When Pedestrian Detection Meets Multi-Modal Learning: Generalist Model and Benchmark Dataset

0

Sign in to get full access
Overview
- This paper introduces a new generalist model and benchmark dataset for pedestrian detection using multi-modal learning.
- The proposed model combines visual and non-visual modalities, such as depth and motion information, to improve pedestrian detection performance.
- The authors also introduce a new large-scale benchmark dataset for evaluating multi-modal pedestrian detection systems.
Plain English Explanation
The paper is focused on improving pedestrian detection, which is the task of identifying and locating people in images or video. Pedestrian detection is an important capability for applications like self-driving cars, surveillance systems, and robotics.
Traditionally, pedestrian detection systems have relied primarily on visual information from cameras. However, the authors argue that incorporating additional modalities, such as depth information from lidar or motion data from inertial sensors, can significantly improve detection accuracy.
To explore this idea, the researchers developed a new "generalist" model that can fuse together multiple data sources, including visual, depth, and motion cues. By learning to combine these diverse inputs, the model can make more robust and reliable pedestrian detections compared to approaches that only use a single modality.
In addition to the new model, the paper also introduces a large-scale benchmark dataset for evaluating multi-modal pedestrian detection systems. This dataset, which the authors call "MMPD", provides a standardized way for researchers to compare the performance of different detection approaches.
Technical Explanation
The core of the paper is the proposed generalist model for multi-modal pedestrian detection. This model takes in a variety of input modalities, including RGB images, depth maps, and optical flow, and learns to fuse these signals to produce accurate pedestrian detections.
The model architecture is based on a MMCN backbone, which uses a modular design to enable flexible combination of different data sources. The authors also incorporate AMFD and CMM techniques to adaptively fuse the multi-modal inputs and mitigate potential biases.
Experiments on the new MMPD dataset demonstrate that the generalist model significantly outperforms single-modal baselines, highlighting the benefits of multi-modal learning for pedestrian detection. The authors also provide detailed analyses of the model's performance under various conditions, such as occlusion and low-visibility scenarios.
Critical Analysis
The authors have made a compelling case for the advantages of multi-modal learning for pedestrian detection. By incorporating diverse data sources, the proposed generalist model is able to achieve better performance than vision-only approaches, especially in challenging real-world conditions.
However, the paper does not fully address the potential computational and storage overhead of the multi-modal approach. Fusing multiple data streams may come at the cost of increased model complexity and resource requirements, which could limit the practical deployment of such systems.
Additionally, the authors do not explore the robustness of their model to sensor failures or degradation. In real-world scenarios, it is crucial for pedestrian detection systems to maintain reliable performance even when one or more input modalities are unavailable or unreliable.
Further research could also investigate the generalization capabilities of the model, such as its ability to perform well on diverse datasets and in different environmental conditions. Evaluating the model's performance on a wider range of benchmarks would help to better understand its strengths and limitations.
Conclusion
This paper presents a significant step forward in the field of pedestrian detection by introducing a generalist multi-modal model and a new benchmark dataset. By leveraging diverse data sources, the proposed approach demonstrates improved detection accuracy compared to single-modal methods, particularly in challenging scenarios.
The availability of the MMPD dataset is also a valuable contribution, as it provides a standardized platform for evaluating and comparing the performance of different multi-modal pedestrian detection systems.
While the paper highlights the potential benefits of multi-modal learning, further research is needed to address practical deployment challenges and ensure the robustness and generalization of these techniques. Nevertheless, this work represents an important advancement in the quest to develop reliable and versatile pedestrian detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
When Pedestrian Detection Meets Multi-Modal Learning: Generalist Model and Benchmark Dataset
Yi Zhang, Wang Zeng, Sheng Jin, Chen Qian, Ping Luo, Wentao Liu
Recent years have witnessed increasing research attention towards pedestrian detection by taking the advantages of different sensor modalities (e.g. RGB, IR, Depth, LiDAR and Event). However, designing a unified generalist model that can effectively process diverse sensor modalities remains a challenge. This paper introduces MMPedestron, a novel generalist model for multimodal perception. Unlike previous specialist models that only process one or a pair of specific modality inputs, MMPedestron is able to process multiple modal inputs and their dynamic combinations. The proposed approach comprises a unified encoder for modal representation and fusion and a general head for pedestrian detection. We introduce two extra learnable tokens, i.e. MAA and MAF, for adaptive multi-modal feature fusion. In addition, we construct the MMPD dataset, the first large-scale benchmark for multi-modal pedestrian detection. This benchmark incorporates existing public datasets and a newly collected dataset called EventPed, covering a wide range of sensor modalities including RGB, IR, Depth, LiDAR, and Event data. With multi-modal joint training, our model achieves state-of-the-art performance on a wide range of pedestrian detection benchmarks, surpassing leading models tailored for specific sensor modality. For example, it achieves 71.1 AP on COCO-Persons and 72.6 AP on LLVIP. Notably, our model achieves comparable performance to the InternImage-H model on CrowdHuman with 30x smaller parameters. Codes and data are available at https://github.com/BubblyYi/MMPedestron.
