SingMOS: An extensive Open-Source Singing Voice Dataset for MOS Prediction

0

Sign in to get full access
Overview
- Presents an extensive open-source dataset called SingMOS for singing voice quality prediction
- Aims to provide a comprehensive resource for researchers in the field of singing voice analysis and synthesis
- Includes a large number of professionally recorded singing samples across a wide range of genres and styles
Plain English Explanation
The SingMOS dataset is a valuable resource for researchers working on singing voice analysis and synthesis. It provides a large collection of professionally recorded singing samples spanning a diverse range of musical genres and styles. This dataset can be used to train and evaluate models that predict the perceived quality of singing voice, known as Mean Opinion Score (MOS) prediction. By making this dataset openly available, the researchers hope to facilitate advancements in the field of singing voice research and enable the development of improved singing voice analysis and synthesis systems.
Technical Explanation
The SingMOS: An extensive Open-Source Singing Voice Dataset for MOS Prediction paper presents a comprehensive singing voice dataset called SingMOS. The dataset includes over 15,000 professionally recorded singing samples from a wide variety of genres, including pop, rock, folk, and opera. Each sample has been carefully evaluated and rated on a 5-point Mean Opinion Score (MOS) scale, providing a detailed assessment of the perceived quality of the singing voice.
The dataset is designed to serve as a valuable resource for researchers working on singing voice analysis and synthesis tasks, such as Singing Voice Graph Modeling for SingFake Detection and Robust Singing Voice Transcription for Synthesis. By providing a large and diverse dataset with MOS annotations, the researchers aim to enable the development of more accurate and robust models for predicting the quality of singing voice.
Critical Analysis
The SingMOS dataset represents a significant contribution to the field of singing voice research. The comprehensive nature of the dataset, with its extensive coverage of different genres and styles, is a notable strength. This diversity allows for the development of more generalizable models that can handle the nuances and variations inherent in professional singing performances.
However, the paper does not address potential limitations or biases in the dataset. For example, the distribution of singing samples across genres and styles may not be perfectly representative of the overall landscape of professional singing. Additionally, the reliability and consistency of the MOS annotations could be an area of concern, as subjective evaluations can be influenced by various factors.
Further research could explore methods to mitigate these potential issues, such as Music Motion Semantic Annotation (MOSA) Dataset for more objective singing quality assessments or Singing-Oriented Multi-resolution Discrete Representation for more comprehensive representation of singing voice characteristics.
Conclusion
The SingMOS dataset is a valuable contribution to the field of singing voice research, providing a comprehensive and open-source resource for training and evaluating models related to singing voice analysis and synthesis. By making this dataset available, the researchers have taken an important step in enabling further advancements in this area of study. While the dataset has some potential limitations, it serves as a solid foundation for future research and the development of improved singing voice systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SingMOS: An extensive Open-Source Singing Voice Dataset for MOS Prediction
Yuxun Tang, Jiatong Shi, Yuning Wu, Qin Jin
In speech generation tasks, human subjective ratings, usually referred to as the opinion score, are considered the gold standard for speech quality evaluation, with the mean opinion score (MOS) serving as the primary evaluation metric. Due to the high cost of human annotation, several MOS prediction systems have emerged in the speech domain, demonstrating good performance. These MOS prediction models are trained using annotations from previous speech-related challenges. However, compared to the speech domain, the singing domain faces data scarcity and stricter copyright protections, leading to a lack of high-quality MOS-annotated datasets for singing. To address this, we propose SingMOS, a high-quality and diverse MOS dataset for singing, covering a range of Chinese and Japanese datasets. These synthesized vocals are generated using state-of-the-art models in singing synthesis, conversion, or resynthesis tasks and are rated by professional annotators alongside real vocals. Data analysis demonstrates the diversity and reliability of our dataset. Additionally, we conduct further exploration on SingMOS, providing insights for singing MOS prediction and guidance for the continued expansion of SingMOS.
