MMCL: Boosting Deformable DETR-Based Detectors with Multi-Class Min-Margin Contrastive Learning for Superior Prohibited Item Detection

0

Sign in to get full access
Overview
- This paper provides formatting instructions for the NeurIPS 2024 conference.
- It covers important details like page limits, font sizes, margin requirements, and other formatting specifications.
- The instructions ensure a consistent and professional-looking presentation of research papers at the conference.
Plain English Explanation
The NeurIPS 2024 formatting instructions outline the specific guidelines authors must follow when submitting their research papers to the conference. This includes things like the maximum number of pages allowed, the required font type and size, the dimensions of the page margins, and how figures and references should be formatted.
These standards help create a uniform appearance for all the papers presented at NeurIPS. This makes it easier for attendees to focus on the content of the research rather than being distracted by inconsistent formatting. It also ensures the proceedings have a professional, polished look that reflects well on the conference.
Following these formatting rules is an important part of getting a paper accepted to NeurIPS. Authors need to make sure their submission meets all the specified criteria in order to be considered. The instructions provide clear, step-by-step guidance to help authors prepare their papers correctly.
Technical Explanation
The NeurIPS 2024 formatting instructions cover a variety of formatting requirements for paper submissions. This includes:
- Page Limits: Papers are limited to 8 pages of content, plus an optional 2 pages for references and appendices.
- Font and Spacing: The required font is Times New Roman, with a size of 11 points and 1.5 line spacing.
- Margins: All page margins must be at least 1 inch (2.54 cm) on all sides.
- Figures and Tables: Figures and tables must be included within the page count and should be of high quality.
- References: References should be formatted using the NeurIPS reference style.
The instructions also provide guidance on how to prepare the paper for electronic submission, including file naming conventions and necessary metadata.
Critical Analysis
The NeurIPS 2024 formatting instructions are comprehensive and well-designed to ensure a consistent look and feel for the conference proceedings. The requirements strike a reasonable balance between providing clear guidelines and allowing authors some flexibility in their paper layout and presentation.
One potential limitation is the strict page limit, which may make it challenging for authors to include all the necessary details and supporting information in their submissions. However, this constraint also encourages authors to be concise and focus on the most important aspects of their work.
Additionally, the instructions do not address the accessibility of the papers, such as ensuring the text and figures are readable for attendees with visual impairments. This is an area that could be improved in future versions of the guidelines.
Overall, the NeurIPS 2024 formatting instructions are well-crafted and serve the important purpose of maintaining the high quality and professional appearance of the conference.
Conclusion
The NeurIPS 2024 formatting instructions provide clear and detailed guidance to authors on how to properly format their research papers for submission to the conference. These standards help ensure a consistent, professional-looking presentation of the work, allowing attendees to focus on the content rather than being distracted by inconsistent formatting.
By following these instructions, authors can increase the likelihood of their papers being accepted and well-received at the prestigious NeurIPS conference. The formatting requirements strike a balance between providing clear guidelines and allowing authors some flexibility in their paper layout and design.
Overall, the NeurIPS 2024 formatting instructions are an important part of the submission process, helping to uphold the high quality and professional reputation of the conference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MMCL: Boosting Deformable DETR-Based Detectors with Multi-Class Min-Margin Contrastive Learning for Superior Prohibited Item Detection
Mingyuan Li, Tong Jia, Hui Lu, Bowen Ma, Hao Wang, Dongyue Chen
Prohibited Item detection in X-ray images is one of the most effective security inspection methods.However, differing from natural light images, the unique overlapping phenomena in X-ray images lead to the coupling of foreground and background features, thereby lowering the accuracy of general object detectors.Therefore, we propose a Multi-Class Min-Margin Contrastive Learning (MMCL) method that, by clarifying the category semantic information of content queries under the deformable DETR architecture, aids the model in extracting specific category foreground information from coupled features.Specifically, after grouping content queries by the number of categories, we employ the Multi-Class Inter-Class Exclusion (MIE) loss to push apart content queries from different groups. Concurrently, the Intra-Class Min-Margin Clustering (IMC) loss is utilized to attract content queries within the same group, while ensuring the preservation of necessary disparity. As training, the inherent Hungarian matching of the model progressively strengthens the alignment between each group of queries and the semantic features of their corresponding category of objects. This evolving coherence ensures a deep-seated grasp of category characteristics, consequently bolstering the anti-overlapping detection capabilities of models.MMCL is versatile and can be easily plugged into any deformable DETR-based model with dozens of lines of code. Extensive experiments on the PIXray and OPIXray datasets demonstrate that MMCL significantly enhances the performance of various state-of-the-art models without increasing complexity. The code has been released at https://github.com/anonymity0403/MMCL.
Read more6/6/2024