Read more7/16/2024

0
MSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection
Taeheon Kim, Sangyun Chung, Damin Yeom, Youngjoon Yu, Hak Gu Kim, Yong Man Ro
Multispectral pedestrian detection is attractive for around-the-clock applications due to the complementary information between RGB and thermal modalities. However, current models often fail to detect pedestrians in certain cases (e.g., thermal-obscured pedestrians), particularly due to the modality bias learned from statistically biased datasets. In this paper, we investigate how to mitigate modality bias in multispectral pedestrian detection using Large Language Models (LLMs). Accordingly, we design a Multispectral Chain-of-Thought (MSCoT) prompting strategy, which prompts the LLM to perform multispectral pedestrian detection. Moreover, we propose a novel Multispectral Chain-of-Thought Detection (MSCoTDet) framework that integrates MSCoT prompting into multispectral pedestrian detection. To this end, we design a Language-driven Multi-modal Fusion (LMF) strategy that enables fusing the outputs of MSCoT prompting with the detection results of vision-based multispectral pedestrian detection models. Extensive experiments validate that MSCoTDet effectively mitigates modality biases and improves multispectral pedestrian detection.
Read more5/30/2024
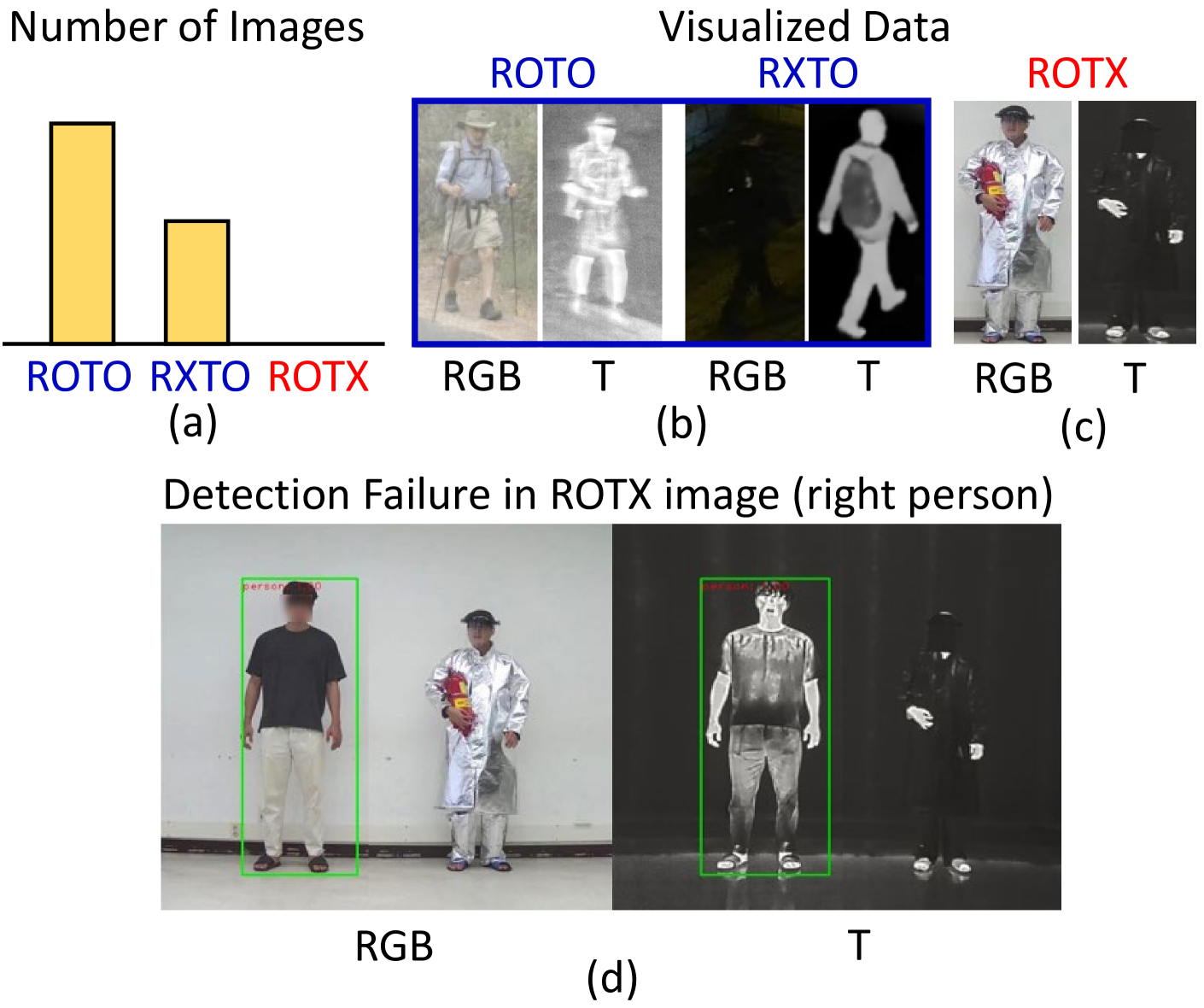
0
Causal Mode Multiplexer: A Novel Framework for Unbiased Multispectral Pedestrian Detection
Taeheon Kim, Sebin Shin, Youngjoon Yu, Hak Gu Kim, Yong Man Ro
RGBT multispectral pedestrian detection has emerged as a promising solution for safety-critical applications that require day/night operations. However, the modality bias problem remains unsolved as multispectral pedestrian detectors learn the statistical bias in datasets. Specifically, datasets in multispectral pedestrian detection mainly distribute between ROTO (day) and RXTO (night) data; the majority of the pedestrian labels statistically co-occur with their thermal features. As a result, multispectral pedestrian detectors show poor generalization ability on examples beyond this statistical correlation, such as ROTX data. To address this problem, we propose a novel Causal Mode Multiplexer (CMM) framework that effectively learns the causalities between multispectral inputs and predictions. Moreover, we