MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning

56
🏅
Sign in to get full access
Overview
- Introduced MOMAland, the first collection of standardized environments for multi-objective multi-agent reinforcement learning (MOMARL)
- MOMARL broadens reinforcement learning (RL) to problems with multiple agents, each needing to consider multiple objectives
- Benchmarks are crucial for facilitating progress, evaluation, and reproducibility in RL research
- MOMAland addresses the need for comprehensive benchmarking in the MOMARL field, offering over 10 diverse environments
Plain English Explanation
Multi-objective multi-agent reinforcement learning (MOMARL) is a way to approach complex decision-making problems that involve multiple goals and multiple independent decision-makers. This could include managing traffic systems, electricity grids, or supply chains, where you need to balance different objectives and coordinate the actions of various parties.
The researchers introduced MOMAland, the first set of standardized environments specifically designed for MOMARL. This is important because benchmarks are crucial for making progress in reinforcement learning research. They allow researchers to evaluate and compare different approaches on common tasks.
MOMAland provides over 10 diverse environments that vary in the number of agents, the way the state is represented, the reward structure, and the different objectives that need to be balanced. This diversity helps ensure that MOMARL techniques are tested on a wide range of relevant problems. The researchers also included algorithms that can be used as baselines for future research in this area.
Technical Explanation
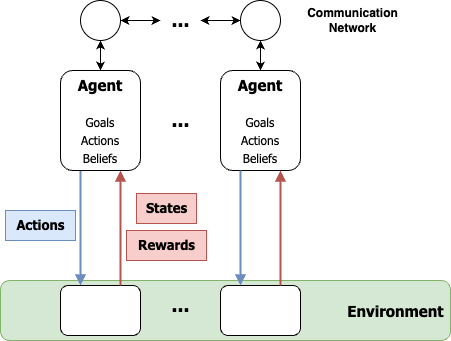
The paper introduces MOMAland, a collection of standardized environments for multi-objective multi-agent reinforcement learning (MOMARL). MOMARL extends reinforcement learning to problems with multiple agents, each of which must consider multiple objectives in their learning process.
The environments in MOMAland vary in terms of the number of agents, the state representations, the reward structures, and the utility considerations. This diversity is intended to facilitate comprehensive benchmarking and evaluation of MOMARL algorithms. The paper also includes several baseline algorithms that can be used to establish performance levels on the MOMAland environments.
The design of the MOMAland environments draws inspiration from real-world problems like traffic management, electricity grid operation, and supply chain coordination, which often involve complex decision-making processes that must balance multiple, potentially conflicting objectives.
Critical Analysis
The paper introduces a valuable benchmark suite for the emerging field of MOMARL. By providing a diverse set of standardized environments, MOMAland can help drive progress and facilitate comparison of different MOMARL algorithms.
However, the paper does not delve into the specific details of the environment designs or the baseline algorithms provided. More information on these aspects would be helpful for researchers looking to fully understand and utilize the MOMAland benchmark.
Additionally, the paper does not address potential limitations or challenges in applying MOMARL techniques to real-world problems. Further research may be needed to understand the practical implications and scalability of MOMARL approaches.
Conclusion
The introduction of MOMAland, the first comprehensive benchmark for multi-objective multi-agent reinforcement learning, represents an important step in advancing this emerging field. By providing a diverse set of standardized environments and baseline algorithms, the researchers have created a valuable tool for facilitating progress, evaluation, and reproducibility in MOMARL research. This benchmark can help drive the development of more effective techniques for tackling complex, real-world decision-making problems that involve multiple objectives and independent agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
56
MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning
Florian Felten, Umut Ucak, Hicham Azmani, Gao Peng, Willem Ropke, Hendrik Baier, Patrick Mannion, Diederik M. Roijers, Jordan K. Terry, El-Ghazali Talbi, Gr'egoire Danoy, Ann Now'e, Roxana Ru{a}dulescu
Many challenging tasks such as managing traffic systems, electricity grids, or supply chains involve complex decision-making processes that must balance multiple conflicting objectives and coordinate the actions of various independent decision-makers (DMs). One perspective for formalising and addressing such tasks is multi-objective multi-agent reinforcement learning (MOMARL). MOMARL broadens reinforcement learning (RL) to problems with multiple agents each needing to consider multiple objectives in their learning process. In reinforcement learning research, benchmarks are crucial in facilitating progress, evaluation, and reproducibility. The significance of benchmarks is underscored by the existence of numerous benchmark frameworks developed for various RL paradigms, including single-agent RL (e.g., Gymnasium), multi-agent RL (e.g., PettingZoo), and single-agent multi-objective RL (e.g., MO-Gymnasium). To support the advancement of the MOMARL field, we introduce MOMAland, the first collection of standardised environments for multi-objective multi-agent reinforcement learning. MOMAland addresses the need for comprehensive benchmarking in this emerging field, offering over 10 diverse environments that vary in the number of agents, state representations, reward structures, and utility considerations. To provide strong baselines for future research, MOMAland also includes algorithms capable of learning policies in such settings.
