POGEMA: A Benchmark Platform for Cooperative Multi-Agent Navigation

0

Sign in to get full access
Overview
- POGEMA is a benchmark platform for evaluating cooperative multi-agent navigation tasks.
- It provides a realistic 3D environment with configurable obstacles and agent dynamics.
- POGEMA enables the evaluation of multi-agent navigation algorithms across a variety of challenging scenarios.
Plain English Explanation
POGEMA is a testing ground for evaluating how well different AI systems can work together to navigate through complex environments. It creates a 3D virtual world with obstacles and different types of agents that have to coordinate their movements to reach their goals. This allows researchers to measure the performance of cooperative multi-agent navigation algorithms in realistic yet customizable scenarios. By having a standardized platform like POGEMA, it becomes easier to compare the strengths and weaknesses of various approaches to this challenging problem.
Technical Explanation
POGEMA is a benchmark platform designed to assess the performance of cooperative multi-agent navigation algorithms. It provides a realistic 3D simulated environment with configurable obstacles, agent dynamics, and other parameters. The platform supports the evaluation of a variety of challenging multi-agent navigation tasks, such as collision avoidance, formation control, and shared goal achievement. POGEMA includes tools for generating diverse scenarios, visualizing agent behavior, and collecting detailed performance metrics. This standardized evaluation platform enables systematic comparisons between different multi-agent navigation approaches.
Critical Analysis
The paper provides a thorough description of the POGEMA platform and demonstrates its utility through several example tasks and experiments. However, the authors do not address potential limitations or edge cases that may arise when using POGEMA for real-world applications. Additionally, the paper could benefit from a more in-depth discussion of the trade-offs and design choices made in the platform's development, as well as potential avenues for future enhancements.
Conclusion
The POGEMA benchmark platform offers a valuable tool for researchers and practitioners working on cooperative multi-agent navigation problems. By providing a realistic and customizable 3D environment, POGEMA enables the systematic evaluation and comparison of different algorithms and approaches. The platform's flexibility and comprehensive suite of features make it a promising resource for advancing the state-of-the-art in this important area of multi-agent systems research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
POGEMA: A Benchmark Platform for Cooperative Multi-Agent Navigation
Alexey Skrynnik, Anton Andreychuk, Anatolii Borzilov, Alexander Chernyavskiy, Konstantin Yakovlev, Aleksandr Panov
Multi-agent reinforcement learning (MARL) has recently excelled in solving challenging cooperative and competitive multi-agent problems in various environments with, mostly, few agents and full observability. Moreover, a range of crucial robotics-related tasks, such as multi-robot navigation and obstacle avoidance, that have been conventionally approached with the classical non-learnable methods (e.g., heuristic search) is currently suggested to be solved by the learning-based or hybrid methods. Still, in this domain, it is hard, not to say impossible, to conduct a fair comparison between classical, learning-based, and hybrid approaches due to the lack of a unified framework that supports both learning and evaluation. To this end, we introduce POGEMA, a set of comprehensive tools that includes a fast environment for learning, a generator of problem instances, the collection of pre-defined ones, a visualization toolkit, and a benchmarking tool that allows automated evaluation. We introduce and specify an evaluation protocol defining a range of domain-related metrics computed on the basics of the primary evaluation indicators (such as success rate and path length), allowing a fair multi-fold comparison. The results of such a comparison, which involves a variety of state-of-the-art MARL, search-based, and hybrid methods, are presented.
Read more7/23/2024
🏅
56
MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning
Florian Felten, Umut Ucak, Hicham Azmani, Gao Peng, Willem Ropke, Hendrik Baier, Patrick Mannion, Diederik M. Roijers, Jordan K. Terry, El-Ghazali Talbi, Gr'egoire Danoy, Ann Now'e, Roxana Ru{a}dulescu
Many challenging tasks such as managing traffic systems, electricity grids, or supply chains involve complex decision-making processes that must balance multiple conflicting objectives and coordinate the actions of various independent decision-makers (DMs). One perspective for formalising and addressing such tasks is multi-objective multi-agent reinforcement learning (MOMARL). MOMARL broadens reinforcement learning (RL) to problems with multiple agents each needing to consider multiple objectives in their learning process. In reinforcement learning research, benchmarks are crucial in facilitating progress, evaluation, and reproducibility. The significance of benchmarks is underscored by the existence of numerous benchmark frameworks developed for various RL paradigms, including single-agent RL (e.g., Gymnasium), multi-agent RL (e.g., PettingZoo), and single-agent multi-objective RL (e.g., MO-Gymnasium). To support the advancement of the MOMARL field, we introduce MOMAland, the first collection of standardised environments for multi-objective multi-agent reinforcement learning. MOMAland addresses the need for comprehensive benchmarking in this emerging field, offering over 10 diverse environments that vary in the number of agents, state representations, reward structures, and utility considerations. To provide strong baselines for future research, MOMAland also includes algorithms capable of learning policies in such settings.
