Motion Capture from Inertial and Vision Sensors

0

Sign in to get full access
Overview
- This paper introduces a multi-modal motion capture dataset and benchmark for evaluating human motion estimation from inertial and vision sensors.
- The dataset captures ground truth 3D human pose using a professional motion capture system, along with synchronized inertial measurement unit (IMU) and RGB-D camera data.
- The authors propose evaluation metrics and benchmark results for several state-of-the-art motion estimation methods on the dataset.
Plain English Explanation
The paper presents a new dataset and evaluation framework for testing systems that can track human body movement using a combination of inertial sensors and cameras.
The researchers recorded people performing various actions while wearing special suits that precisely measure their 3D joint positions. At the same time, the people were recorded using inertial measurement units (like those in smartwatches) and RGB-D cameras (which can see depth information).
This multi-modal dataset allows researchers to develop and test new techniques for estimating 3D human pose from the inertial and visual data, without needing access to expensive motion capture equipment. The authors provide standard evaluation metrics to compare the performance of different motion estimation algorithms on this benchmark.
Technical Explanation
The paper presents a multi-modal motion capture dataset and evaluation framework for assessing human pose estimation from inertial and vision sensors. The dataset consists of synchronized data from a professional optical motion capture system, inertial measurement units (IMUs), and RGB-D cameras.
The authors capture ground truth 3D joint positions using a Vicon system while also recording IMU and RGB-D video of the same motions. This allows developing and evaluating techniques that leverage both inertial and visual cues for estimating 3D human pose.
The paper introduces several evaluation metrics to benchmark motion estimation performance, including joint position error, joint velocity error, and 3D joint trajectory error. The authors provide baseline results using state-of-the-art techniques like IMU-based and video-based pose estimation methods. The dataset and evaluation code are publicly available to facilitate further research in this area.
Critical Analysis
The paper provides a valuable multi-modal dataset and evaluation framework for human motion capture, addressing a key challenge in this field. By capturing synchronized ground truth 3D poses along with inertial and visual data, the dataset enables developing and benchmarking new techniques that fuse these complementary sensing modalities.
However, the dataset is limited to a single subject and a small set of motions. Expanding the dataset to include more diverse subjects, activities, and environmental conditions would further strengthen its utility for evaluating real-world motion estimation systems. Additionally, the paper does not explore the potential for combining inertial and vision-based methods to achieve better performance than either modality alone.
Conclusion
This paper introduces a novel multi-modal motion capture dataset and benchmark for evaluating human pose estimation from inertial and vision sensors. The dataset provides a valuable resource for developing and testing new techniques that leverage both sensing modalities to accurately track 3D body movements. The proposed evaluation metrics and baseline results establish a solid foundation for further advancing the state-of-the-art in this important area of human-computer interaction and computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Motion Capture from Inertial and Vision Sensors
Xiaodong Chen, Wu Liu, Qian Bao, Xinchen Liu, Quanwei Yang, Ruoli Dai, Tao Mei
Human motion capture is the foundation for many computer vision and graphics tasks. While industrial motion capture systems with complex camera arrays or expensive wearable sensors have been widely adopted in movie and game production, consumer-affordable and easy-to-use solutions for personal applications are still far from mature. To utilize a mixture of a monocular camera and very few inertial measurement units (IMUs) for accurate multi-modal human motion capture in daily life, we contribute MINIONS in this paper, a large-scale Motion capture dataset collected from INertial and visION Sensors. MINIONS has several featured properties: 1) large scale of over five million frames and 400 minutes duration; 2) multi-modality data of IMUs signals and RGB videos labeled with joint positions, joint rotations, SMPL parameters, etc.; 3) a diverse set of 146 fine-grained single and interactive actions with textual descriptions. With the proposed MINIONS, we conduct experiments on multi-modal motion capture and explore the possibilities of consumer-affordable motion capture using a monocular camera and very few IMUs. The experiment results emphasize the unique advantages of inertial and vision sensors, showcasing the promise of consumer-affordable multi-modal motion capture and providing a valuable resource for further research and development.
