Multistep Consistency Models
2403.06807
0
0
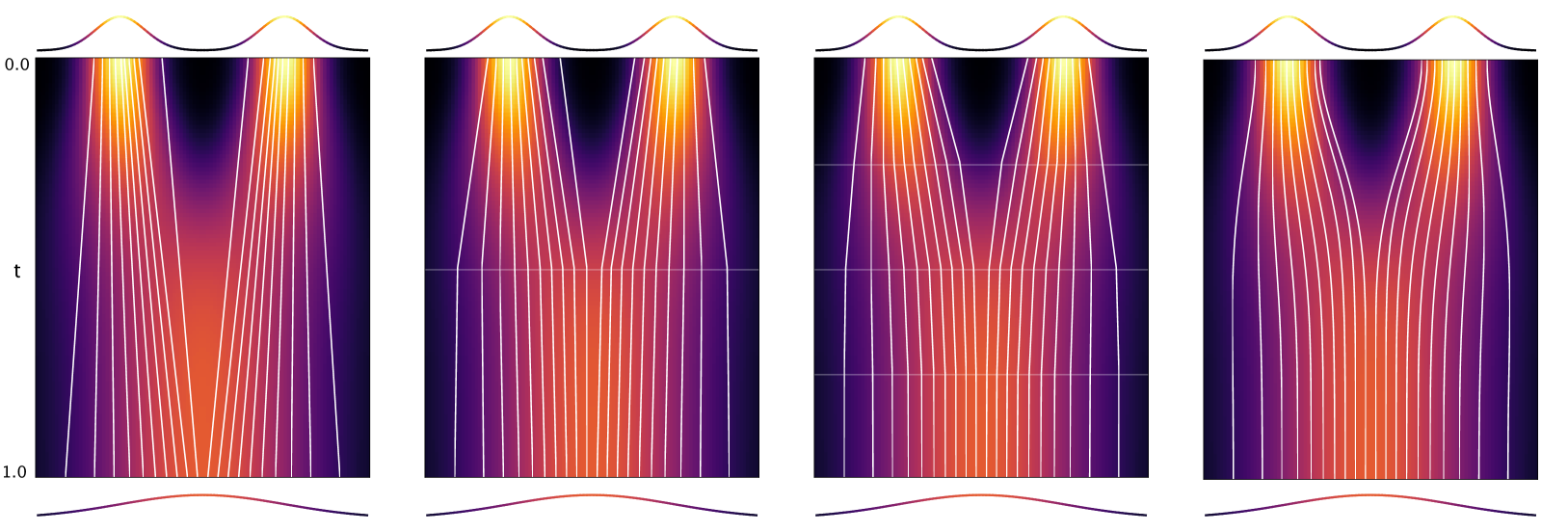
Abstract
Diffusion models are relatively easy to train but require many steps to generate samples. Consistency models are far more difficult to train, but generate samples in a single step. In this paper we propose Multistep Consistency Models: A unification between Consistency Models (Song et al., 2023) and TRACT (Berthelot et al., 2023) that can interpolate between a consistency model and a diffusion model: a trade-off between sampling speed and sampling quality. Specifically, a 1-step consistency model is a conventional consistency model whereas a $infty$-step consistency model is a diffusion model. Multistep Consistency Models work really well in practice. By increasing the sample budget from a single step to 2-8 steps, we can train models more easily that generate higher quality samples, while retaining much of the sampling speed benefits. Notable results are 1.4 FID on Imagenet 64 in 8 step and 2.1 FID on Imagenet128 in 8 steps with consistency distillation, using simple losses without adversarial training. We also show that our method scales to a text-to-image diffusion model, generating samples that are close to the quality of the original model.
Create account to get full access
Overview
- This paper introduces "multistep consistency models", a new approach to improving the training of diffusion models, which are a type of machine learning model used for tasks like image and audio generation.
- The key idea is to enforce consistency between the model's outputs at different steps of the diffusion process, which can lead to faster convergence and better final performance.
- The authors demonstrate the effectiveness of this approach through experiments on several benchmark datasets, showing improvements over standard diffusion models.
Plain English Explanation
Diffusion models are a powerful type of machine learning model that can be used to generate realistic images, audio, and other types of data. However, training these models can be slow and challenging. Multistep Consistency Models introduce a new approach to make the training process more efficient.
The core idea is to force the model to be "consistent" in its outputs as it goes through the different steps of the diffusion process. Imagine you're trying to draw a picture, and each step of the process involves adding a bit more detail. With a consistency model, the model would have to ensure that the details it adds at each step are coherent and align with the overall image, rather than just randomly adding elements.
By enforcing this consistency, the model is able to converge to a better solution more quickly, leading to improved performance on tasks like image and audio generation. The authors demonstrate this through experiments on several benchmark datasets, showing that their consistency-based approach outperforms standard diffusion models.
Technical Explanation
Diffusion models are a type of generative model that work by gradually adding noise to a clean input (e.g., an image) and then learning to reverse this process to generate new samples. The authors of this paper introduce "multistep consistency models", which aim to improve the training of diffusion models by enforcing consistency between the model's outputs at different steps of the diffusion process.
Specifically, the authors propose adding a consistency loss term to the standard diffusion model objective, which encourages the model to produce outputs at each step that are coherent with the outputs at other steps. This is achieved by introducing auxiliary consistency networks that are trained to predict the model's outputs at other steps, and the main diffusion model is trained to minimize the error between its outputs and the predictions of these consistency networks.
The authors evaluate their approach on several image and audio generation benchmarks, and demonstrate that multistep consistency models are able to achieve better performance than standard diffusion models, while also converging more quickly during training. They attribute these improvements to the model's ability to learn more coherent and semantically meaningful representations through the consistency constraint.
Critical Analysis
The authors present a compelling approach for improving the training of diffusion models, and the experimental results are promising. However, a few limitations and areas for further research are worth noting:
- The consistency networks introduced in the model add additional complexity and computational overhead, which could be a concern for applications with strict resource constraints.
- The authors primarily evaluate their approach on standard benchmark datasets, and it would be interesting to see how it performs on more diverse or real-world datasets, where the benefits of consistency may be even more pronounced.
- While the authors discuss the potential for the consistency approach to lead to more coherent and semantically meaningful representations, they do not provide a detailed analysis of the internal workings of the model or the specific mechanisms by which consistency is achieved. Towards Faster Training of Diffusion Models with Inspiration from Consistency and CTS: A Consistency-based Model for Medical Image Segmentation may offer additional insights in this direction.
Overall, the authors have presented an interesting and promising approach for improving diffusion models, and the work opens up several avenues for further research and exploration in this area.
Conclusion
This paper introduces "multistep consistency models", a novel approach for improving the training of diffusion models, a powerful class of generative models used for tasks like image and audio generation. By enforcing consistency between the model's outputs at different steps of the diffusion process, the authors demonstrate that they can achieve faster convergence and better final performance compared to standard diffusion models.
The key insight of this work is that encouraging the model to learn more coherent and semantically meaningful representations can lead to significant gains in efficiency and effectiveness. While the approach adds some additional complexity, the authors' experimental results suggest that the benefits outweigh the costs, making multistep consistency models a promising direction for further research and development in the field of generative modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MLCM: Multistep Consistency Distillation of Latent Diffusion Model
Qingsong Xie, Zhenyi Liao, Chen chen, Zhijie Deng, Shixiang Tang, Haonan Lu
0
0
Distilling large latent diffusion models (LDMs) into ones that are fast to sample from is attracting growing research interest. However, the majority of existing methods face a dilemma where they either (i) depend on multiple individual distilled models for different sampling budgets, or (ii) sacrifice generation quality with limited (e.g., 2-4) and/or moderate (e.g., 5-8) sampling steps. To address these, we extend the recent multistep consistency distillation (MCD) strategy to representative LDMs, establishing the Multistep Latent Consistency Models (MLCMs) approach for low-cost high-quality image synthesis. MLCM serves as a unified model for various sampling steps due to the promise of MCD. We further augment MCD with a progressive training strategy to strengthen inter-segment consistency to boost the quality of few-step generations. We take the states from the sampling trajectories of the teacher model as training data for MLCMs to lift the requirements for high-quality training datasets and to bridge the gap between the training and inference of the distilled model. MLCM is compatible with preference learning strategies for further improvement of visual quality and aesthetic appeal. Empirically, MLCM can generate high-quality, delightful images with only 2-8 sampling steps. On the MSCOCO-2017 5K benchmark, MLCM distilled from SDXL gets a CLIP Score of 33.30, Aesthetic Score of 6.19, and Image Reward of 1.20 with only 4 steps, substantially surpassing 4-step LCM [23], 8-step SDXL-Lightning [17], and 8-step HyperSD [33]. We also demonstrate the versatility of MLCMs in applications including controllable generation, image style transfer, and Chinese-to-image generation.
6/13/2024

