MSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection

0

Sign in to get full access
Overview
- Presents a novel language-driven multi-modal fusion approach called MSCoTDet for improved multispectral pedestrian detection
- Leverages large language models to enhance visual cues and fuse information from different spectral modalities
- Aims to address challenges in multispectral pedestrian detection, such as handling varying lighting conditions and occlusions
Plain English Explanation
MSCoTDet is a new technique that combines language understanding with multi-modal sensor data to more accurately detect pedestrians in challenging environments. Traditional pedestrian detection systems often struggle with factors like changing lighting or partial occlusions. This research explores using large language models to assist in fusing information from different spectral cameras, like visible-light and infrared, to improve overall detection performance.
The key idea is to use language-derived features, such as descriptions of pedestrian appearance, to guide the fusion of visual cues from multiple spectral modalities. This allows the system to better account for variations in lighting, clothing, and occlusion that can confuse single-camera detectors. By tapping into the rich semantic understanding of language models, MSCoTDet can make more robust and context-aware decisions about where pedestrians are located in the scene.
Technical Explanation
The MSCoTDet architecture combines a Causal Mode Multiplexer for multi-modal fusion with a Multimodal Collaboration Network to leverage language-derived cues. A language model extracts semantic features from text descriptions, which are then fused with visual features from RGB-T object detection to produce improved pedestrian bounding boxes.
The key innovations include:
- Using language-derived appearance elements to guide multi-modal fusion
- A novel fusion mechanism that adaptively weights the different spectral inputs
- Extensive evaluation on challenging multispectral pedestrian detection benchmarks
Critical Analysis
The authors present a compelling approach to leveraging language understanding for enhancing multi-modal computer vision. By tapping into rich semantic knowledge, MSCoTDet appears to offer significant performance gains over prior multispectral pedestrian detectors.
However, the paper does not address potential limitations, such as the reliance on high-quality language models and the computational overhead of the fusion process. There are also open questions about the broader generalizability of this approach beyond pedestrian detection.
Further research is needed to understand the tradeoffs and failure modes of language-driven multi-modal fusion. Careful consideration of privacy, bias, and ethical implications will also be important as these techniques become more prevalent.
Conclusion
The MSCoTDet framework demonstrates the power of combining language understanding with multi-modal sensor fusion for robust computer vision applications. By leveraging rich semantic cues, the system can more effectively handle the challenges of pedestrian detection in complex environments.
While further research is needed, this work represents an exciting step forward in exploiting the synergies between language and vision to build smarter and more capable AI systems. As this technology matures, it could have significant implications for safety-critical applications like autonomous vehicles and surveillance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection
Taeheon Kim, Sangyun Chung, Damin Yeom, Youngjoon Yu, Hak Gu Kim, Yong Man Ro
Multispectral pedestrian detection is attractive for around-the-clock applications due to the complementary information between RGB and thermal modalities. However, current models often fail to detect pedestrians in certain cases (e.g., thermal-obscured pedestrians), particularly due to the modality bias learned from statistically biased datasets. In this paper, we investigate how to mitigate modality bias in multispectral pedestrian detection using Large Language Models (LLMs). Accordingly, we design a Multispectral Chain-of-Thought (MSCoT) prompting strategy, which prompts the LLM to perform multispectral pedestrian detection. Moreover, we propose a novel Multispectral Chain-of-Thought Detection (MSCoTDet) framework that integrates MSCoT prompting into multispectral pedestrian detection. To this end, we design a Language-driven Multi-modal Fusion (LMF) strategy that enables fusing the outputs of MSCoT prompting with the detection results of vision-based multispectral pedestrian detection models. Extensive experiments validate that MSCoTDet effectively mitigates modality biases and improves multispectral pedestrian detection.
