Multi-Agent Reinforcement Learning from Human Feedback: Data Coverage and Algorithmic Techniques

0

Sign in to get full access
Overview
- This research paper explores techniques for multi-agent reinforcement learning from human feedback.
- It investigates the importance of data coverage and algorithmic techniques in this domain.
- The paper presents novel contributions and technical innovations to advance the state-of-the-art.
Plain English Explanation
The paper focuses on the challenge of training artificial intelligence (AI) systems to learn and improve their behavior through direct feedback from humans. This is known as "reinforcement learning from human feedback."
The researchers look specifically at the case of "multi-agent" systems, where multiple AI agents must coordinate and learn together. They examine two key factors that impact the effectiveness of this approach:
-
Data Coverage: Ensuring the AI agents are exposed to a diverse and representative set of human feedback during training, so they can learn general principles rather than just specific scenarios.
-
Algorithmic Techniques: Developing new machine learning algorithms and methods that can efficiently process the human feedback and use it to shape the agents' behavior and decision-making.
The paper introduces novel techniques and insights in both of these areas to advance the state-of-the-art in multi-agent reinforcement learning from human feedback. The goal is to create AI systems that can learn and improve their skills by interacting with and receiving guidance from people, rather than relying solely on pre-programmed rules or data.
Technical Explanation
The paper's key contributions include:
-
Techniques to maximize the diversity and coverage of human feedback data used to train the multi-agent systems. This helps ensure the agents learn general principles rather than just specific scenarios.
-
Novel algorithmic methods for efficiently processing the human feedback signals and using them to shape the agents' behavior and decision-making. This includes innovations in reward modeling, exploration, and multi-agent coordination.
-
Extensive experimental evaluation of the proposed techniques across a range of multi-agent environments and tasks. The results demonstrate significant performance improvements over baseline approaches.
The paper provides a thorough technical description of the data coverage and algorithmic techniques, including mathematical formulations and implementation details. It also includes a comprehensive analysis of the experimental findings, limitations, and potential areas for future work.
Critical Analysis
The paper presents a thoughtful and well-designed approach to the important challenge of multi-agent reinforcement learning from human feedback. The focus on data coverage and algorithmic innovations are particularly noteworthy contributions that help address key limitations in prior work.
However, the paper also acknowledges some limitations of the current techniques, such as the reliance on simulated environments and the potential for human feedback to be noisy or biased. Additionally, the authors suggest several directions for future research, including extending the methods to real-world robotic systems and exploring the use of alternative feedback modalities (e.g., natural language).
Overall, the research represents a significant step forward in the field of multi-agent reinforcement learning from human feedback. The techniques and insights presented in the paper could have important implications for the development of more capable and adaptable AI systems that can learn and improve through direct interaction with people.
Conclusion
This research paper makes important contributions to the field of multi-agent reinforcement learning from human feedback. By focusing on the key challenges of data coverage and algorithmic techniques, the authors have developed novel methods that demonstrate significant performance improvements over prior approaches.
The findings from this work could have far-reaching implications for the development of AI systems that can learn and adapt through direct interaction with humans, rather than relying solely on pre-programmed rules or data. As the authors suggest, there are still many avenues for future research and refinement, but this paper represents an important step forward in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Agent Reinforcement Learning from Human Feedback: Data Coverage and Algorithmic Techniques
Natalia Zhang, Xinqi Wang, Qiwen Cui, Runlong Zhou, Sham M. Kakade, Simon S. Du
We initiate the study of Multi-Agent Reinforcement Learning from Human Feedback (MARLHF), exploring both theoretical foundations and empirical validations. We define the task as identifying Nash equilibrium from a preference-only offline dataset in general-sum games, a problem marked by the challenge of sparse feedback signals. Our theory establishes the upper complexity bounds for Nash Equilibrium in effective MARLHF, demonstrating that single-policy coverage is inadequate and highlighting the importance of unilateral dataset coverage. These theoretical insights are verified through comprehensive experiments. To enhance the practical performance, we further introduce two algorithmic techniques. (1) We propose a Mean Squared Error (MSE) regularization along the time axis to achieve a more uniform reward distribution and improve reward learning outcomes. (2) We utilize imitation learning to approximate the reference policy, ensuring stability and effectiveness in training. Our findings underscore the multifaceted approach required for MARLHF, paving the way for effective preference-based multi-agent systems.
Read more9/5/2024
🏅
0
Multi-turn Reinforcement Learning from Preference Human Feedback
Lior Shani, Aviv Rosenberg, Asaf Cassel, Oran Lang, Daniele Calandriello, Avital Zipori, Hila Noga, Orgad Keller, Bilal Piot, Idan Szpektor, Avinatan Hassidim, Yossi Matias, R'emi Munos
Reinforcement Learning from Human Feedback (RLHF) has become the standard approach for aligning Large Language Models (LLMs) with human preferences, allowing LLMs to demonstrate remarkable abilities in various tasks. Existing methods work by emulating the preferences at the single decision (turn) level, limiting their capabilities in settings that require planning or multi-turn interactions to achieve a long-term goal. In this paper, we address this issue by developing novel methods for Reinforcement Learning (RL) from preference feedback between two full multi-turn conversations. In the tabular setting, we present a novel mirror-descent-based policy optimization algorithm for the general multi-turn preference-based RL problem, and prove its convergence to Nash equilibrium. To evaluate performance, we create a new environment, Education Dialogue, where a teacher agent guides a student in learning a random topic, and show that a deep RL variant of our algorithm outperforms RLHF baselines. Finally, we show that in an environment with explicit rewards, our algorithm recovers the same performance as a reward-based RL baseline, despite relying solely on a weaker preference signal.
Read more5/24/2024

