Model Predictive Control and Reinforcement Learning: A Unified Framework Based on Dynamic Programming
2406.00592
0
0

Abstract
In this paper we describe a new conceptual framework that connects approximate Dynamic Programming (DP), Model Predictive Control (MPC), and Reinforcement Learning (RL). This framework centers around two algorithms, which are designed largely independently of each other and operate in synergy through the powerful mechanism of Newton's method. We call them the off-line training and the on-line play algorithms. The names are borrowed from some of the major successes of RL involving games; primary examples are the recent (2017) AlphaZero program (which plays chess, [SHS17], [SSS17]), and the similarly structured and earlier (1990s) TD-Gammon program (which plays backgammon, [Tes94], [Tes95], [TeG96]). In these game contexts, the off-line training algorithm is the method used to teach the program how to evaluate positions and to generate good moves at any given position, while the on-line play algorithm is the method used to play in real time against human or computer opponents. Significantly, the synergy between off-line training and on-line play also underlies MPC (as well as other major classes of sequential decision problems), and indeed the MPC design architecture is very similar to the one of AlphaZero and TD-Gammon. This conceptual insight provides a vehicle for bridging the cultural gap between RL and MPC, and sheds new light on some fundamental issues in MPC. These include the enhancement of stability properties through rollout, the treatment of uncertainty through the use of certainty equivalence, the resilience of MPC in adaptive control settings that involve changing system parameters, and the insights provided by the superlinear performance bounds implied by Newton's method.
Create account to get full access
Overview
- The paper proposes a unified framework for Model Predictive Control (MPC) and Reinforcement Learning (RL) based on dynamic programming.
- It shows how MPC and RL can be formulated as special cases of the proposed dynamic programming framework.
- The framework provides a systematic way to derive RL algorithms from MPC concepts and vice versa.
Plain English Explanation
This paper tries to find a common ground between two important fields in machine learning and control systems: Model Predictive Control (MPC) and Reinforcement Learning (RL). MPC is a control technique that uses a model of the system to predict future behavior and optimize the control actions. RL, on the other hand, is a learning algorithm that discovers optimal actions by interacting with the environment and receiving rewards.
The key insight of this paper is that both MPC and RL can be seen as special cases of a more general dynamic programming framework. Dynamic programming is a mathematical technique for solving complex optimization problems by breaking them down into smaller, simpler subproblems.
By framing MPC and RL within this dynamic programming perspective, the authors show how the two approaches are closely related. In fact, they demonstrate that it's possible to derive RL algorithms directly from MPC concepts, and vice versa. This unified view not only helps us better understand the underlying connections between the two fields, but also opens up new possibilities for developing hybrid MPC-RL algorithms that combine the strengths of both approaches.
The paper also provides a systematic way to design MPC-inspired RL algorithms and RL-inspired MPC algorithms, potentially leading to more efficient and effective solutions for a wide range of control and decision-making problems.
Technical Explanation
The paper starts by formulating a general MPC problem, which involves optimizing a cost function over a finite horizon while respecting system dynamics and constraints. The authors then show how this MPC problem can be reformulated as a dynamic programming problem, where the value function plays a central role.
Next, the paper demonstrates that RL can also be cast as a dynamic programming problem, where the goal is to learn the optimal value function through interaction with the environment. By drawing parallels between the MPC and RL formulations, the authors establish a unified framework that encompasses both approaches.
Within this framework, the authors derive several novel algorithms. For example, they show how to derive RL algorithms directly from MPC concepts, such as by using the MPC value function as a proxy for the RL value function. Conversely, they also demonstrate how to derive MPC algorithms from RL, such as by incorporating RL-based trust regions into the MPC optimization.
The paper also provides theoretical analysis to establish the convergence and optimality properties of the proposed algorithms. Numerical experiments on several control and decision-making problems further validate the effectiveness of the unified framework.
Critical Analysis
The paper presents a compelling and well-structured approach to unifying MPC and RL within a dynamic programming framework. The authors have done an excellent job of highlighting the underlying connections between the two fields and demonstrating the benefits of this unified view.