Read more5/30/2024
0
Causal Mode Multiplexer: A Novel Framework for Unbiased Multispectral Pedestrian Detection
Taeheon Kim, Sebin Shin, Youngjoon Yu, Hak Gu Kim, Yong Man Ro
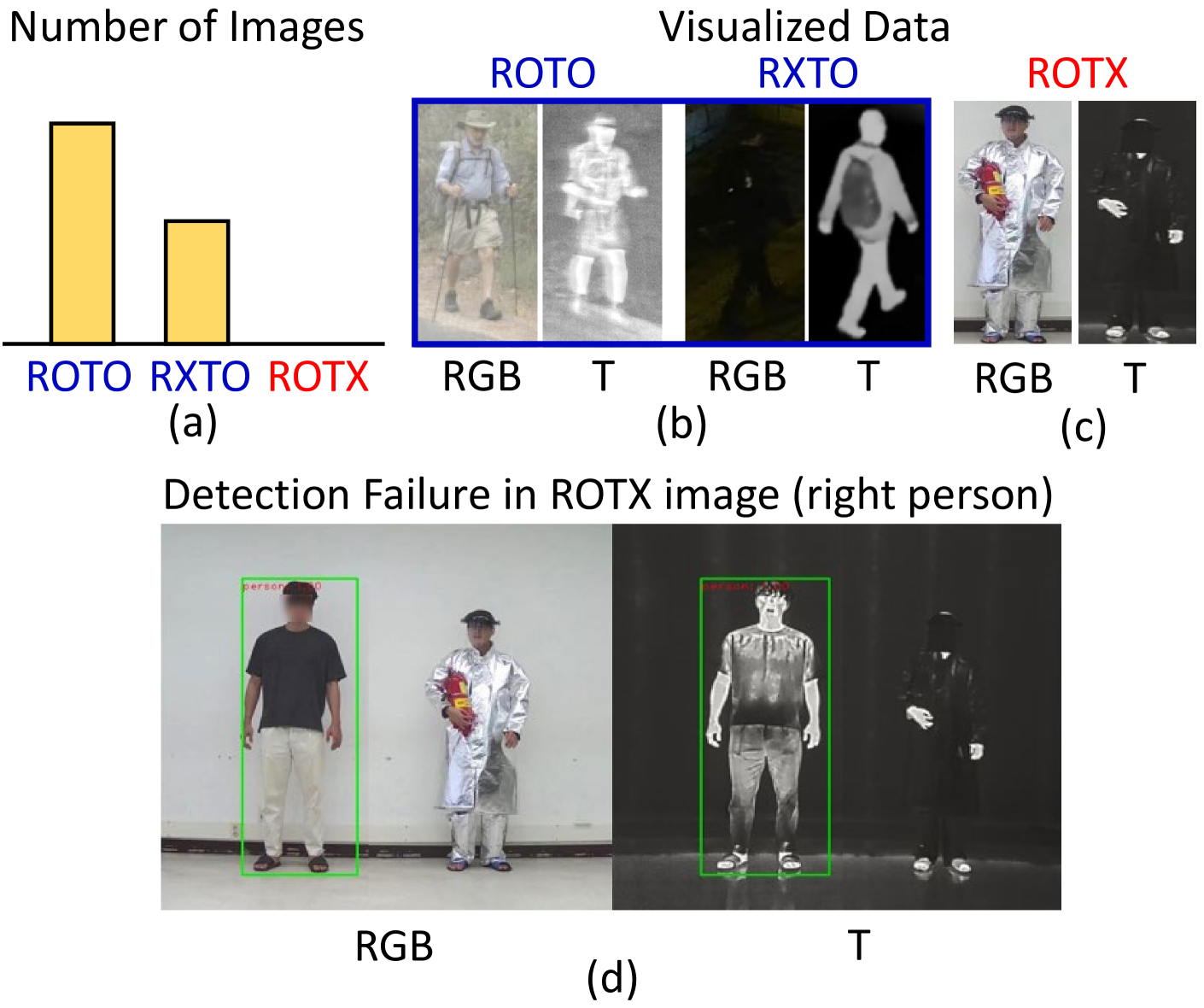
RGBT multispectral pedestrian detection has emerged as a promising solution for safety-critical applications that require day/night operations. However, the modality bias problem remains unsolved as multispectral pedestrian detectors learn the statistical bias in datasets. Specifically, datasets in multispectral pedestrian detection mainly distribute between ROTO (day) and RXTO (night) data; the majority of the pedestrian labels statistically co-occur with their thermal features. As a result, multispectral pedestrian detectors show poor generalization ability on examples beyond this statistical correlation, such as ROTX data. To address this problem, we propose a novel Causal Mode Multiplexer (CMM) framework that effectively learns the causalities between multispectral inputs and predictions. Moreover, we construct a new dataset (ROTX-MP) to evaluate modality bias in multispectral pedestrian detection. ROTX-MP mainly includes ROTX examples not presented in previous datasets. Extensive experiments demonstrate that our proposed CMM framework generalizes well on existing datasets (KAIST, CVC-14, FLIR) and the new ROTX-MP. We will release our new dataset to the public for future research.