0
ProbMCL: Simple Probabilistic Contrastive Learning for Multi-label Visual Classification
Ahmad Sajedi, Samir Khaki, Yuri A. Lawryshyn, Konstantinos N. Plataniotis
Multi-label image classification presents a challenging task in many domains, including computer vision and medical imaging. Recent advancements have introduced graph-based and transformer-based methods to improve performance and capture label dependencies. However, these methods often include complex modules that entail heavy computation and lack interpretability. In this paper, we propose Probabilistic Multi-label Contrastive Learning (ProbMCL), a novel framework to address these challenges in multi-label image classification tasks. Our simple yet effective approach employs supervised contrastive learning, in which samples that share enough labels with an anchor image based on a decision threshold are introduced as a positive set. This structure captures label dependencies by pulling positive pair embeddings together and pushing away negative samples that fall below the threshold. We enhance representation learning by incorporating a mixture density network into contrastive learning and generating Gaussian mixture distributions to explore the epistemic uncertainty of the feature encoder. We validate the effectiveness of our framework through experimentation with datasets from the computer vision and medical imaging domains. Our method outperforms the existing state-of-the-art methods while achieving a low computational footprint on both datasets. Visualization analyses also demonstrate that ProbMCL-learned classifiers maintain a meaningful semantic topology.
Read more4/15/2024
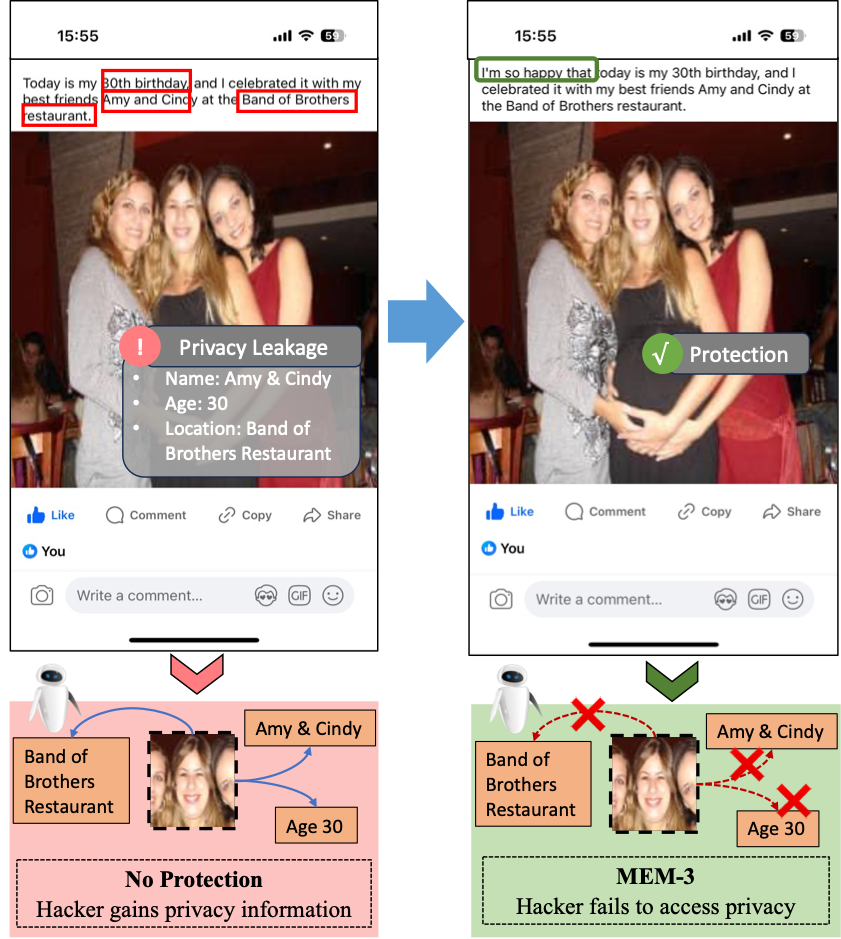
0
Multimodal Unlearnable Examples: Protecting Data against Multimodal Contrastive Learning
Xinwei Liu, Xiaojun Jia, Yuan Xun, Siyuan Liang, Xiaochun Cao
Multimodal contrastive learning (MCL) has shown remarkable advances in zero-shot classification by learning from millions of image-caption pairs crawled from the Internet. However, this reliance poses privacy risks, as hackers may unauthorizedly exploit image-text data for model training, potentially including personal and privacy-sensitive information. Recent works propose generating unlearnable examples by adding imperceptible perturbations to training images to build shortcuts for protection. However, they are designed for unimodal classification, which remains largely unexplored in MCL. We first explore this context by evaluating the performance of existing methods on image-caption pairs, and they do not generalize effectively to multimodal data and exhibit limited impact to build shortcuts due to the lack of labels and the dispersion of pairs in MCL. In this paper, we propose Multi-step Error Minimization (MEM), a novel optimization process for generating multimodal unlearnable examples. It extends the Error-Minimization (EM) framework to optimize both image noise and an additional text trigger, thereby enlarging the optimized space and effectively misleading the model to learn the shortcut between the noise features and the text trigger. Specifically, we adopt projected gradient descent to solve the noise minimization problem and use HotFlip to approximate the gradient and replace words to find the optimal text trigger. Extensive experiments demonstrate the effectiveness of MEM, with post-protection retrieval results nearly half of random guessing, and its high transferability across different models. Our code is available on the https://github.com/thinwayliu/Multimodal-Unlearnable-Examples
Read more7/29/2024

0
Multimodal Multilabel Classification by CLIP
Yanming Guo
Multimodal multilabel classification (MMC) is a challenging task that aims to design a learning algorithm to handle two data sources, the image and text, and learn a comprehensive semantic feature presentation across the modalities. In this task, we review the extensive number of state-of-the-art approaches in MMC and leverage a novel technique that utilises the Contrastive Language-Image Pre-training (CLIP) as the feature extractor and fine-tune the model by exploring different classification heads, fusion methods and loss functions. Finally, our best result achieved more than 90% F_1 score in the public Kaggle competition leaderboard. This paper provides detailed descriptions of novel training methods and quantitative analysis through the experimental results.
Read more6/26/2024