Multi-agent reinforcement learning for the control of three-dimensional Rayleigh-B'enard convection

0

Sign in to get full access
Overview
- This paper explores the use of multi-agent reinforcement learning (MARL) for controlling three-dimensional Rayleigh-Bénard convection, a complex fluid dynamics phenomenon.
- The researchers developed a MARL-based approach to regulate the flow and temperature fields in a Rayleigh-Bénard convection system.
- The goal was to demonstrate the effectiveness of MARL in optimizing the system's performance and achieving desired control objectives.
Plain English Explanation
Rayleigh-Bénard convection is a type of fluid flow that occurs when a fluid layer is heated from below and cooled from above. This creates a temperature gradient, which can lead to complex, swirling patterns in the fluid. Controlling and optimizing these fluid dynamics can be challenging, but has applications in areas like flow control and thermal management.
In this paper, the researchers used a multi-agent reinforcement learning (MARL) approach to control the three-dimensional Rayleigh-Bénard convection system. MARL involves training multiple autonomous agents, each with its own decision-making capabilities, to work together to achieve a common goal.
The idea was to have these agents learn how to adjust various parameters of the Rayleigh-Bénard system, such as the heating and cooling, in order to maintain desirable flow and temperature patterns. By using MARL, the researchers hoped to find an optimal control strategy that could adapt to the complex, dynamic nature of the Rayleigh-Bénard convection.
Technical Explanation
The researchers developed a MARL-based approach to control the three-dimensional Rayleigh-Bénard convection system. They used a model-based deep reinforcement learning framework, where the agents learned to control the system by interacting with a surrogate model of the Rayleigh-Bénard convection.
The key elements of the paper include:
- Experiment Design: The researchers simulated a three-dimensional Rayleigh-Bénard convection system and divided it into multiple control zones, each with its own agent responsible for adjusting the heating and cooling in that zone.
- Architecture: The agents used a deep neural network to learn the optimal control policies, with the goal of maintaining desired flow and temperature patterns in the system.
- Insights: The MARL approach was able to outperform traditional control methods, demonstrating the potential for using reinforcement learning to optimize complex fluid dynamics systems.
Critical Analysis
The paper provides a promising demonstration of using MARL to control a complex fluid dynamics system. However, it is important to note that the research was conducted in a simulated environment, and the performance of the MARL approach in a real-world Rayleigh-Bénard convection system may differ.
Additionally, the paper does not explore the scalability of the MARL approach as the number of control zones or agents increases. Further research would be needed to understand how the approach would perform in larger, more complex systems.
It would also be interesting to see how the MARL approach compares to other advanced deep reinforcement learning methods for fluid dynamics control, and whether there are any limitations or tradeoffs involved in using MARL compared to other techniques.
Conclusion
This paper presents a novel application of multi-agent reinforcement learning for controlling three-dimensional Rayleigh-Bénard convection, a complex fluid dynamics phenomenon. The MARL-based approach was able to outperform traditional control methods, demonstrating the potential for using reinforcement learning to optimize the performance of such systems.
While the research was conducted in a simulated environment, the findings suggest that MARL could be a valuable tool for flow control and thermal management applications. Further research is needed to explore the scalability and real-world applicability of the approach, as well as how it compares to other advanced reinforcement learning techniques in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-agent reinforcement learning for the control of three-dimensional Rayleigh-B'enard convection
Joel Vasanth, Jean Rabault, Francisco Alc'antara-'Avila, Mikael Mortensen, Ricardo Vinuesa
Deep reinforcement learning (DRL) has found application in numerous use-cases pertaining to flow control. Multi-agent RL (MARL), a variant of DRL, has shown to be more effective than single-agent RL in controlling flows exhibiting locality and translational invariance. We present, for the first time, an implementation of MARL-based control of three-dimensional Rayleigh-B'enard convection (RBC). Control is executed by modifying the temperature distribution along the bottom wall divided into multiple control segments, each of which acts as an independent agent. Two regimes of RBC are considered at Rayleigh numbers $mathrm{Ra}=500$ and $750$. Evaluation of the learned control policy reveals a reduction in convection intensity by $23.5%$ and $8.7%$ at $mathrm{Ra}=500$ and $750$, respectively. The MARL controller converts irregularly shaped convective patterns to regular straight rolls with lower convection that resemble flow in a relatively more stable regime. We draw comparisons with proportional control at both $mathrm{Ra}$ and show that MARL is able to outperform the proportional controller. The learned control strategy is complex, featuring different non-linear segment-wise actuator delays and actuation magnitudes. We also perform successful evaluations on a larger domain than used for training, demonstrating that the invariant property of MARL allows direct transfer of the learnt policy.
Read more8/1/2024

