Causal Mode Multiplexer: A Novel Framework for Unbiased Multispectral Pedestrian Detection

0
Sign in to get full access
Overview
- This paper introduces a novel framework called Causal Mode Multiplexer (CMM) for unbiased multispectral pedestrian detection.
- The key idea is to model the causal relationships between different sensor modalities (e.g., RGB, thermal) and use this information to improve pedestrian detection performance.
- The proposed CMM framework leverages a Structural Causal Model (SCM) to capture the causal dependencies between sensor modalities and the target pedestrian detection task.
Plain English Explanation
The paper presents a new approach called Causal Mode Multiplexer (CMM) to tackle the problem of pedestrian detection using multiple sensor modalities, such as RGB cameras and thermal cameras. Pedestrian detection is a crucial task in many applications, like self-driving cars and surveillance systems, but it can be challenging when different sensors are used.
The key insight behind CMM is to model the causal relationships between the sensor modalities and the target pedestrian detection task. This means understanding how the information from different sensors, like color and heat signatures, is causally linked to the presence of pedestrians in the scene. By capturing these causal dependencies, the CMM framework can then use this knowledge to improve the performance of the pedestrian detection model, making it more robust and less biased towards any particular sensor.
For example, if the model learns that thermal cameras are more reliable for detecting pedestrians in low-light conditions, it can use this causal insight to better integrate the thermal camera data and improve the overall pedestrian detection accuracy, even in challenging scenarios.
Technical Explanation
The paper introduces a novel framework called Causal Mode Multiplexer (CMM) for unbiased multispectral pedestrian detection. The key component of the CMM framework is the use of a Structural Causal Model (SCM) to capture the causal relationships between the different sensor modalities (e.g., RGB, thermal) and the target pedestrian detection task.
The SCM allows the model to learn how the information from the various sensors is causally linked to the presence of pedestrians in the scene. This causal understanding is then leveraged to improve the performance of the pedestrian detection model, making it more robust and less biased towards any particular sensor modality.
The paper presents a detailed architecture of the CMM framework, which consists of several key components:
- Causal Encoder: This module learns the causal dependencies between the sensor modalities and the target task using the SCM.
- Causal Fusion: This component intelligently fuses the information from the different sensors based on the causal insights learned by the Causal Encoder.
- Causal Detector: The final pedestrian detection model is built on top of the Causal Fusion module, leveraging the causal knowledge to improve its performance.
The authors evaluate the CMM framework on several multispectral pedestrian detection benchmarks and show that it outperforms state-of-the-art approaches, particularly in challenging scenarios where the sensor modalities exhibit different biases or availability.
Critical Analysis
The paper presents a well-designed and technically sound approach to address the problem of unbiased multispectral pedestrian detection. The use of a Structural Causal Model to capture the causal relationships between sensor modalities and the target task is a novel and promising idea that can have broader applications in multimodal learning.
However, the paper does not discuss certain limitations or potential issues with the proposed CMM framework. For example, the authors do not address the scalability of the SCM as the number of sensor modalities increases, or the sensitivity of the causal modeling to the quality and completeness of the training data.
Additionally, while the paper demonstrates the effectiveness of the CMM framework on standard benchmarks, it would be valuable to see an analysis of its performance in real-world deployment scenarios, where factors like sensor failures, environmental conditions, and deployment costs may play a more significant role.
Further research could also explore the potential of the CMM framework in other multimodal learning tasks beyond pedestrian detection, such as cross-modality gait recognition, RGB-thermal scene parsing, or multimodal emotion recognition.
Conclusion
The Causal Mode Multiplexer (CMM) framework proposed in this paper represents a significant advancement in the field of unbiased multispectral pedestrian detection. By leveraging a Structural Causal Model to capture the causal relationships between sensor modalities and the target task, the CMM framework can learn to intelligently fuse the information from different sensors, leading to improved robustness and performance, even in challenging scenarios.