Read more7/24/2024
0
Masked Video and Body-worn IMU Autoencoder for Egocentric Action Recognition
Mingfang Zhang, Yifei Huang, Ruicong Liu, Yoichi Sato
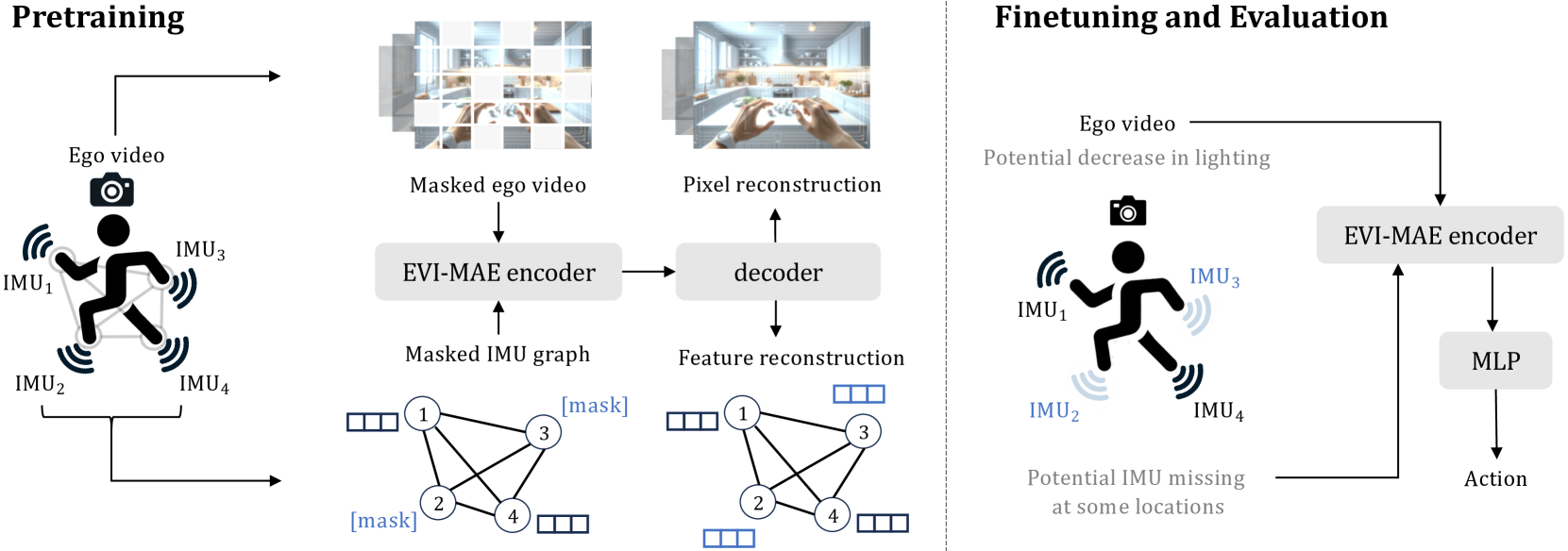
Compared with visual signals, Inertial Measurement Units (IMUs) placed on human limbs can capture accurate motion signals while being robust to lighting variation and occlusion. While these characteristics are intuitively valuable to help egocentric action recognition, the potential of IMUs remains under-explored. In this work, we present a novel method for action recognition that integrates motion data from body-worn IMUs with egocentric video. Due to the scarcity of labeled multimodal data, we design an MAE-based self-supervised pretraining method, obtaining strong multi-modal representations via modeling the natural correlation between visual and motion signals. To model the complex relation of multiple IMU devices placed across the body, we exploit the collaborative dynamics in multiple IMU devices and propose to embed the relative motion features of human joints into a graph structure. Experiments show our method can achieve state-of-the-art performance on multiple public datasets. The effectiveness of our MAE-based pretraining and graph-based IMU modeling are further validated by experiments in more challenging scenarios, including partially missing IMU devices and video quality corruption, promoting more flexible usages in the real world.
Read more7/10/2024
🎲
0
IMUSE: IMU-based Facial Expression Capture
Youjia Wang, Yiwen Wu, Hengan Zhou, Hongyang Lin, Xingyue Peng, Yingwenqi Jiang, Yingsheng Zhu, Guanpeng Long, Yatu Zhang, Jingya Wang, Lan Xu, Jingyi Yu
For facial motion capture and analysis, the dominated solutions are generally based on visual cues, which cannot protect privacy and are vulnerable to occlusions. Inertial measurement units (IMUs) serve as potential rescues yet are mainly adopted for full-body motion capture. In this paper, we propose IMUSE to fill the gap, a novel path for facial expression capture using purely IMU signals, significantly distant from previous visual solutions.The key design in our IMUSE is a trilogy. We first design micro-IMUs to suit facial capture, companion with an anatomy-driven IMU placement scheme. Then, we contribute a novel IMU-ARKit dataset, which provides rich paired IMU/visual signals for diverse facial expressions and performances. Such unique multi-modality brings huge potential for future directions like IMU-based facial behavior analysis. Moreover, utilizing IMU-ARKit, we introduce a strong baseline approach to accurately predict facial blendshape parameters from purely IMU signals. The IMUSE framework empowers us to perform accurate facial capture in scenarios where visual methods falter and simultaneously safeguard user privacy. We conduct extensive experiments about both the IMU configuration and technical components to validate the effectiveness of our IMUSE approach. Notably, IMUSE enables various potential and novel applications, i.e., facial capture against occlusions or in a moving performance. We will release our dataset and implementations to enrich more possibilities of facial capture and analysis in our community.
Read more6/13/2024

0
Mocap Everyone Everywhere: Lightweight Motion Capture With Smartwatches and a Head-Mounted Camera
Jiye Lee, Hanbyul Joo
We present a lightweight and affordable motion capture method based on two smartwatches and a head-mounted camera. In contrast to the existing approaches that use six or more expert-level IMU devices, our approach is much more cost-effective and convenient. Our method can make wearable motion capture accessible to everyone everywhere, enabling 3D full-body motion capture in diverse environments. As a key idea to overcome the extreme sparsity and ambiguities of sensor inputs with different modalities, we integrate 6D head poses obtained from the head-mounted cameras for motion estimation. To enable capture in expansive indoor and outdoor scenes, we propose an algorithm to track and update floor level changes to define head poses, coupled with a multi-stage Transformer-based regression module. We also introduce novel strategies leveraging visual cues of egocentric images to further enhance the motion capture quality while reducing ambiguities. We demonstrate the performance of our method on various challenging scenarios, including complex outdoor environments and everyday motions including object interactions and social interactions among multiple individuals.
Read more5/7/2024