MoPE: Mixture of Prefix Experts for Zero-Shot Dialogue State Tracking

0

Sign in to get full access
Overview
- This paper introduces MoPE (Mixture of Prefix Experts), a novel dialogue state tracking model that can perform zero-shot learning on unseen domains.
- The key idea is to use a mixture of specialized "prefix experts" that can each handle a different set of dialogue states, allowing the model to be quickly adapted to new domains without retraining.
- The authors evaluate MoPE on several dialogue state tracking benchmarks and show it outperforms previous zero-shot and few-shot learning approaches.
Plain English Explanation
Dialogue state tracking is an important task in conversational AI systems, where the system needs to understand the user's current goal or intent within an ongoing conversation. This paper introduces a new model called MoPE that can perform this task even when encountering completely new dialogue domains that it wasn't originally trained on.
The key innovation in MoPE is that it uses a "mixture of experts" approach, where the model is actually composed of several specialized "sub-models" (called "prefix experts") that each focus on a different set of dialogue states. When the model encounters a new dialogue, it can dynamically combine the outputs of these different experts to handle the novel dialogue states, without needing to be retrained from scratch.
This allows MoPE to be quickly adapted to new dialogue domains in a "zero-shot" manner, without requiring any labeled training data for the new domain. The authors show that MoPE outperforms previous zero-shot and few-shot learning approaches on several standard dialogue state tracking benchmarks.
Technical Explanation
The authors propose a novel dialogue state tracking model called MoPE (Mixture of Prefix Experts) that can perform zero-shot learning on unseen dialogue domains. The core idea is to use a "mixture of experts" architecture, where the model is composed of multiple specialized "prefix experts" that each focus on a different set of dialogue states.
When the model encounters a new dialogue, it can dynamically combine the outputs of these different experts to handle the novel dialogue states, without requiring any additional training on the new domain. This is enabled by the model's ability to efficiently learn and reuse relevant prefix representations for each expert.
Specifically, MoPE consists of a shared prefix encoder that maps the dialogue context into a shared representation, and then multiple parallel prefix experts that each specialize in a different set of dialogue states. A gating network is used to dynamically combine the outputs of these experts based on the input dialogue.
The authors evaluate MoPE on several standard dialogue state tracking benchmarks, including unseen domains and few-shot learning settings. They show that MoPE outperforms previous state-of-the-art zero-shot and few-shot learning approaches, demonstrating the effectiveness of the mixture of experts approach for rapid adaptation to new dialogue domains.
Critical Analysis
The authors acknowledge several limitations of the MoPE approach. First, the model requires carefully designing the set of prefix experts to ensure they can effectively cover a wide range of dialogue states. This could become challenging as the complexity of the dialogue domains increases.
Additionally, the gating network that combines the expert outputs adds some computational overhead, which could be a concern for real-time dialogue systems. The authors suggest potential approaches to address this, such as using more efficient mixture of experts techniques or expert parallelism.
It would also be interesting to see how MoPE performs on more open-ended, large language model-based dialogue systems, where the set of possible dialogue states is less constrained. The authors focus on more structured, task-oriented dialogue, so the generalization to more free-form conversations remains an open question.
Conclusion
The MoPE model introduced in this paper represents an innovative approach to dialogue state tracking that can adapt to new dialogue domains without the need for extensive retraining. By leveraging a mixture of specialized prefix experts, the model can efficiently combine relevant knowledge to handle novel dialogue states in a zero-shot manner.
The authors' evaluation results demonstrate the effectiveness of this approach, and the potential for mixture of experts techniques to enhance the flexibility and generalization capabilities of conversational AI systems. While some challenges remain, MoPE showcases an important step towards building more adaptable and versatile dialogue models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MoPE: Mixture of Prefix Experts for Zero-Shot Dialogue State Tracking