The potential impact of this research extends beyond pedestrian detection, as the causal modeling approach could be applied to a wide range of multimodal learning problems, such as mitigating unimodal biases in large language models. As the reliance on multimodal data continues to grow in various industries, the CMM framework and its underlying causal principles could play a crucial role in developing more reliable and unbiased AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Causal Mode Multiplexer: A Novel Framework for Unbiased Multispectral Pedestrian Detection
Taeheon Kim, Sebin Shin, Youngjoon Yu, Hak Gu Kim, Yong Man Ro
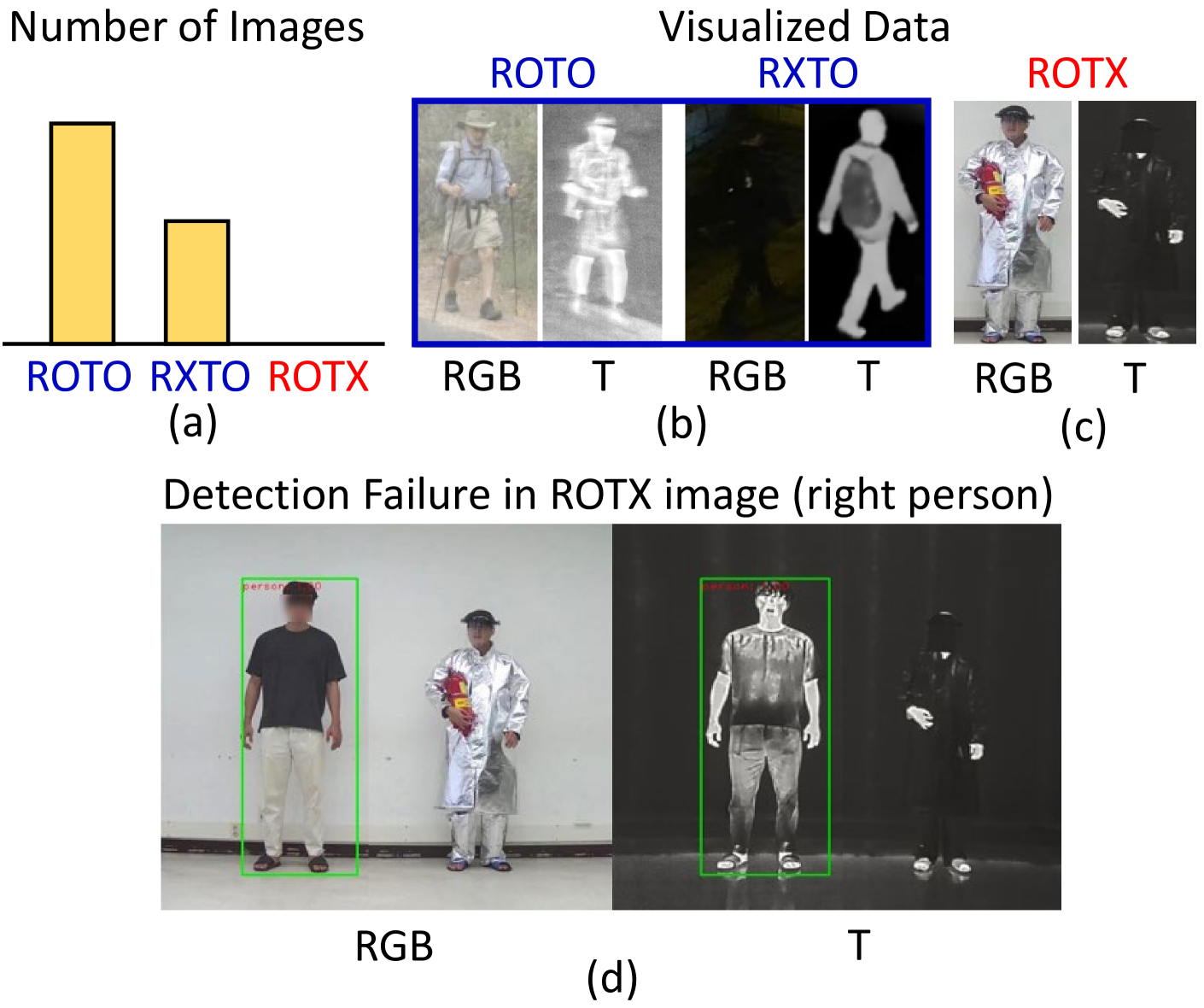
RGBT multispectral pedestrian detection has emerged as a promising solution for safety-critical applications that require day/night operations. However, the modality bias problem remains unsolved as multispectral pedestrian detectors learn the statistical bias in datasets. Specifically, datasets in multispectral pedestrian detection mainly distribute between ROTO (day) and RXTO (night) data; the majority of the pedestrian labels statistically co-occur with their thermal features. As a result, multispectral pedestrian detectors show poor generalization ability on examples beyond this statistical correlation, such as ROTX data. To address this problem, we propose a novel Causal Mode Multiplexer (CMM) framework that effectively learns the causalities between multispectral inputs and predictions. Moreover, we construct a new dataset (ROTX-MP) to evaluate modality bias in multispectral pedestrian detection. ROTX-MP mainly includes ROTX examples not presented in previous datasets. Extensive experiments demonstrate that our proposed CMM framework generalizes well on existing datasets (KAIST, CVC-14, FLIR) and the new ROTX-MP. We will release our new dataset to the public for future research.
