Monitizer: Automating Design and Evaluation of Neural Network Monitors

0
🧠
Sign in to get full access
Overview
- Neural networks (NNs) can behave unpredictably when presented with data they haven't seen before (out-of-distribution or OOD data)
- This can be dangerous if the NN's output is used for decision-making in safety-critical systems
- Detecting OOD inputs is crucial for safely applying NNs, but verification approaches don't scale well to practical NNs
- Runtime monitoring is more promising, but optimizing and comparing different monitoring approaches is challenging
Plain English Explanation
Neural networks are a type of machine learning model that can be trained to perform various tasks, like recognizing objects in images or translating languages. However, the behavior of these models can be unpredictable when they encounter new types of data that they haven't been trained on before. This "out-of-distribution" (OOD) data can cause the neural network to make incorrect or unreliable predictions, which could be a problem if the neural network is being used in a safety-critical system, like a self-driving car.
To address this issue, researchers have been exploring ways to detect when a neural network is presented with OOD data. One approach is to use "verification" techniques, which try to formally prove that the neural network will behave correctly. However, these verification techniques don't scale well to the large, complex neural networks used in practical applications.
An alternative approach is to use "runtime monitoring," where the neural network is constantly checked for signs that it's encountering OOD data. Several different monitoring techniques have been proposed, but it's been challenging for researchers and developers to optimize these techniques for their specific needs and compare the performance of different approaches.
To help address these challenges, the researchers in this paper have developed a tool that allows users to apply various monitoring techniques to their neural networks, optimize the parameters of the monitors, and compare the performance of different approaches. This tool should make it easier for researchers to develop new monitoring techniques and for developers to ensure the safe deployment of neural networks in real-world applications.
Technical Explanation
The paper presents a tool that allows users to apply and evaluate different techniques for monitoring the behavior of neural networks when they encounter out-of-distribution (OOD) data. The motivation for this work is that the behavior of neural networks on previously unseen types of data can be unpredictable, which can be dangerous if the network's output is used for decision-making in safety-critical systems.
The tool supports three main functionalities:
-
Applying Monitors: Users can apply various types of monitors from the literature to a given input neural network. These monitors are designed to detect when the network is presented with OOD data.
-
Hyperparameter Optimization: The tool allows users to optimize the hyperparameters of the monitors for a specific problem or dataset.
-
Experimental Evaluation: Users can evaluate and compare the performance of different monitoring approaches on their data using the tool.
The authors demonstrate the tool's usability through several use cases involving different types of users, as well as a case study comparing various monitoring approaches from recent research papers, such as Can We Defend Against Unknown Attacks?, Toward a Realistic Benchmark for Out-of-Distribution Detection, Gradient Regularized Out-of-Distribution Detection, Rethinking Out-of-Distribution Detection: Advancing Reinforcement Learning, and Out-of-Distribution Data Acquaintance: Adversarial Examples Survey.
Critical Analysis
The paper presents a valuable tool for researchers and developers working on neural network monitoring and safety. By providing a unified platform for applying, optimizing, and comparing different monitoring approaches, the tool can help accelerate progress in this important area of research.
However, the paper does not provide a comprehensive evaluation of the tool's performance or a detailed comparison of the various monitoring techniques it supports. While the case study is a helpful illustration, more extensive testing and benchmarking would be necessary to fully understand the strengths and limitations of the different approaches.
Additionally, the paper does not address potential issues with the robustness or reliability of the monitoring techniques themselves. As with any safety-critical system, it's important to carefully scrutinize the assumptions and limitations of the underlying algorithms to ensure they can be trusted in real-world applications.
Overall, the tool presented in this paper represents a valuable contribution to the field of neural network safety and reliability. By lowering the barriers to experimentation and comparison, it has the potential to accelerate the development of more robust and trustworthy monitoring solutions. Further research and testing will be needed to fully realize this potential.
