estimated credibility.
One limitation of the work is that it relies on the ability to accurately estimate participant credibility, which may be challenging in real-world scenarios with dynamic participant populations and evolving attack strategies. The authors acknowledge this and suggest further research into more robust credibility estimation techniques.
Additionally, the evaluation is primarily focused on synthetic attack scenarios, and it would be valuable to see how the approach performs in more realistic federated learning settings with heterogeneous data distributions and diverse participant behaviors.
Overall, this research represents an important step forward in building more secure and trustworthy federated learning systems, but there is still work to be done to address the practical challenges of deploying such defenses in real-world applications.
Conclusion
This paper introduces a confidence-aware defense mechanism to mitigate malicious attacks in federated learning. By selectively weighting participant updates based on their estimated credibility, the approach is able to effectively protect the final AI model from data poisoning and model poisoning attacks.
The technical innovations and empirical results presented in this work demonstrate the potential for enhancing the security and reliability of federated learning, which is a crucial step towards enabling the widespread adoption of this collaborative AI training paradigm. As federated learning becomes more widely used in sensitive domains like healthcare and finance, robust defense mechanisms like the one proposed here will be increasingly important to safeguard against malicious actors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Mitigating Malicious Attacks in Federated Learning via Confidence-aware Defense
Qilei Li, Ahmed M. Abdelmoniem
Federated Learning (FL) is a distributed machine learning diagram that enables multiple clients to collaboratively train a global model without sharing their private local data. However, FL systems are vulnerable to attacks that are happening in malicious clients through data poisoning and model poisoning, which can deteriorate the performance of aggregated global model. Existing defense methods typically focus on mitigating specific types of poisoning and are often ineffective against unseen types of attack. These methods also assume an attack happened moderately while is not always holds true in real. Consequently, these methods can significantly fail in terms of accuracy and robustness when detecting and addressing updates from attacked malicious clients. To overcome these challenges, in this work, we propose a simple yet effective framework to detect malicious clients, namely Confidence-Aware Defense (CAD), that utilizes the confidence scores of local models as criteria to evaluate the reliability of local updates. Our key insight is that malicious attacks, regardless of attack type, will cause the model to deviate from its previous state, thus leading to increased uncertainty when making predictions. Therefore, CAD is comprehensively effective for both model poisoning and data poisoning attacks by accurately identifying and mitigating potential malicious updates, even under varying degrees of attacks and data heterogeneity. Experimental results demonstrate that our method significantly enhances the robustness of FL systems against various types of attacks across various scenarios by achieving higher model accuracy and stability.
Read more8/20/2024
0
Fed-Credit: Robust Federated Learning with Credibility Management
Jiayan Chen, Zhirong Qian, Tianhui Meng, Xitong Gao, Tian Wang, Weijia Jia
Aiming at privacy preservation, Federated Learning (FL) is an emerging machine learning approach enabling model training on decentralized devices or data sources. The learning mechanism of FL relies on aggregating parameter updates from individual clients. However, this process may pose a potential security risk due to the presence of malicious devices. Existing solutions are either costly due to the use of compute-intensive technology, or restrictive for reasons of strong assumptions such as the prior knowledge of the number of attackers and how they attack. Few methods consider both privacy constraints and uncertain attack scenarios. In this paper, we propose a robust FL approach based on the credibility management scheme, called Fed-Credit. Unlike previous studies, our approach does not require prior knowledge of the nodes and the data distribution. It maintains and employs a credibility set, which weighs the historical clients' contributions based on the similarity between the local models and global model, to adjust the global model update. The subtlety of Fed-Credit is that the time decay and attitudinal value factor are incorporated into the dynamic adjustment of the reputation weights and it boasts a computational complexity of O(n) (n is the number of the clients). We conducted extensive experiments on the MNIST and CIFAR-10 datasets under 5 types of attacks. The results exhibit superior accuracy and resilience against adversarial attacks, all while maintaining comparatively low computational complexity. Among these, on the Non-IID CIFAR-10 dataset, our algorithm exhibited performance enhancements of 19.5% and 14.5%, respectively, in comparison to the state-of-the-art algorithm when dealing with two types of data poisoning attacks.
Read more5/21/2024
📊
0
Precision Guided Approach to Mitigate Data Poisoning Attacks in Federated Learning
K Naveen Kumar, C Krishna Mohan, Aravind Machiry
Federated Learning (FL) is a collaborative learning paradigm enabling participants to collectively train a shared machine learning model while preserving the privacy of their sensitive data. Nevertheless, the inherent decentralized and data-opaque characteristics of FL render its susceptibility to data poisoning attacks. These attacks introduce malformed or malicious inputs during local model training, subsequently influencing the global model and resulting in erroneous predictions. Current FL defense strategies against data poisoning attacks either involve a trade-off between accuracy and robustness or necessitate the presence of a uniformly distributed root dataset at the server. To overcome these limitations, we present FedZZ, which harnesses a zone-based deviating update (ZBDU) mechanism to effectively counter data poisoning attacks in FL. Further, we introduce a precision-guided methodology that actively characterizes these client clusters (zones), which in turn aids in recognizing and discarding malicious updates at the server. Our evaluation of FedZZ across two widely recognized datasets: CIFAR10 and EMNIST, demonstrate its efficacy in mitigating data poisoning attacks, surpassing the performance of prevailing state-of-the-art methodologies in both single and multi-client attack scenarios and varying attack volumes. Notably, FedZZ also functions as a robust client selection strategy, even in highly non-IID and attack-free scenarios. Moreover, in the face of escalating poisoning rates, the model accuracy attained by FedZZ displays superior resilience compared to existing techniques. For instance, when confronted with a 50% presence of malicious clients, FedZZ sustains an accuracy of 67.43%, while the accuracy of the second-best solution, FL-Defender, diminishes to 43.36%.
Read more4/8/2024

0
Robust Federated Learning Mitigates Client-side Training Data Distribution Inference Attacks
Yichang Xu, Ming Yin, Minghong Fang, Neil Zhenqiang Gong
Recent studies have revealed that federated learning (FL), once considered secure due to clients not sharing their private data with the server, is vulnerable to attacks such as client-side training data distribution inference, where a malicious client can recreate the victim's data. While various countermeasures exist, they are not practical, often assuming server access to some training data or knowledge of label distribution before the attack. In this work, we bridge the gap by proposing InferGuard, a novel Byzantine-robust aggregation rule aimed at defending against client-side training data distribution inference attacks. In our proposed InferGuard, the server first calculates the coordinate-wise median of all the model updates it receives. A client's model update is considered malicious if it significantly deviates from the computed median update. We conduct a thorough evaluation of our proposed InferGuard on five benchmark datasets and perform a comparison with ten baseline methods. The results of our experiments indicate that our defense mechanism is highly effective in protecting against client-side training data distribution inference attacks, even against strong adaptive attacks. Furthermore, our method substantially outperforms the baseline methods in various practical FL scenarios.
Read more4/5/2024