Read more7/24/2024
🏅
0
BenchMARL: Benchmarking Multi-Agent Reinforcement Learning
Matteo Bettini, Amanda Prorok, Vincent Moens
The field of Multi-Agent Reinforcement Learning (MARL) is currently facing a reproducibility crisis. While solutions for standardized reporting have been proposed to address the issue, we still lack a benchmarking tool that enables standardization and reproducibility, while leveraging cutting-edge Reinforcement Learning (RL) implementations. In this paper, we introduce BenchMARL, the first MARL training library created to enable standardized benchmarking across different algorithms, models, and environments. BenchMARL uses TorchRL as its backend, granting it high performance and maintained state-of-the-art implementations while addressing the broad community of MARL PyTorch users. Its design enables systematic configuration and reporting, thus allowing users to create and run complex benchmarks from simple one-line inputs. BenchMARL is open-sourced on GitHub: https://github.com/facebookresearch/BenchMARL
Read more7/8/2024
0
Multi-agent Reinforcement Learning: A Comprehensive Survey
Dom Huh, Prasant Mohapatra
Multi-agent systems (MAS) are widely prevalent and crucially important in numerous real-world applications, where multiple agents must make decisions to achieve their objectives in a shared environment. Despite their ubiquity, the development of intelligent decision-making agents in MAS poses several open challenges to their effective implementation. This survey examines these challenges, placing an emphasis on studying seminal concepts from game theory (GT) and machine learning (ML) and connecting them to recent advancements in multi-agent reinforcement learning (MARL), i.e. the research of data-driven decision-making within MAS. Therefore, the objective of this survey is to provide a comprehensive perspective along the various dimensions of MARL, shedding light on the unique opportunities that are presented in MARL applications while highlighting the inherent challenges that accompany this potential. Therefore, we hope that our work will not only contribute to the field by analyzing the current landscape of MARL but also motivate future directions with insights for deeper integration of concepts from related domains of GT and ML. With this in mind, this work delves into a detailed exploration of recent and past efforts of MARL and its related fields and describes prior solutions that were proposed and their limitations, as well as their applications.
Read more7/4/2024

0
POGEMA: A Benchmark Platform for Cooperative Multi-Agent Navigation
Alexey Skrynnik, Anton Andreychuk, Anatolii Borzilov, Alexander Chernyavskiy, Konstantin Yakovlev, Aleksandr Panov
Multi-agent reinforcement learning (MARL) has recently excelled in solving challenging cooperative and competitive multi-agent problems in various environments with, mostly, few agents and full observability. Moreover, a range of crucial robotics-related tasks, such as multi-robot navigation and obstacle avoidance, that have been conventionally approached with the classical non-learnable methods (e.g., heuristic search) is currently suggested to be solved by the learning-based or hybrid methods. Still, in this domain, it is hard, not to say impossible, to conduct a fair comparison between classical, learning-based, and hybrid approaches due to the lack of a unified framework that supports both learning and evaluation. To this end, we introduce POGEMA, a set of comprehensive tools that includes a fast environment for learning, a generator of problem instances, the collection of pre-defined ones, a visualization toolkit, and a benchmarking tool that allows automated evaluation. We introduce and specify an evaluation protocol defining a range of domain-related metrics computed on the basics of the primary evaluation indicators (such as success rate and path length), allowing a fair multi-fold comparison. The results of such a comparison, which involves a variety of state-of-the-art MARL, search-based, and hybrid methods, are presented.
Read more7/23/2024