Conclusion
This paper presents a tool that allows users to apply, optimize, and compare different techniques for monitoring the behavior of neural networks when they encounter out-of-distribution (OOD) data. The motivation is that the unpredictable behavior of neural networks on unseen data can be dangerous if their output is used for decision-making in safety-critical systems.
The tool's key features include the ability to apply various monitoring approaches, optimize the monitors' hyperparameters, and evaluate the performance of different techniques. This should make it easier for researchers to develop new monitoring approaches and for developers to ensure the safe deployment of neural networks in real-world applications.
While the paper provides a helpful demonstration of the tool's capabilities, more extensive testing and analysis would be needed to fully understand the strengths and limitations of the different monitoring techniques. Additionally, the robustness and reliability of the monitoring approaches themselves deserve further scrutiny. Overall, this tool represents a valuable contribution to the field of neural network safety and reliability, with the potential to accelerate progress in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Monitizer: Automating Design and Evaluation of Neural Network Monitors
Muqsit Azeem, Marta Grobelna, Sudeep Kanav, Jan Kretinsky, Stefanie Mohr, Sabine Rieder
The behavior of neural networks (NNs) on previously unseen types of data (out-of-distribution or OOD) is typically unpredictable. This can be dangerous if the network's output is used for decision-making in a safety-critical system. Hence, detecting that an input is OOD is crucial for the safe application of the NN. Verification approaches do not scale to practical NNs, making runtime monitoring more appealing for practical use. While various monitors have been suggested recently, their optimization for a given problem, as well as comparison with each other and reproduction of results, remain challenging. We present a tool for users and developers of NN monitors. It allows for (i) application of various types of monitors from the literature to a given input NN, (ii) optimization of the monitor's hyperparameters, and (iii) experimental evaluation and comparison to other approaches. Besides, it facilitates the development of new monitoring approaches. We demonstrate the tool's usability on several use cases of different types of users as well as on a case study comparing different approaches from recent literature.
Read more5/20/2024

0
Can we Defend Against the Unknown? An Empirical Study About Threshold Selection for Neural Network Monitoring
Khoi Tran Dang, Kevin Delmas, J'er'emie Guiochet, Joris Gu'erin
With the increasing use of neural networks in critical systems, runtime monitoring becomes essential to reject unsafe predictions during inference. Various techniques have emerged to establish rejection scores that maximize the separability between the distributions of safe and unsafe predictions. The efficacy of these approaches is mostly evaluated using threshold-agnostic metrics, such as the area under the receiver operating characteristic curve. However, in real-world applications, an effective monitor also requires identifying a good threshold to transform these scores into meaningful binary decisions. Despite the pivotal importance of threshold optimization, this problem has received little attention. A few studies touch upon this question, but they typically assume that the runtime data distribution mirrors the training distribution, which is a strong assumption as monitors are supposed to safeguard a system against potentially unforeseen threats. In this work, we present rigorous experiments on various image datasets to investigate: 1. The effectiveness of monitors in handling unforeseen threats, which are not available during threshold adjustments. 2. Whether integrating generic threats into the threshold optimization scheme can enhance the robustness of monitors.