Tianwen Tang, Tong Zhu, Haodong Liu, Yin Bai, Jia Cheng, Wenliang Chen
Zero-shot dialogue state tracking (DST) transfers knowledge to unseen domains, reducing the cost of annotating new datasets. Previous zero-shot DST models mainly suffer from domain transferring and partial prediction problems. To address these challenges, we propose Mixture of Prefix Experts (MoPE) to establish connections between similar slots in different domains, which strengthens the model transfer performance in unseen domains. Empirical results demonstrate that MoPE-DST achieves the joint goal accuracy of 57.13% on MultiWOZ2.1 and 55.40% on SGD.
Read more4/15/2024
0
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts
Ruixiang Jiang, Lingbo Liu, Changwen Chen
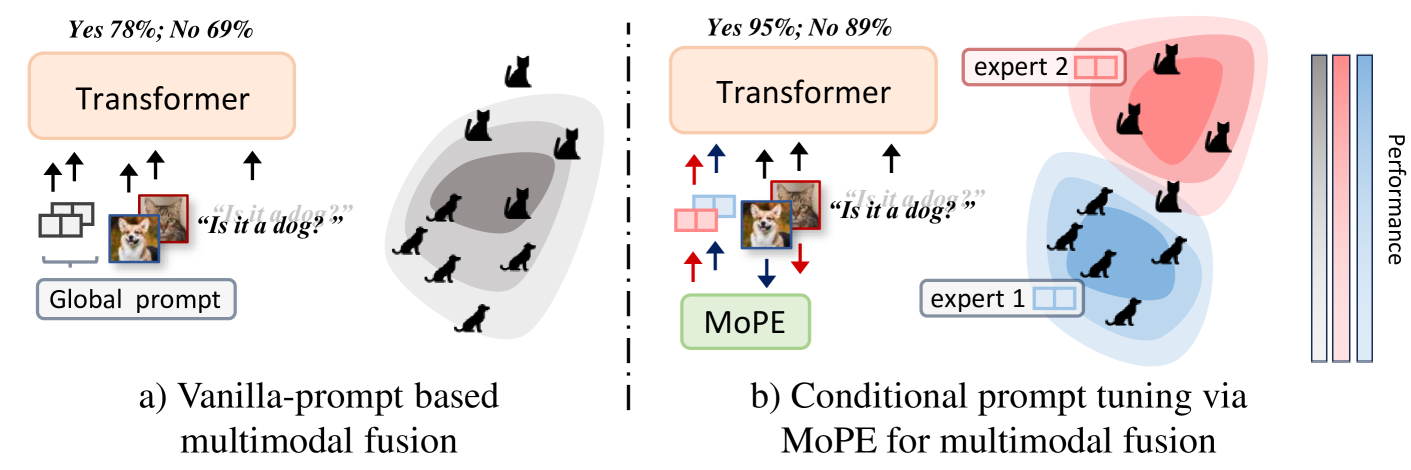
Despite the demonstrated parameter efficiency of prompt-based multimodal fusion methods, their limited adaptivity and expressiveness often result in suboptimal performance compared to other tuning approaches. In this paper, we address these limitations by decomposing the vanilla prompts to adaptively capture instance-level features. Building upon this decomposition, we introduce the mixture of prompt experts (MoPE) technique to enhance the expressiveness of prompt tuning. MoPE leverages multimodal pairing priors to route the most effective prompt on a per-instance basis. Compared to vanilla prompting, our MoPE-based fusion method exhibits greater expressiveness, scaling more effectively with the training data and the overall number of trainable parameters. We also investigate regularization terms for expert routing, which lead to emergent expert specialization during training, paving the way for interpretable soft prompting. Extensive experiments across six multimodal datasets spanning four modalities demonstrate that our method achieves state-of-the-art results for prompt fusion, matching or even surpassing the performance of fine-tuning while requiring only 0.8% of the trainable parameters. Code will be released: https://github.com/songrise/MoPE.
Read more9/12/2024
📊
0
Leveraging Diverse Data Generation for Adaptable Zero-Shot Dialogue State Tracking
James D. Finch, Jinho D. Choi
We demonstrate substantial performance gains in zero-shot dialogue state tracking (DST) by enhancing training data diversity through synthetic data generation. Existing DST datasets are severely limited in the number of application domains and slot types they cover due to the high costs of data collection, restricting their adaptability to new domains. This work addresses this challenge with a novel, fully automatic data generation approach that creates synthetic zero-shot DST datasets. Distinguished from previous methods, our approach can generate dialogues across a massive range of application domains, complete with silver-standard dialogue state annotations and slot descriptions. This technique is used to create the D0T dataset for training zero-shot DST models, encompassing an unprecedented 1,000+ domains. Experiments on the MultiWOZ benchmark show that training models on diverse synthetic data improves Joint Goal Accuracy by 6.7%, achieving results competitive with models 13.5 times larger than ours.
Read more6/14/2024

0
Investigating the potential of Sparse Mixtures-of-Experts for multi-domain neural machine translation
Nadezhda Chirkova, Vassilina Nikoulina, Jean-Luc Meunier, Alexandre B'erard
We focus on multi-domain Neural Machine Translation, with the goal of developing efficient models which can handle data from various domains seen during training and are robust to domains unseen during training. We hypothesize that Sparse Mixture-of-Experts (SMoE) models are a good fit for this task, as they enable efficient model scaling, which helps to accommodate a variety of multi-domain data, and allow flexible sharing of parameters between domains, potentially enabling knowledge transfer between similar domains and limiting negative transfer. We conduct a series of experiments aimed at validating the utility of SMoE for the multi-domain scenario, and find that a straightforward width scaling of Transformer is a simpler and surprisingly more efficient approach in practice, and reaches the same performance level as SMoE. We also search for a better recipe for robustness of multi-domain systems, highlighting the importance of mixing-in a generic domain, i.e. Paracrawl, and introducing a simple technique, domain randomization.
Read more7/2/2024