Provable Statistical Rates for Consistency Diffusion Models
Zehao Dou, Minshuo Chen, Mengdi Wang, Zhuoran Yang
0
0
Diffusion models have revolutionized various application domains, including computer vision and audio generation. Despite the state-of-the-art performance, diffusion models are known for their slow sample generation due to the extensive number of steps involved. In response, consistency models have been developed to merge multiple steps in the sampling process, thereby significantly boosting the speed of sample generation without compromising quality. This paper contributes towards the first statistical theory for consistency models, formulating their training as a distribution discrepancy minimization problem. Our analysis yields statistical estimation rates based on the Wasserstein distance for consistency models, matching those of vanilla diffusion models. Additionally, our results encompass the training of consistency models through both distillation and isolation methods, demystifying their underlying advantage.
6/26/2024

Consistency Models Made Easy
Zhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, J. Zico Kolter
0
0
Consistency models (CMs) are an emerging class of generative models that offer faster sampling than traditional diffusion models. CMs enforce that all points along a sampling trajectory are mapped to the same initial point. But this target leads to resource-intensive training: for example, as of 2024, training a SoTA CM on CIFAR-10 takes one week on 8 GPUs. In this work, we propose an alternative scheme for training CMs, vastly improving the efficiency of building such models. Specifically, by expressing CM trajectories via a particular differential equation, we argue that diffusion models can be viewed as a special case of CMs with a specific discretization. We can thus fine-tune a consistency model starting from a pre-trained diffusion model and progressively approximate the full consistency condition to stronger degrees over the training process. Our resulting method, which we term Easy Consistency Tuning (ECT), achieves vastly improved training times while indeed improving upon the quality of previous methods: for example, ECT achieves a 2-step FID of 2.73 on CIFAR10 within 1 hour on a single A100 GPU, matching Consistency Distillation trained of hundreds of GPU hours. Owing to this computational efficiency, we investigate the scaling law of CMs under ECT, showing that they seem to obey classic power law scaling, hinting at their ability to improve efficiency and performance at larger scales. Code (https://github.com/locuslab/ect) is available.
6/21/2024

SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
Hongjian Liu, Qingsong Xie, Zhijie Deng, Chen Chen, Shixiang Tang, Fueyang Fu, Zheng-jun Zha, Haonan Lu
0
0
The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
4/16/2024