Read more4/8/2024

0
MSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection
Taeheon Kim, Sangyun Chung, Damin Yeom, Youngjoon Yu, Hak Gu Kim, Yong Man Ro
Multispectral pedestrian detection is attractive for around-the-clock applications due to the complementary information between RGB and thermal modalities. However, current models often fail to detect pedestrians in certain cases (e.g., thermal-obscured pedestrians), particularly due to the modality bias learned from statistically biased datasets. In this paper, we investigate how to mitigate modality bias in multispectral pedestrian detection using Large Language Models (LLMs). Accordingly, we design a Multispectral Chain-of-Thought (MSCoT) prompting strategy, which prompts the LLM to perform multispectral pedestrian detection. Moreover, we propose a novel Multispectral Chain-of-Thought Detection (MSCoTDet) framework that integrates MSCoT prompting into multispectral pedestrian detection. To this end, we design a Language-driven Multi-modal Fusion (LMF) strategy that enables fusing the outputs of MSCoT prompting with the detection results of vision-based multispectral pedestrian detection models. Extensive experiments validate that MSCoTDet effectively mitigates modality biases and improves multispectral pedestrian detection.
Read more5/30/2024

0
When Pedestrian Detection Meets Multi-Modal Learning: Generalist Model and Benchmark Dataset
Yi Zhang, Wang Zeng, Sheng Jin, Chen Qian, Ping Luo, Wentao Liu
Recent years have witnessed increasing research attention towards pedestrian detection by taking the advantages of different sensor modalities (e.g. RGB, IR, Depth, LiDAR and Event). However, designing a unified generalist model that can effectively process diverse sensor modalities remains a challenge. This paper introduces MMPedestron, a novel generalist model for multimodal perception. Unlike previous specialist models that only process one or a pair of specific modality inputs, MMPedestron is able to process multiple modal inputs and their dynamic combinations. The proposed approach comprises a unified encoder for modal representation and fusion and a general head for pedestrian detection. We introduce two extra learnable tokens, i.e. MAA and MAF, for adaptive multi-modal feature fusion. In addition, we construct the MMPD dataset, the first large-scale benchmark for multi-modal pedestrian detection. This benchmark incorporates existing public datasets and a newly collected dataset called EventPed, covering a wide range of sensor modalities including RGB, IR, Depth, LiDAR, and Event data. With multi-modal joint training, our model achieves state-of-the-art performance on a wide range of pedestrian detection benchmarks, surpassing leading models tailored for specific sensor modality. For example, it achieves 71.1 AP on COCO-Persons and 72.6 AP on LLVIP. Notably, our model achieves comparable performance to the InternImage-H model on CrowdHuman with 30x smaller parameters. Codes and data are available at https://github.com/BubblyYi/MMPedestron.
