Motion Avatar: Generate Human and Animal Avatars with Arbitrary Motion
2405.11286
0
0
Abstract
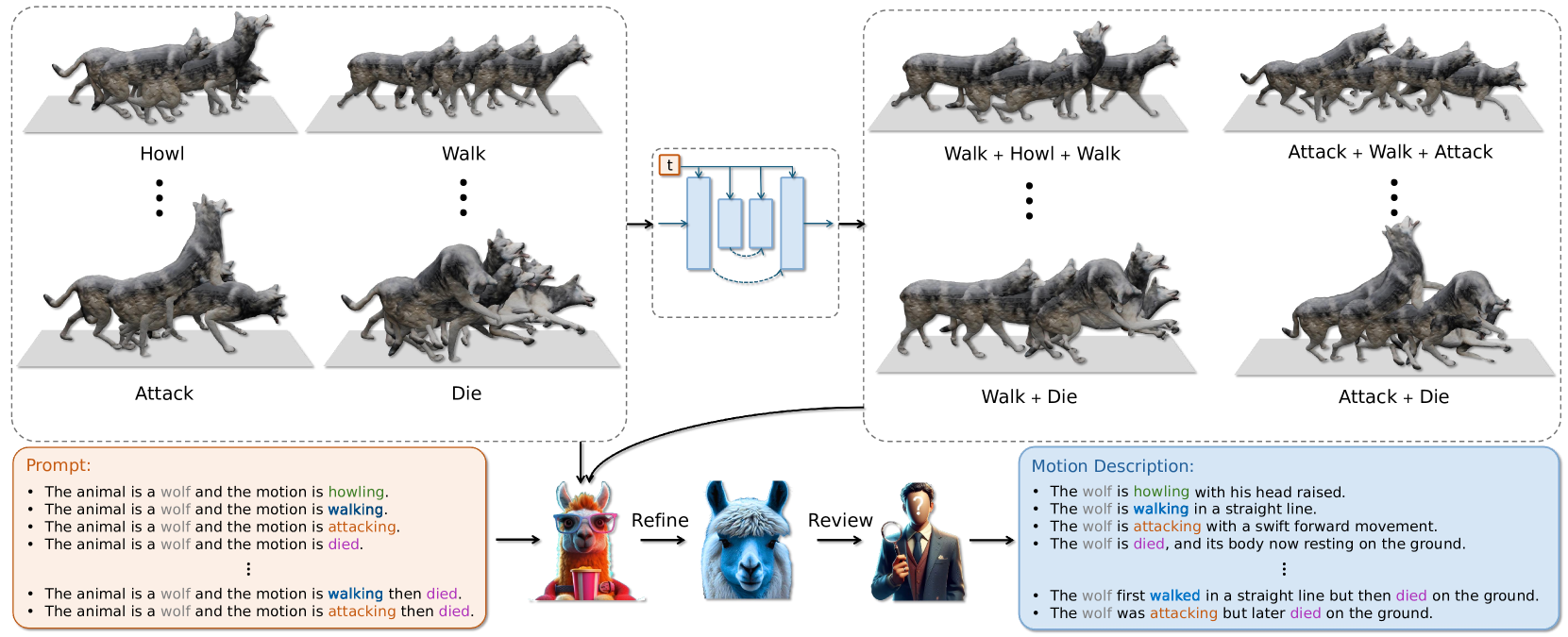
In recent years, there has been significant interest in creating 3D avatars and motions, driven by their diverse applications in areas like film-making, video games, AR/VR, and human-robot interaction. However, current efforts primarily concentrate on either generating the 3D avatar mesh alone or producing motion sequences, with integrating these two aspects proving to be a persistent challenge. Additionally, while avatar and motion generation predominantly target humans, extending these techniques to animals remains a significant challenge due to inadequate training data and methods. To bridge these gaps, our paper presents three key contributions. Firstly, we proposed a novel agent-based approach named Motion Avatar, which allows for the automatic generation of high-quality customizable human and animal avatars with motions through text queries. The method significantly advanced the progress in dynamic 3D character generation. Secondly, we introduced a LLM planner that coordinates both motion and avatar generation, which transforms a discriminative planning into a customizable Q&A fashion. Lastly, we presented an animal motion dataset named Zoo-300K, comprising approximately 300,000 text-motion pairs across 65 animal categories and its building pipeline ZooGen, which serves as a valuable resource for the community. See project website https://steve-zeyu-zhang.github.io/MotionAvatar/
Create account to get full access
Overview
• This research paper presents a novel method called "Motion Avatar" for generating realistic human and animal avatars with arbitrary motion.
• The authors leverage a large-scale 3D motion dataset to train a neural network that can map 2D images of humans and animals to their 3D avatar representations, and then animate those avatars with arbitrary motion.
• This allows for the creation of personalized, animated 3D avatars from simple 2D images, which has applications in areas like virtual reality, video games, and animation.
Plain English Explanation
The researchers have developed a new technology called "Motion Avatar" that can take a 2D photo of a person or animal and turn it into a fully animated 3D character. This 3D avatar can then be made to move and act in all kinds of ways, even if the original photo didn't show that motion.
The key innovation is that the researchers trained a machine learning model on a huge dataset of 3D motion capture data. This allows the model to understand how different bodies move and deform as they perform various actions. So when you give it a 2D photo, it can "guess" what the 3D structure of that person or animal is, and then animate it with realistic movement.