Read more7/24/2024
0
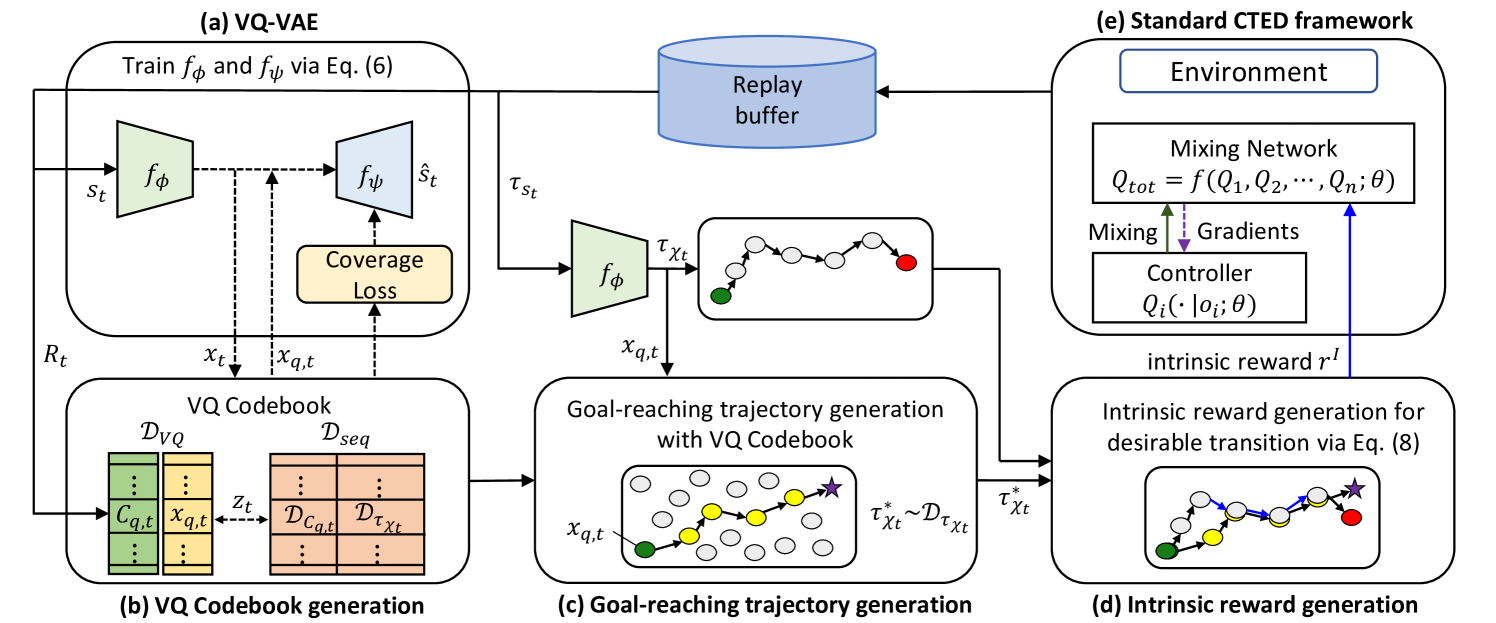
LAGMA: LAtent Goal-guided Multi-Agent Reinforcement Learning
Hyungho Na, Il-chul Moon
In cooperative multi-agent reinforcement learning (MARL), agents collaborate to achieve common goals, such as defeating enemies and scoring a goal. However, learning goal-reaching paths toward such a semantic goal takes a considerable amount of time in complex tasks and the trained model often fails to find such paths. To address this, we present LAtent Goal-guided Multi-Agent reinforcement learning (LAGMA), which generates a goal-reaching trajectory in latent space and provides a latent goal-guided incentive to transitions toward this reference trajectory. LAGMA consists of three major components: (a) quantized latent space constructed via a modified VQ-VAE for efficient sample utilization, (b) goal-reaching trajectory generation via extended VQ codebook, and (c) latent goal-guided intrinsic reward generation to encourage transitions towards the sampled goal-reaching path. The proposed method is evaluated by StarCraft II with both dense and sparse reward settings and Google Research Football. Empirical results show further performance improvement over state-of-the-art baselines.
