Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models

0
🏋️
Sign in to get full access
Overview
- The paper examines the learning dynamics of over-parameterized deep learning models, which are computationally expensive to train.
- It introduces a novel concept called the "modular neural tangent kernel" (mNTK) to describe the learning capabilities of individual network modules, such as the heads in self-attention models.
- The paper proposes a new training strategy called "Modular Adaptive Training" (MAT) that selectively updates modules based on their mNTK's principal eigenvalue, leading to significant computational savings and improved performance.
Plain English Explanation
Deep learning models with a large number of parameters, known as "over-parameterized" models, can be very powerful, but they also require a lot of computational resources to train properly. This paper explores a way to understand the learning patterns of individual components, or "modules," within these complex models.
The researchers introduce a new concept called the "modular neural tangent kernel" (mNTK), which helps them measure how well each module is learning. They find that modules with a higher mNTK value tend to learn features more effectively, while those with lower values may actually hurt the model's overall performance.
Inspired by this discovery, the researchers propose a new training strategy called "Modular Adaptive Training" (MAT). Instead of updating all the modules in the model at the same rate, MAT selectively updates the modules with the highest mNTK values, while ignoring the less-important ones. This approach significantly reduces the computational cost of training the model, while also improving its accuracy compared to traditional training methods.
Technical Explanation
The paper starts by acknowledging the prevalence of over-parameterized deep learning models, which can be computationally expensive to train properly. To better understand the learning dynamics of these models, the researchers take a "fine-grained, modular-level" approach, analyzing the behavior of individual network modules, such as the heads in self-attention models.
Through empirical evidence, the authors discover that the learning patterns of these modules can vary widely, with some learning features more effectively than others. To quantify this, they introduce a new concept called the "modular neural tangent kernel" (mNTK), which is a measure of a module's learning capability.
The key insight is that the quality of a module's learning is closely tied to the principal eigenvalue (λ_max) of its mNTK. Modules with a larger λ_max tend to learn features more quickly and effectively, while those with smaller values may negatively impact the model's overall generalization performance.
Motivated by this discovery, the researchers propose a novel training strategy called "Modular Adaptive Training" (MAT). Instead of updating all modules at the same rate during training, MAT selectively updates only the modules with an mNTK λ_max above a dynamic threshold, while ignoring the less important ones. This "partially-updating" approach can significantly reduce the computational cost of training, while also improving the model's accuracy compared to traditional training methods.
Critical Analysis
The paper presents a thoughtful and well-designed approach to understanding the learning dynamics of over-parameterized deep learning models. The introduction of the mNTK concept is a novel contribution that provides a principled way to assess the learning capabilities of individual network modules.
One potential limitation of the research is that it focuses primarily on self-attention models, and it's unclear how well the mNTK and MAT strategies would generalize to other types of deep learning architectures. Additionally, the paper does not delve into the theoretical underpinnings of the mNTK and its relationship to other well-known concepts in machine learning, such as the neural tangent kernel or the attention mechanism.
That said, the experimental results presented in the paper are quite compelling, and the proposed Modular Adaptive Training strategy represents a promising direction for improving the efficiency and performance of over-parameterized deep learning models. The approach could potentially be combined with other modular training or multi-level learning techniques to further enhance its capabilities.
Conclusion
This paper provides a novel and insightful approach to understanding the learning dynamics of over-parameterized deep learning models. By introducing the concept of the modular neural tangent kernel (mNTK) and proposing the Modular Adaptive Training (MAT) strategy, the researchers have developed a way to significantly reduce the computational cost of training these complex models while also improving their overall performance.