Read more7/16/2024
0
RGB-T Object Detection via Group Shuffled Multi-receptive Attention and Multi-modal Supervision
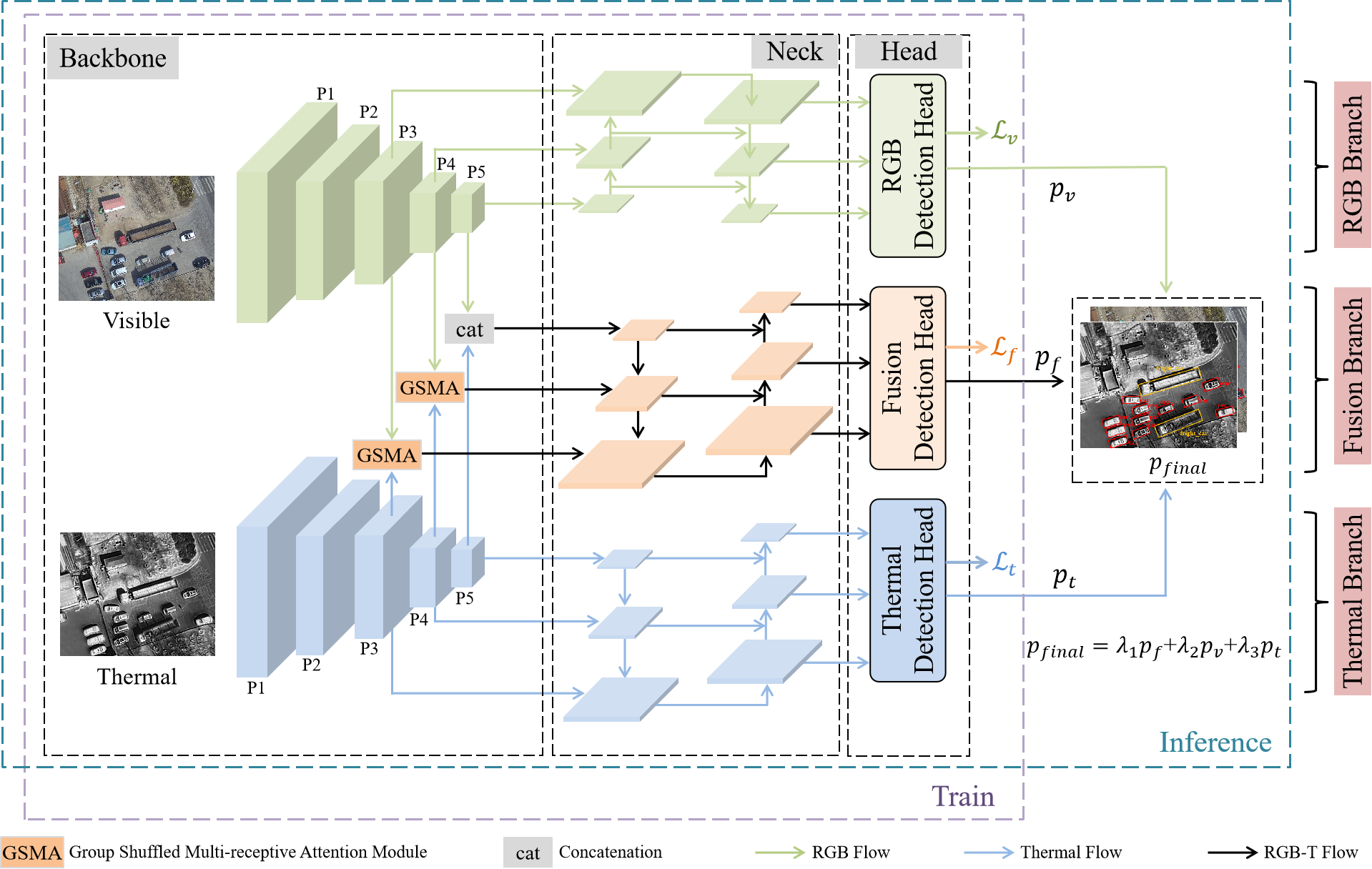
Jinzhong Wang, Xuetao Tian, Shun Dai, Tao Zhuo, Haorui Zeng, Hongjuan Liu, Jiaqi Liu, Xiuwei Zhang, Yanning Zhang
Multispectral object detection, utilizing both visible (RGB) and thermal infrared (T) modals, has garnered significant attention for its robust performance across diverse weather and lighting conditions. However, effectively exploiting the complementarity between RGB-T modals while maintaining efficiency remains a critical challenge. In this paper, a very simple Group Shuffled Multi-receptive Attention (GSMA) module is proposed to extract and combine multi-scale RGB and thermal features. Then, the extracted multi-modal features are directly integrated with a multi-level path aggregation neck, which significantly improves the fusion effect and efficiency. Meanwhile, multi-modal object detection often adopts union annotations for both modals. This kind of supervision is not sufficient and unfair, since objects observed in one modal may not be seen in the other modal. To solve this issue, Multi-modal Supervision (MS) is proposed to sufficiently supervise RGB-T object detection. Comprehensive experiments on two challenging benchmarks, KAIST and DroneVehicle, demonstrate the proposed model achieves the state-of-the-art accuracy while maintaining competitive efficiency.
Read more5/30/2024