Read more5/31/2024
0
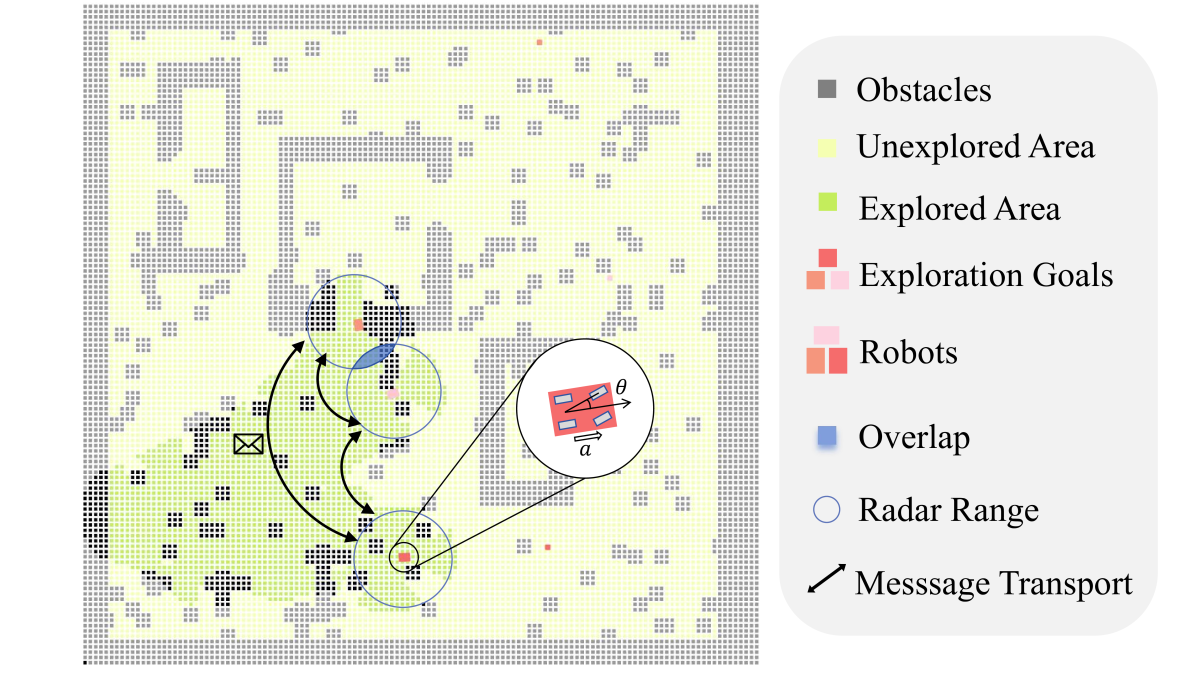
MAexp: A Generic Platform for RL-based Multi-Agent Exploration
Shaohao Zhu, Jiacheng Zhou, Anjun Chen, Mingming Bai, Jiming Chen, Jinming Xu
The sim-to-real gap poses a significant challenge in RL-based multi-agent exploration due to scene quantization and action discretization. Existing platforms suffer from the inefficiency in sampling and the lack of diversity in Multi-Agent Reinforcement Learning (MARL) algorithms across different scenarios, restraining their widespread applications. To fill these gaps, we propose MAexp, a generic platform for multi-agent exploration that integrates a broad range of state-of-the-art MARL algorithms and representative scenarios. Moreover, we employ point clouds to represent our exploration scenarios, leading to high-fidelity environment mapping and a sampling speed approximately 40 times faster than existing platforms. Furthermore, equipped with an attention-based Multi-Agent Target Generator and a Single-Agent Motion Planner, MAexp can work with arbitrary numbers of agents and accommodate various types of robots. Extensive experiments are conducted to establish the first benchmark featuring several high-performance MARL algorithms across typical scenarios for robots with continuous actions, which highlights the distinct strengths of each algorithm in different scenarios.
Read more4/22/2024