construct a new dataset (ROTX-MP) to evaluate modality bias in multispectral pedestrian detection. ROTX-MP mainly includes ROTX examples not presented in previous datasets. Extensive experiments demonstrate that our proposed CMM framework generalizes well on existing datasets (KAIST, CVC-14, FLIR) and the new ROTX-MP. We will release our new dataset to the public for future research.
Read more4/8/2024

0
Robust Multimodal 3D Object Detection via Modality-Agnostic Decoding and Proximity-based Modality Ensemble
Juhan Cha, Minseok Joo, Jihwan Park, Sanghyeok Lee, Injae Kim, Hyunwoo J. Kim
Recent advancements in 3D object detection have benefited from multi-modal information from the multi-view cameras and LiDAR sensors. However, the inherent disparities between the modalities pose substantial challenges. We observe that existing multi-modal 3D object detection methods heavily rely on the LiDAR sensor, treating the camera as an auxiliary modality for augmenting semantic details. This often leads to not only underutilization of camera data but also significant performance degradation in scenarios where LiDAR data is unavailable. Additionally, existing fusion methods overlook the detrimental impact of sensor noise induced by environmental changes, on detection performance. In this paper, we propose MEFormer to address the LiDAR over-reliance problem by harnessing critical information for 3D object detection from every available modality while concurrently safeguarding against corrupted signals during the fusion process. Specifically, we introduce Modality Agnostic Decoding (MOAD) that extracts geometric and semantic features with a shared transformer decoder regardless of input modalities and provides promising improvement with a single modality as well as multi-modality. Additionally, our Proximity-based Modality Ensemble (PME) module adaptively utilizes the strengths of each modality depending on the environment while mitigating the effects of a noisy sensor. Our MEFormer achieves state-of-the-art performance of 73.9% NDS and 71.5% mAP in the nuScenes validation set. Extensive analyses validate that our MEFormer improves robustness against challenging conditions such as sensor malfunctions or environmental changes. The source code is available at https://github.com/hanchaa/MEFormer
Read more8/20/2024