The findings in this paper have the potential to inform the development of more efficient and effective deep learning architectures, particularly in domains where computational resources are limited. As the field of AI continues to advance, research that explores ways to make deep learning models more accessible and practical will become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models
Yubin Shi, Yixuan Chen, Mingzhi Dong, Xiaochen Yang, Dongsheng Li, Yujiang Wang, Robert P. Dick, Qin Lv, Yingying Zhao, Fan Yang, Tun Lu, Ning Gu, Li Shang
Despite their prevalence in deep-learning communities, over-parameterized models convey high demands of computational costs for proper training. This work studies the fine-grained, modular-level learning dynamics of over-parameterized models to attain a more efficient and fruitful training strategy. Empirical evidence reveals that when scaling down into network modules, such as heads in self-attention models, we can observe varying learning patterns implicitly associated with each module's trainability. To describe such modular-level learning capabilities, we introduce a novel concept dubbed modular neural tangent kernel (mNTK), and we demonstrate that the quality of a module's learning is tightly associated with its mNTK's principal eigenvalue $lambda_{max}$. A large $lambda_{max}$ indicates that the module learns features with better convergence, while those miniature ones may impact generalization negatively. Inspired by the discovery, we propose a novel training strategy termed Modular Adaptive Training (MAT) to update those modules with their $lambda_{max}$ exceeding a dynamic threshold selectively, concentrating the model on learning common features and ignoring those inconsistent ones. Unlike most existing training schemes with a complete BP cycle across all network modules, MAT can significantly save computations by its partially-updating strategy and can further improve performance. Experiments show that MAT nearly halves the computational cost of model training and outperforms the accuracy of baselines.
Read more5/14/2024

0
Breaking Neural Network Scaling Laws with Modularity
Akhilan Boopathy, Sunshine Jiang, William Yue, Jaedong Hwang, Abhiram Iyer, Ila Fiete
Modular neural networks outperform nonmodular neural networks on tasks ranging from visual question answering to robotics. These performance improvements are thought to be due to modular networks' superior ability to model the compositional and combinatorial structure of real-world problems. However, a theoretical explanation of how modularity improves generalizability, and how to leverage task modularity while training networks remains elusive. Using recent theoretical progress in explaining neural network generalization, we investigate how the amount of training data required to generalize on a task varies with the intrinsic dimensionality of a task's input. We show theoretically that when applied to modularly structured tasks, while nonmodular networks require an exponential number of samples with task dimensionality, modular networks' sample complexity is independent of task dimensionality: modular networks can generalize in high dimensions. We then develop a novel learning rule for modular networks to exploit this advantage and empirically show the improved generalization of the rule, both in- and out-of-distribution, on high-dimensional, modular tasks.