One potential caveat is that the theoretical analysis in the paper relies on several simplifying assumptions, such as the existence of a known system model and the ability to solve the dynamic programming problem exactly. In practical applications, these assumptions may not always hold, and the performance of the proposed algorithms may be affected.
Additionally, the paper does not delve into the computational complexity of the derived algorithms, which could be an important consideration, especially for real-time applications. Further research may be needed to address these practical issues and explore the scalability of the proposed framework.
It would also be interesting to see the authors expand on the potential challenges and limitations of their approach, as well as possible directions for future work. For example, the paper does not discuss how the framework might handle partial observability, multi-agent systems, or other advanced RL settings.
Overall, the paper presents a compelling and insightful contribution to the field of control and decision-making, and the proposed unified framework has the potential to spur further advances in the integration of MPC and RL techniques.
Conclusion
This paper proposes a unifying dynamic programming framework that encompasses both Model Predictive Control (MPC) and Reinforcement Learning (RL). By drawing parallels between the two approaches, the authors establish a systematic way to derive RL algorithms from MPC concepts and vice versa.
The key benefit of this unified framework is that it helps us better understand the underlying connections between MPC and RL, opening up new possibilities for developing hybrid algorithms that combine the strengths of both approaches. The paper provides several concrete examples of how this can be done, such as using MPC-based value functions in RL or incorporating RL-based trust regions into MPC optimization.
While the paper relies on some simplifying assumptions, the overall approach represents an important step forward in the integration of control and learning techniques. By fostering cross-pollination between the MPC and RL communities, this work has the potential to lead to more efficient and effective solutions for a wide range of control and decision-making problems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
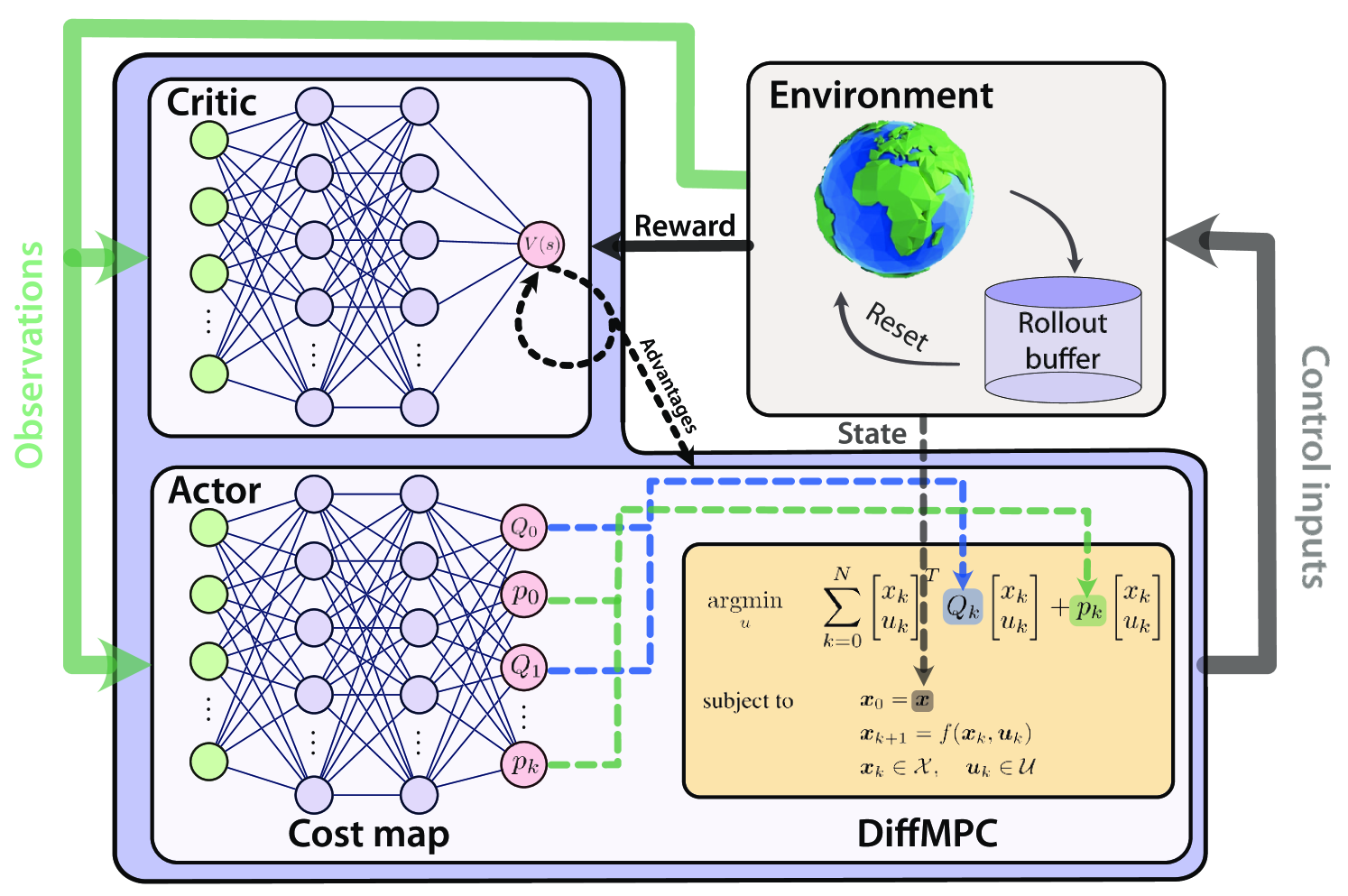
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
0
0
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
4/15/2024
🏅
MPC-Inspired Reinforcement Learning for Verifiable Model-Free Control
Yiwen Lu, Zishuo Li, Yihan Zhou, Na Li, Yilin Mo
0
0