Read more4/8/2024

0
When Pedestrian Detection Meets Multi-Modal Learning: Generalist Model and Benchmark Dataset
Yi Zhang, Wang Zeng, Sheng Jin, Chen Qian, Ping Luo, Wentao Liu
Recent years have witnessed increasing research attention towards pedestrian detection by taking the advantages of different sensor modalities (e.g. RGB, IR, Depth, LiDAR and Event). However, designing a unified generalist model that can effectively process diverse sensor modalities remains a challenge. This paper introduces MMPedestron, a novel generalist model for multimodal perception. Unlike previous specialist models that only process one or a pair of specific modality inputs, MMPedestron is able to process multiple modal inputs and their dynamic combinations. The proposed approach comprises a unified encoder for modal representation and fusion and a general head for pedestrian detection. We introduce two extra learnable tokens, i.e. MAA and MAF, for adaptive multi-modal feature fusion. In addition, we construct the MMPD dataset, the first large-scale benchmark for multi-modal pedestrian detection. This benchmark incorporates existing public datasets and a newly collected dataset called EventPed, covering a wide range of sensor modalities including RGB, IR, Depth, LiDAR, and Event data. With multi-modal joint training, our model achieves state-of-the-art performance on a wide range of pedestrian detection benchmarks, surpassing leading models tailored for specific sensor modality. For example, it achieves 71.1 AP on COCO-Persons and 72.6 AP on LLVIP. Notably, our model achieves comparable performance to the InternImage-H model on CrowdHuman with 30x smaller parameters. Codes and data are available at https://github.com/BubblyYi/MMPedestron.
Read more7/16/2024
🔎
0
TFDet: Target-Aware Fusion for RGB-T Pedestrian Detection
Xue Zhang, Xiaohan Zhang, Jiangtao Wang, Jiacheng Ying, Zehua Sheng, Heng Yu, Chunguang Li, Hui-Liang Shen
Pedestrian detection plays a critical role in computer vision as it contributes to ensuring traffic safety. Existing methods that rely solely on RGB images suffer from performance degradation under low-light conditions due to the lack of useful information. To address this issue, recent multispectral detection approaches have combined thermal images to provide complementary information and have obtained enhanced performances. Nevertheless, few approaches focus on the negative effects of false positives caused by noisy fused feature maps. Different from them, we comprehensively analyze the impacts of false positives on the detection performance and find that enhancing feature contrast can significantly reduce these false positives. In this paper, we propose a novel target-aware fusion strategy for multispectral pedestrian detection, named TFDet. TFDet achieves state-of-the-art performance on two multispectral pedestrian benchmarks, KAIST and LLVIP. TFDet can easily extend to multi-class object detection scenarios. It outperforms the previous best approaches on two multispectral object detection benchmarks, FLIR and M3FD. Importantly, TFDet has comparable inference efficiency to the previous approaches, and has remarkably good detection performance even under low-light conditions, which is a significant advancement for ensuring road safety.
Read more8/28/2024