0
Model-Based Reinforcement Learning for Control of Strongly-Disturbed Unsteady Aerodynamic Flows
Zhecheng Liu (University of California, Los Angeles), Diederik Beckers (California Institute of Technology), Jeff D. Eldredge (University of California, Los Angeles)
The intrinsic high dimension of fluid dynamics is an inherent challenge to control of aerodynamic flows, and this is further complicated by a flow's nonlinear response to strong disturbances. Deep reinforcement learning, which takes advantage of the exploratory aspects of reinforcement learning (RL) and the rich nonlinearity of a deep neural network, provides a promising approach to discover feasible control strategies. However, the typical model-free approach to reinforcement learning requires a significant amount of interaction between the flow environment and the RL agent during training, and this high training cost impedes its development and application. In this work, we propose a model-based reinforcement learning (MBRL) approach by incorporating a novel reduced-order model as a surrogate for the full environment. The model consists of a physics-augmented autoencoder, which compresses high-dimensional CFD flow field snaphsots into a three-dimensional latent space, and a latent dynamics model that is trained to accurately predict the long-time dynamics of trajectories in the latent space in response to action sequences. The robustness and generalizability of the model is demonstrated in two distinct flow environments, a pitching airfoil in a highly disturbed environment and a vertical-axis wind turbine in a disturbance-free environment. Based on the trained model in the first problem, we realize an MBRL strategy to mitigate lift variation during gust-airfoil encounters. We demonstrate that the policy learned in the reduced-order environment translates to an effective control strategy in the full CFD environment.
Read more8/28/2024
🏅
0
Safety Constrained Multi-Agent Reinforcement Learning for Active Voltage Control
Yang Qu, Jinming Ma, Feng Wu
Active voltage control presents a promising avenue for relieving power congestion and enhancing voltage quality, taking advantage of the distributed controllable generators in the power network, such as roof-top photovoltaics. While Multi-Agent Reinforcement Learning (MARL) has emerged as a compelling approach to address this challenge, existing MARL approaches tend to overlook the constrained optimization nature of this problem, failing in guaranteeing safety constraints. In this paper, we formalize the active voltage control problem as a constrained Markov game and propose a safety-constrained MARL algorithm. We expand the primal-dual optimization RL method to multi-agent settings, and augment it with a novel approach of double safety estimation to learn the policy and to update the Lagrange-multiplier. In addition, we proposed different cost functions and investigated their influences on the behavior of our constrained MARL method. We evaluate our approach in the power distribution network simulation environment with real-world scale scenarios. Experimental results demonstrate the effectiveness of the proposed method compared with the state-of-the-art MARL methods. This paper is published at url{https://www.ijcai.org/Proceedings/2024/}.
Read more9/4/2024
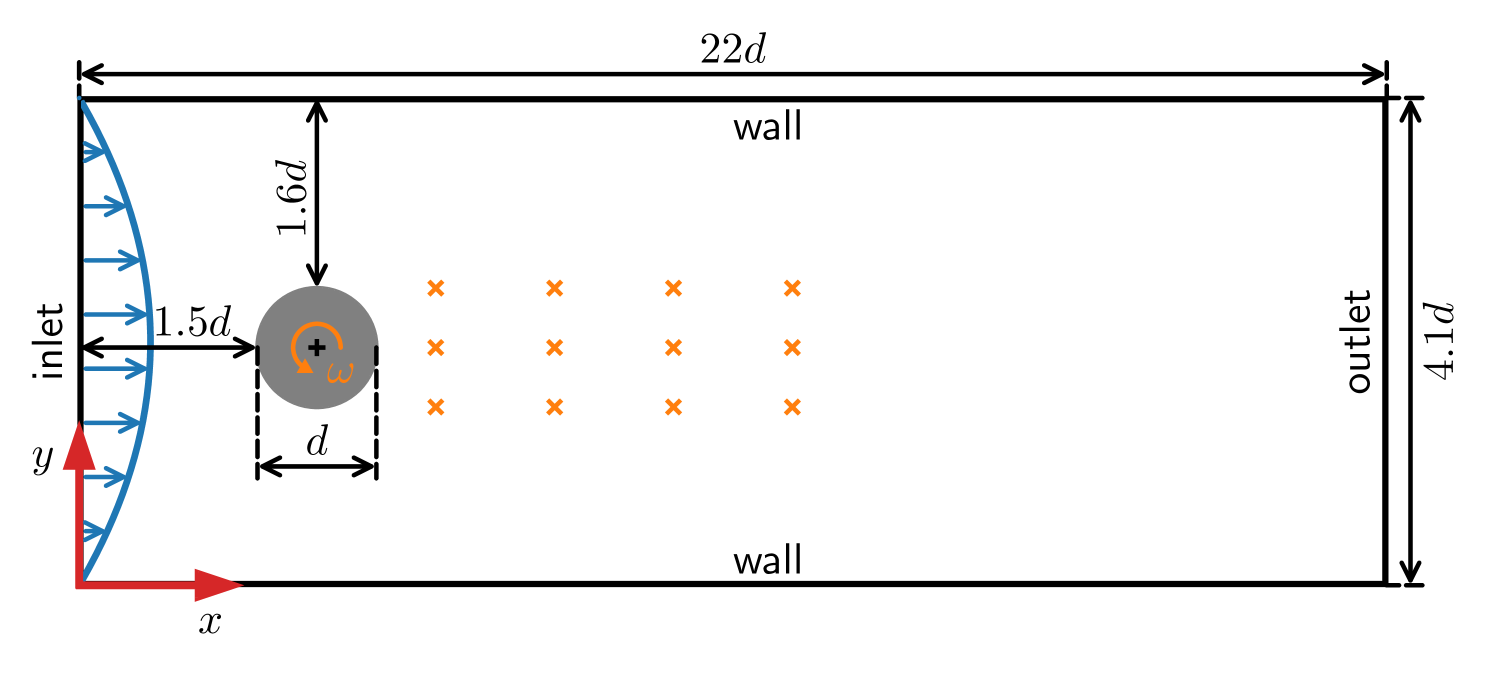
0
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner, Janis Geise
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
Read more4/11/2024