MoME: Mixture of Multimodal Experts for Generalist Multimodal Large Language Models

0

Sign in to get full access
Overview
- This paper introduces MoME, a novel approach to building generalist multimodal large language models (LLMs) using a Mixture of Multimodal Experts (MoME) architecture.
- The key idea is to train multiple specialized multimodal experts that can each handle a particular task or modality well, and then combine them into a single generalist model using a gating network.
- This allows the model to leverage the strengths of the individual experts while maintaining the flexibility and scope of a generalist LLM.
Plain English Explanation
The researchers behind this paper have developed a new way to build powerful multimodal models that can handle a wide variety of tasks and data types. These models, called Mixture of Multimodal Experts (MoME), work by training several specialized "expert" models, each of which is good at a particular task or type of data.
For example, one expert might be really good at analyzing images, while another is great at understanding natural language. Rather than trying to cram all of that knowledge into a single large model, the researchers combine the expertise of these specialized models using a "gating network" that decides which expert to use for a given input.
This mixture of experts approach allows the overall model to be a generalist that can handle a wide range of multimodal tasks, while still leveraging the specialized capabilities of the individual experts. It's a bit like having a team of specialists who can each contribute their unique skills to solve complex problems, rather than relying on a single, jack-of-all-trades generalist.
The key benefit of this approach is that it can produce more capable and versatile multimodal models without the need for a single, monolithic model that tries to do everything. And by using a mixture of experts approach, the researchers can more easily scale up the capabilities of these generalist multimodal models as the complexity of the tasks and data they need to handle increases.
Technical Explanation
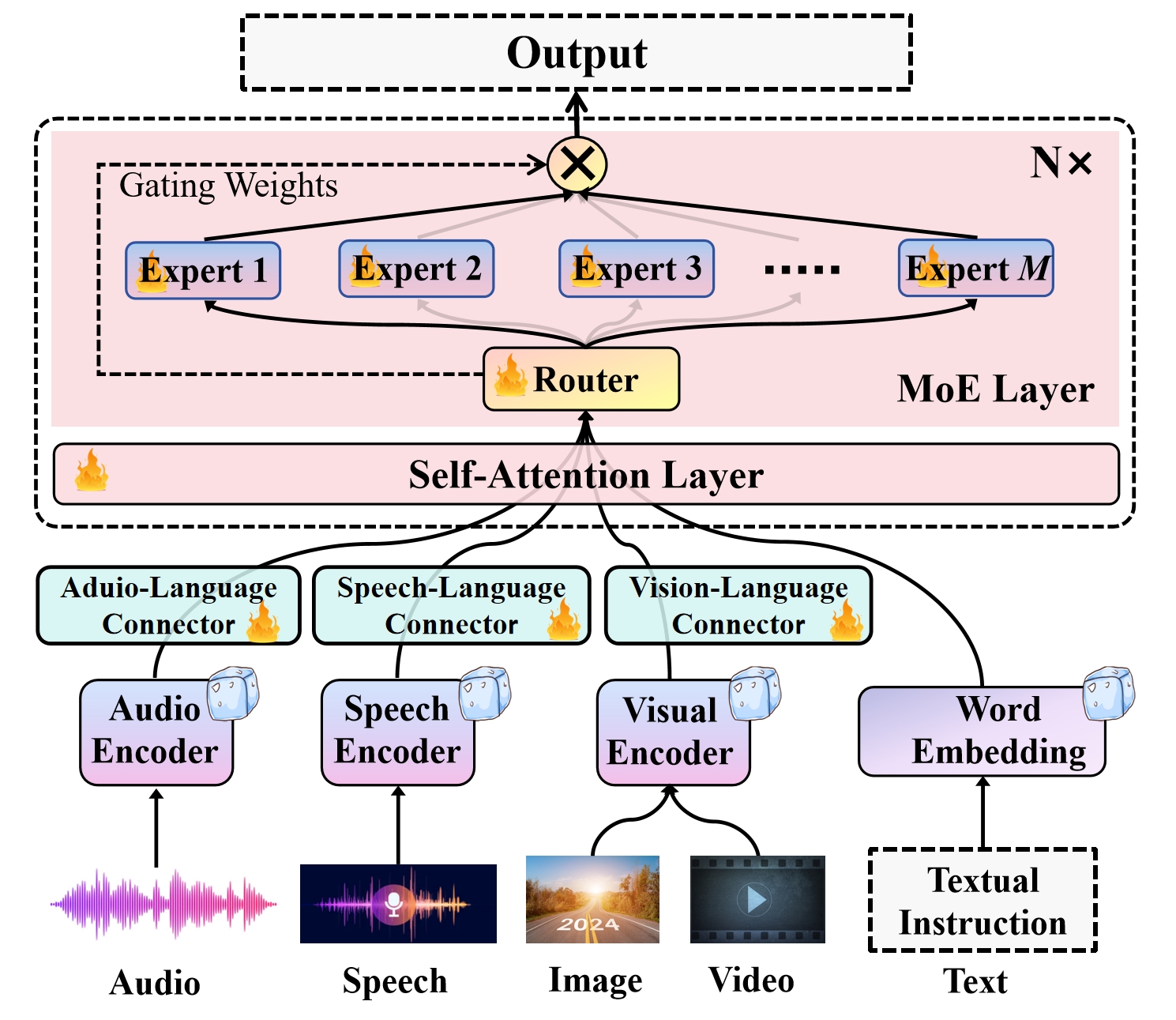
The core idea behind MoME is to train a collection of specialized multimodal "expert" models, each of which is optimized for a particular task or data modality. These experts are then combined using a gating network that dynamically selects the most appropriate expert(s) for a given input.