0
Nash Learning from Human Feedback
R'emi Munos, Michal Valko, Daniele Calandriello, Mohammad Gheshlaghi Azar, Mark Rowland, Zhaohan Daniel Guo, Yunhao Tang, Matthieu Geist, Thomas Mesnard, Andrea Michi, Marco Selvi, Sertan Girgin, Nikola Momchev, Olivier Bachem, Daniel J. Mankowitz, Doina Precup, Bilal Piot
Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.
Read more6/12/2024
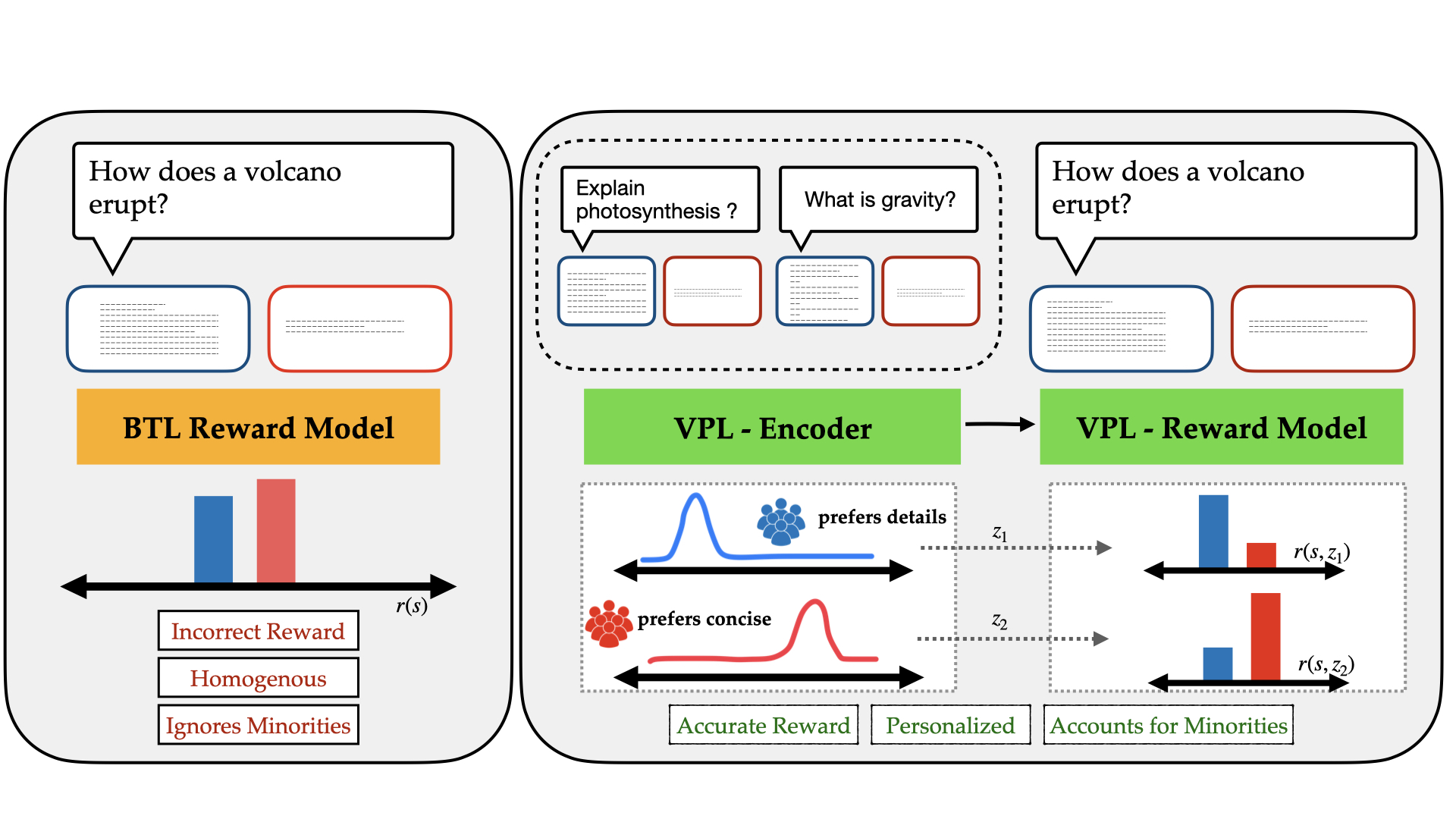
0
Personalizing Reinforcement Learning from Human Feedback with Variational Preference Learning
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, Natasha Jaques
Reinforcement Learning from Human Feedback (RLHF) is a powerful paradigm for aligning foundation models to human values and preferences. However, current RLHF techniques cannot account for the naturally occurring differences in individual human preferences across a diverse population. When these differences arise, traditional RLHF frameworks simply average over them, leading to inaccurate rewards and poor performance for individual subgroups. To address the need for pluralistic alignment, we develop a class of multimodal RLHF methods. Our proposed techniques are based on a latent variable formulation - inferring a novel user-specific latent and learning reward models and policies conditioned on this latent without additional user-specific data. While conceptually simple, we show that in practice, this reward modeling requires careful algorithmic considerations around model architecture and reward scaling. To empirically validate our proposed technique, we first show that it can provide a way to combat underspecification in simulated control problems, inferring and optimizing user-specific reward functions. Next, we conduct experiments on pluralistic language datasets representing diverse user preferences and demonstrate improved reward function accuracy. We additionally show the benefits of this probabilistic framework in terms of measuring uncertainty, and actively learning user preferences. This work enables learning from diverse populations of users with divergent preferences, an important challenge that naturally occurs in problems from robot learning to foundation model alignment.
Read more8/20/2024