Read more6/21/2024

0
The VoiceMOS Challenge 2024: Beyond Speech Quality Prediction
Wen-Chin Huang, Szu-Wei Fu, Erica Cooper, Ryandhimas E. Zezario, Tomoki Toda, Hsin-Min Wang, Junichi Yamagishi, Yu Tsao
We present the third edition of the VoiceMOS Challenge, a scientific initiative designed to advance research into automatic prediction of human speech ratings. There were three tracks. The first track was on predicting the quality of ``zoomed-in'' high-quality samples from speech synthesis systems. The second track was to predict ratings of samples from singing voice synthesis and voice conversion with a large variety of systems, listeners, and languages. The third track was semi-supervised quality prediction for noisy, clean, and enhanced speech, where a very small amount of labeled training data was provided. Among the eight teams from both academia and industry, we found that many were able to outperform the baseline systems. Successful techniques included retrieval-based methods and the use of non-self-supervised representations like spectrograms and pitch histograms. These results showed that the challenge has advanced the field of subjective speech rating prediction.
Read more9/12/2024
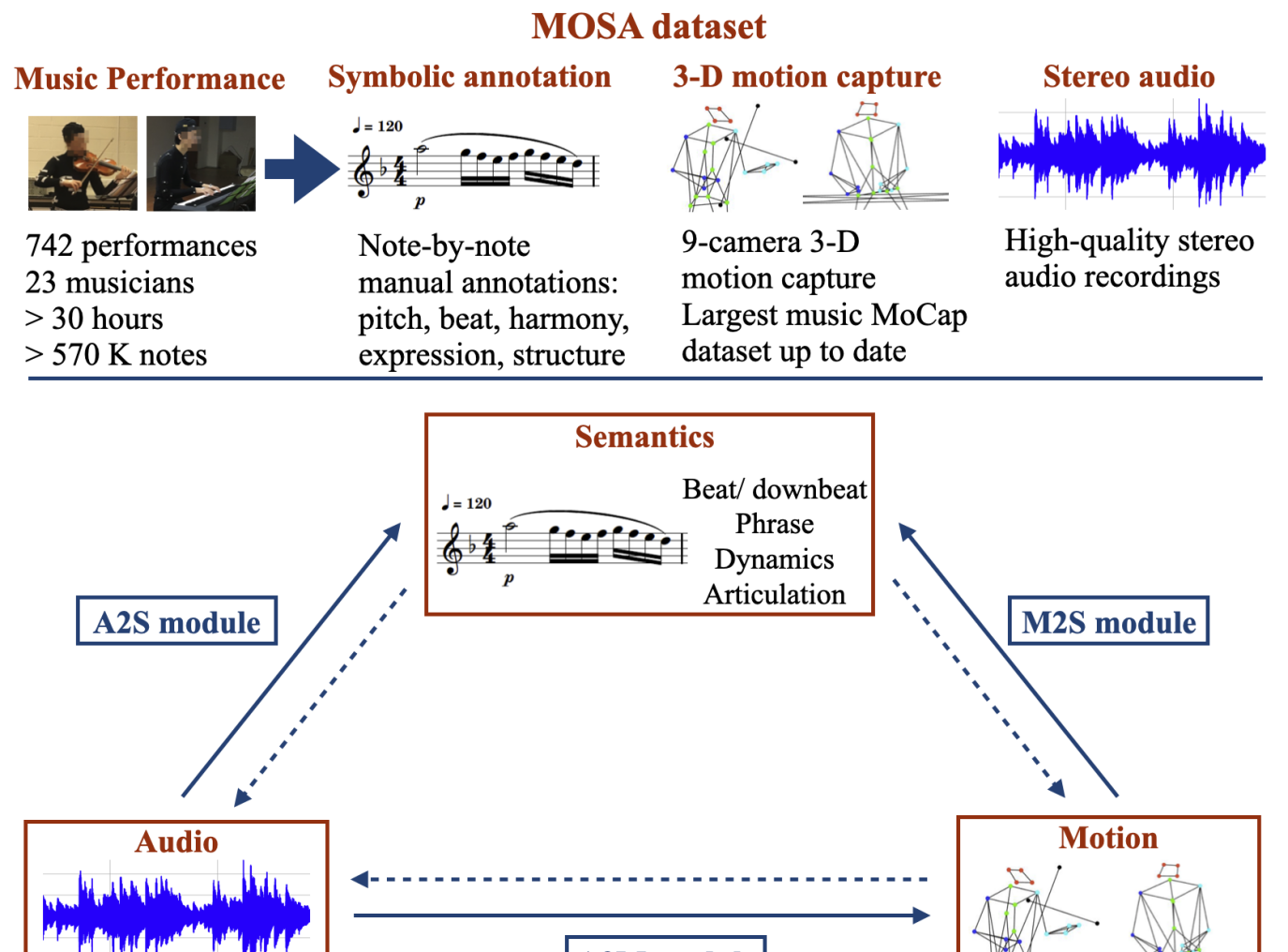
0
MOSA: Music Motion with Semantic Annotation Dataset for Cross-Modal Music Processing
Yu-Fen Huang, Nikki Moran, Simon Coleman, Jon Kelly, Shun-Hwa Wei, Po-Yin Chen, Yun-Hsin Huang, Tsung-Ping Chen, Yu-Chia Kuo, Yu-Chi Wei, Chih-Hsuan Li, Da-Yu Huang, Hsuan-Kai Kao, Ting-Wei Lin, Li Su
In cross-modal music processing, translation between visual, auditory, and semantic content opens up new possibilities as well as challenges. The construction of such a transformative scheme depends upon a benchmark corpus with a comprehensive data infrastructure. In particular, the assembly of a large-scale cross-modal dataset presents major challenges. In this paper, we present the MOSA (Music mOtion with Semantic Annotation) dataset, which contains high quality 3-D motion capture