Read more9/10/2024
0
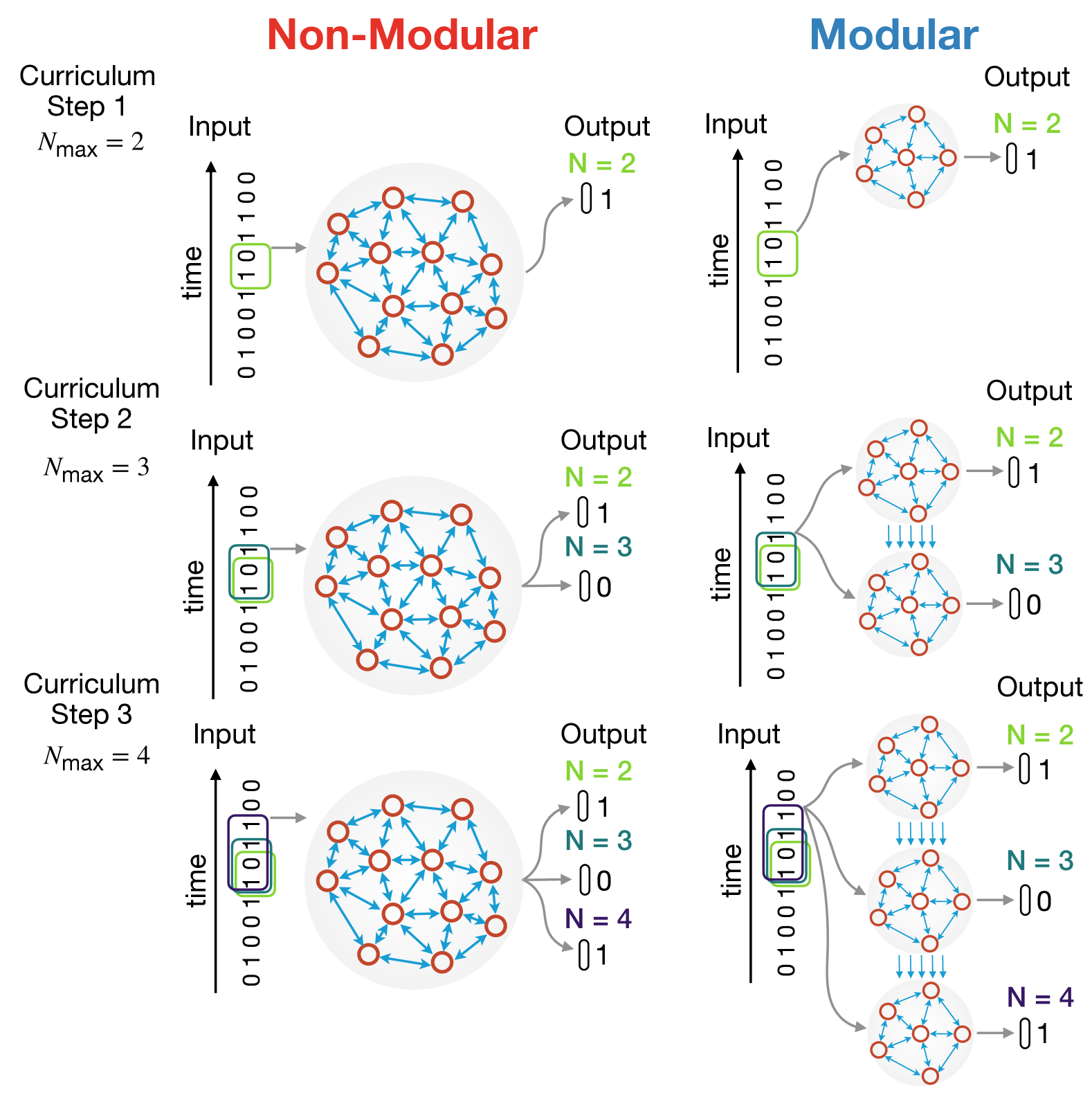
Modular Growth of Hierarchical Networks: Efficient, General, and Robust Curriculum Learning
Mani Hamidi, Sina Khajehabdollahi, Emmanouil Giannakakis, Tim Schafer, Anna Levina, Charley M. Wu
Structural modularity is a pervasive feature of biological neural networks, which have been linked to several functional and computational advantages. Yet, the use of modular architectures in artificial neural networks has been relatively limited despite early successes. Here, we explore the performance and functional dynamics of a modular network trained on a memory task via an iterative growth curriculum. We find that for a given classical, non-modular recurrent neural network (RNN), an equivalent modular network will perform better across multiple metrics, including training time, generalizability, and robustness to some perturbations. We further examine how different aspects of a modular network's connectivity contribute to its computational capability. We then demonstrate that the inductive bias introduced by the modular topology is strong enough for the network to perform well even when the connectivity within modules is fixed and only the connections between modules are trained. Our findings suggest that gradual modular growth of RNNs could provide advantages for learning increasingly complex tasks on evolutionary timescales, and help build more scalable and compressible artificial networks.
Read more6/11/2024
🐍
0
The lazy (NTK) and rich ($mu$P) regimes: a gentle tutorial
Dhruva Karkada
A central theme of the modern machine learning paradigm is that larger neural networks achieve better performance on a variety of metrics. Theoretical analyses of these overparameterized models have recently centered around studying very wide neural networks. In this tutorial, we provide a nonrigorous but illustrative derivation of the following fact: in order to train wide networks effectively, there is only one degree of freedom in choosing hyperparameters such as the learning rate and the size of the initial weights. This degree of freedom controls the richness of training behavior: at minimum, the wide network trains lazily like a kernel machine, and at maximum, it exhibits feature learning in the so-called $mu$P regime. In this paper, we explain this richness scale, synthesize recent research results into a coherent whole, offer new perspectives and intuitions, and provide empirical evidence supporting our claims. In doing so, we hope to encourage further study of the richness scale, as it may be key to developing a scientific theory of feature learning in practical deep neural networks.
Read more5/1/2024