The architecture of MoME consists of three main components:
- Multimodal Experts: These are individual models, each trained on a specific task or data type, such as image classification, language understanding, or multimodal reasoning.
- Gating Network: This component decides which expert(s) to use for a given input by learning a dynamic routing policy. It takes the input and outputs a probability distribution over the experts.
- Mixing Module: This module aggregates the outputs of the selected experts into a final output, using techniques like weighted averaging or concatenation.
During training, the experts and gating network are optimized jointly to minimize the overall task loss. This encourages the experts to specialize in different aspects of the problem, while the gating network learns to effectively route inputs to the most appropriate expert(s).
The key advantages of the MoME approach are:
- Flexibility: By combining specialized experts, MoME can handle a wide range of multimodal tasks and data types without the need for a single, monolithic model.
- Scalability: As the complexity of the tasks and data increases, new experts can be added to the mixture without having to retrain the entire model.
- Interpretability: The modular architecture of MoME makes it easier to understand and analyze the model's decision-making process, as compared to a large, opaque monolithic model.
Critical Analysis
The MoME approach presented in this paper is a promising step towards building more capable and versatile multimodal LLMs. By leveraging a mixture of specialized experts, the model can potentially achieve better performance and generalization across a wide range of tasks and data types.
However, the authors acknowledge several limitations and areas for further research:
- Expert Specialization: The degree of specialization and the optimal number of experts required for a given task or dataset is not yet well understood. More research is needed to understand how to best configure the expert models and gating network.
- Scalability and Computational Efficiency: While the modular architecture of MoME facilitates scalability, the computational overhead of the gating network and mixing module may become a bottleneck as the number of experts grows. Strategies for efficient scaling of MoME models need to be investigated.
- Interpretability and Transparency: While the modular design of MoME can improve interpretability compared to monolithic models, the authors note that further work is needed to fully understand the decision-making process of the gating network and the role of individual experts.
Additionally, researchers may want to consider the following points when evaluating and extending the MoME approach:
- Robustness and Reliability: It is important to assess the robustness of MoME models to distributional shift, adversarial attacks, and other potential failure modes, to ensure reliable performance in real-world applications.
- Ethical Considerations: As with any powerful AI system, there may be concerns around the ethical use of MoME models, such as the potential for biased or discriminatory outputs. Careful evaluation and mitigation strategies should be explored.
Overall, the MoME approach presented in this paper is a promising step towards more capable and versatile multimodal LLMs. However, further research is needed to address the identified limitations and explore the full potential of this mixture-of-experts approach to generalist multimodal modeling.
Conclusion
This paper introduces a novel architecture called Mixture of Multimodal Experts (MoME) for building generalist multimodal large language models (LLMs). MoME combines the strengths of multiple specialized "expert" models, each focused on a particular task or data modality, using a gating network that dynamically routes inputs to the most appropriate expert(s).
This mixture-of-experts approach allows MoME to achieve better performance and flexibility compared to a single, monolithic multimodal model. It also enables more scalable and interpretable modeling of complex multimodal data and tasks.
While the MoME approach shows promise, the authors acknowledge several areas for further research, such as understanding the optimal configuration of experts, addressing computational efficiency, and improving interpretability. Researchers should also consider evaluating the robustness and ethical implications of MoME models as this line of research continues to evolve.
Overall, the MoME architecture represents an exciting development in the field of generalist multimodal LLMs, with the potential to drive significant advances in the ability of AI systems to understand and reason about the rich, multifaceted nature of real-world data and problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MoME: Mixture of Multimodal Experts for Generalist Multimodal Large Language Models
Leyang Shen, Gongwei Chen, Rui Shao, Weili Guan, Liqiang Nie
Multimodal large language models (MLLMs) have demonstrated impressive capabilities across various vision-language tasks. However, a generalist MLLM typically underperforms compared with a specialist MLLM on most VL tasks, which can be attributed to task interference. In this paper, we propose a mixture of multimodal experts (MoME) to mitigate task interference and obtain a generalist MLLM. Our MoME is composed of two key components, a mixture of vision experts (MoVE) and a mixture of language experts (MoLE). MoVE can adaptively modulate the features transformed from various vision encoders, and has a strong compatibility in transformation architecture. MoLE incorporates sparsely gated experts into LLMs to achieve painless improvements with roughly unchanged inference costs. In response to task interference, our MoME specializes in both vision and language modality to adapt to task discrepancies. Extensive experiments show that MoME significantly improves the performance of generalist MLLMs across various VL tasks. The source code is released at https://github.com/JiuTian-VL/MoME
Read more7/18/2024
0
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024
🔍
0
Omni-SMoLA: Boosting Generalist Multimodal Models with Soft Mixture of Low-rank Experts
Jialin Wu, Xia Hu, Yaqing Wang, Bo Pang, Radu Soricut
Large multi-modal models (LMMs) exhibit remarkable performance across numerous tasks. However, generalist LMMs often suffer from performance degradation when tuned over a large collection of tasks. Recent research suggests that Mixture of Experts (MoE) architectures are useful for instruction tuning, but for LMMs of parameter size around O(50-100B), the prohibitive cost of replicating and storing the expert models severely limits the number of experts we can use. We propose Omni-SMoLA, an architecture that uses the Soft MoE approach to (softly) mix many multimodal low rank experts, and avoids introducing a significant number of new parameters compared to conventional MoE models. The core intuition here is that the large model provides a foundational backbone, while different lightweight experts residually learn specialized knowledge, either per-modality or multimodally. Extensive experiments demonstrate that the SMoLA approach helps improve the generalist performance across a broad range of generative vision-and-language tasks, achieving new SoTA generalist performance that often matches or outperforms single specialized LMM baselines, as well as new SoTA specialist performance.
Read more4/4/2024