In this paper, we introduce a new class of parameterized controllers, drawing inspiration from Model Predictive Control (MPC). The controller resembles a Quadratic Programming (QP) solver of a linear MPC problem, with the parameters of the controller being trained via Deep Reinforcement Learning (DRL) rather than derived from system models. This approach addresses the limitations of common controllers with Multi-Layer Perceptron (MLP) or other general neural network architecture used in DRL, in terms of verifiability and performance guarantees, and the learned controllers possess verifiable properties like persistent feasibility and asymptotic stability akin to MPC. On the other hand, numerical examples illustrate that the proposed controller empirically matches MPC and MLP controllers in terms of control performance and has superior robustness against modeling uncertainty and noises. Furthermore, the proposed controller is significantly more computationally efficient compared to MPC and requires fewer parameters to learn than MLP controllers. Real-world experiments on vehicle drift maneuvering task demonstrate the potential of these controllers for robotics and other demanding control tasks.
4/10/2024
A Pontryagin Perspective on Reinforcement Learning
Onno Eberhard, Claire Vernade, Michael Muehlebach
0
0
Reinforcement learning has traditionally focused on learning state-dependent policies to solve optimal control problems in a closed-loop fashion. In this work, we introduce the paradigm of open-loop reinforcement learning where a fixed action sequence is learned instead. We present three new algorithms: one robust model-based method and two sample-efficient model-free methods. Rather than basing our algorithms on Bellman's equation from dynamic programming, our work builds on Pontryagin's principle from the theory of open-loop optimal control. We provide convergence guarantees and evaluate all methods empirically on a pendulum swing-up task, as well as on two high-dimensional MuJoCo tasks, demonstrating remarkable performance compared to existing baselines.
5/29/2024
📈
Model predictive control-based value estimation for efficient reinforcement learning
Qizhen Wu, Kexin Liu, Lei Chen
0
0
Reinforcement learning suffers from limitations in real practices primarily due to the number of required interactions with virtual environments. It results in a challenging problem because we are implausible to obtain a local optimal strategy with only a few attempts for many learning methods. Hereby, we design an improved reinforcement learning method based on model predictive control that models the environment through a data-driven approach. Based on the learned environment model, it performs multi-step prediction to estimate the value function and optimize the policy. The method demonstrates higher learning efficiency, faster convergent speed of strategies tending to the local optimal value, and less sample capacity space required by experience replay buffers. Experimental results, both in classic databases and in a dynamic obstacle avoidance scenario for an unmanned aerial vehicle, validate the proposed approaches.
4/12/2024