data, aligned audio recordings, and note-by-note semantic annotations of pitch, beat, phrase, dynamic, articulation, and harmony for 742 professional music performances by 23 professional musicians, comprising more than 30 hours and 570 K notes of data. To our knowledge, this is the largest cross-modal music dataset with note-level annotations to date. To demonstrate the usage of the MOSA dataset, we present several innovative cross-modal music information retrieval (MIR) and musical content generation tasks, including the detection of beats, downbeats, phrase, and expressive contents from audio, video and motion data, and the generation of musicians' body motion from given music audio. The dataset and codes are available alongside this publication (https://github.com/yufenhuang/MOSA-Music-mOtion-and-Semantic-Annotation-dataset).
Read more6/11/2024
📊
0
Singing Voice Data Scaling-up: An Introduction to ACE-Opencpop and ACE-KiSing
Jiatong Shi, Yueqian Lin, Xinyi Bai, Keyi Zhang, Yuning Wu, Yuxun Tang, Yifeng Yu, Qin Jin, Shinji Watanabe
In singing voice synthesis (SVS), generating singing voices from musical scores faces challenges due to limited data availability. This study proposes a unique strategy to address the data scarcity in SVS. We employ an existing singing voice synthesizer for data augmentation, complemented by detailed manual tuning, an approach not previously explored in data curation, to reduce instances of unnatural voice synthesis. This innovative method has led to the creation of two expansive singing voice datasets, ACE-Opencpop and ACE-KiSing, which are instrumental for large-scale, multi-singer voice synthesis. Through thorough experimentation, we establish that these datasets not only serve as new benchmarks for SVS but also enhance SVS performance on other singing voice datasets when used as supplementary resources. The corpora, pre-trained models, and their related training recipes are publicly available at ESPnet-Muskits (url{https://github.com/espnet/espnet})
Read more6/14/2024