This has a lot of practical applications. For example, in virtual reality or video games, you could create personalized 3D avatars of yourself or your favorite animals that can move around naturally. Or in animation, you could quickly generate 3D character models from 2D artwork. The technology makes it much easier and faster to create these kinds of animated 3D characters.
Technical Explanation
The key technical innovations in this paper are:
-
A neural network architecture that can map 2D images of humans and animals to their corresponding 3D avatar representations. This allows the system to infer the 3D structure of a subject from a 2D photo.
-
A motion transfer module that can then animate these 3D avatars with arbitrary motion, by leveraging a large dataset of 3D motion capture data.
-
Techniques for efficient and realistic animation of the avatars, including pose estimation, texture mapping, and deformation modeling.
The authors demonstrate the capabilities of Motion Avatar through a variety of experiments, showing how it can generate animated 3D avatars of both humans and animals from single 2D images, and transfer a wide range of motions onto these avatars.
Critical Analysis
The Motion Avatar technique represents an impressive advance in the state-of-the-art for 3D character animation. By leveraging large-scale motion data, the system can create highly realistic animated avatars from simple 2D inputs.
However, the paper does note some limitations. The avatar generation is not yet fully photorealistic, and the motion transfer can sometimes appear unnatural, especially for more complex or unusual movements. The authors suggest further research is needed to improve these aspects.
Additionally, there are potential ethical concerns around the use of this technology, such as the ability to create fake or manipulated media. The authors do not address these issues, which would be an important consideration for real-world applications.
Overall, Motion Avatar is a compelling advance in 3D animation that opens up new possibilities, but further work is needed to fully realize its potential while addressing potential downsides.
Conclusion
The Motion Avatar system presented in this paper represents an exciting step forward in the field of 3D character animation. By combining 2D-to-3D reconstruction with large-scale motion data, the researchers have created a method to generate highly realistic, animated avatars of both humans and animals from simple 2D inputs.
This technology has broad applications in areas like virtual reality, video games, and animation, where the ability to quickly and easily create personalized 3D characters would be valuable. While there are still some limitations to address, the core innovations of Motion Avatar demonstrate the power of combining computer vision, graphics, and machine learning to enable new forms of digital content creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
Generating Human Motion in 3D Scenes from Text Descriptions
Zhi Cen, Huaijin Pi, Sida Peng, Zehong Shen, Minghui Yang, Shuai Zhu, Hujun Bao, Xiaowei Zhou
0
0
Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
5/14/2024

New!MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance
Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, Fangyuan Zou
0
0
In recent years, generative artificial intelligence has achieved significant advancements in the field of image generation, spawning a variety of applications. However, video generation still faces considerable challenges in various aspects, such as controllability, video length, and richness of details, which hinder the application and popularization of this technology. In this work, we propose a controllable video generation framework, dubbed MimicMotion, which can generate high-quality videos of arbitrary length mimicking specific motion guidance. Compared with previous methods, our approach has several highlights. Firstly, we introduce confidence-aware pose guidance that ensures high frame quality and temporal smoothness. Secondly, we introduce regional loss amplification based on pose confidence, which significantly reduces image distortion. Lastly, for generating long and smooth videos, we propose a progressive latent fusion strategy. By this means, we can produce videos of arbitrary length with acceptable resource consumption. With extensive experiments and user studies, MimicMotion demonstrates significant improvements over previous approaches in various aspects. Detailed results and comparisons are available on our project page: https://tencent.github.io/MimicMotion .
7/1/2024

InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation
Yuchi Wang, Junliang Guo, Jianhong Bai, Runyi Yu, Tianyu He, Xu Tan, Xu Sun, Jiang Bian
0
0
Recent talking avatar generation models have made strides in achieving realistic and accurate lip synchronization with the audio, but often fall short in controlling and conveying detailed expressions and emotions of the avatar, making the generated video less vivid and controllable. In this paper, we propose a novel text-guided approach for generating emotionally expressive 2D avatars, offering fine-grained control, improved interactivity, and generalizability to the resulting video. Our framework, named InstructAvatar, leverages a natural language interface to control the emotion as well as the facial motion of avatars. Technically, we design an automatic annotation pipeline to construct an instruction-video paired training dataset, equipped with a novel two-branch diffusion-based generator to predict avatars with audio and text instructions at the same time. Experimental results demonstrate that InstructAvatar produces results that align well with both conditions, and outperforms existing methods in fine-grained emotion control, lip-sync quality, and naturalness. Our project page is https://wangyuchi369.github.io/InstructAvatar/.
5/27/2024
💬
SignAvatar: Sign Language 3D Motion Reconstruction and Generation
Lu Dong, Lipisha Chaudhary, Fei Xu, Xiao Wang, Mason Lary, Ifeoma Nwogu
0
0
Achieving expressive 3D motion reconstruction and automatic generation for isolated sign words can be challenging, due to the lack of real-world 3D sign-word data, the complex nuances of signing motions, and the cross-modal understanding of sign language semantics. To address these challenges, we introduce SignAvatar, a framework capable of both word-level sign language reconstruction and generation. SignAvatar employs a transformer-based conditional variational autoencoder architecture, effectively establishing relationships across different semantic modalities. Additionally, this approach incorporates a curriculum learning strategy to enhance the model's robustness and generalization, resulting in more realistic motions. Furthermore, we contribute the ASL3DWord dataset, composed of 3D joint rotation data for the body, hands, and face, for unique sign words. We demonstrate the effectiveness of SignAvatar through extensive experiments, showcasing its superior reconstruction and automatic generation capabilities. The code and dataset are available on the project page.
5/14/2024