Read more5/22/2024
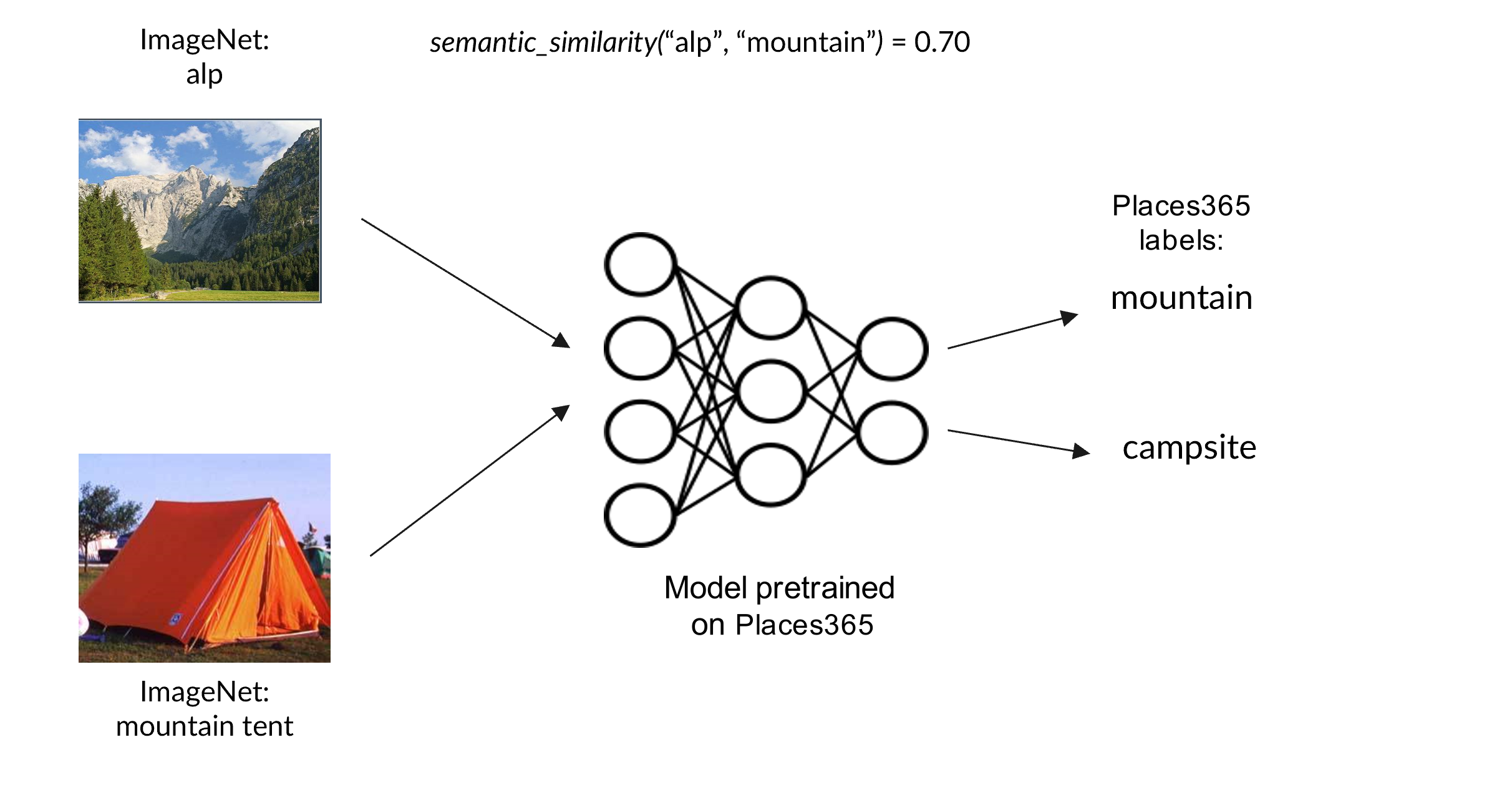
0
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
Read more4/17/2024

0
Learning Run-time Safety Monitors for Machine Learning Components
Ozan Vardal, Richard Hawkins, Colin Paterson, Chiara Picardi, Daniel Omeiza, Lars Kunze, Ibrahim Habli
For machine learning components used as part of autonomous systems (AS) in carrying out critical tasks it is crucial that assurance of the models can be maintained in the face of post-deployment changes (such as changes in the operating environment of the system). A critical part of this is to be able to monitor when the performance of the model at runtime (as a result of changes) poses a safety risk to the system. This is a particularly difficult challenge when ground truth is unavailable at runtime. In this paper we introduce a process for creating safety monitors for ML components through the use of degraded datasets and machine learning. The safety monitor that is created is deployed to the AS in parallel to the ML component to provide a prediction of the safety risk associated with the model output. We demonstrate the viability of our approach through some initial experiments using publicly available speed sign datasets.
Read more6/26/2024