Multi-Convformer: Extending Conformer with Multiple Convolution Kernels

0

Sign in to get full access
Overview
- Introduces Multi-Convformer, an extension of the Conformer model with multiple convolution kernels
- Aims to improve the performance and efficiency of the Conformer model for speech recognition and other tasks
- Proposes leveraging multiple convolution kernels to capture diverse contextual information
Plain English Explanation
The paper introduces Multi-Convformer, a new model that builds upon the existing Conformer architecture. The Conformer model is a powerful tool for speech recognition and other language-related tasks, but the authors believe it can be improved further.
The key idea behind Multi-Convformer is to use multiple convolution kernels instead of a single kernel in the Conformer model. Convolution kernels are a way of extracting local contextual information from the input data. By using multiple kernels, the model can capture a wider range of contextual information, potentially leading to better performance.
The authors hypothesize that this approach will allow the model to better understand the nuances and complexities of speech, leading to improved accuracy in speech recognition tasks. Additionally, the use of multiple kernels may make the model more efficient, as it can potentially learn more with fewer parameters.
Technical Explanation
The Multi-Convformer model is an extension of the Conformer architecture, which combines self-attention and convolution layers to capture both global and local dependencies in the input data.
In the original Conformer, a single convolution layer is used to extract local contextual information. The Multi-Convformer model introduces multiple convolution kernels in this layer, allowing the model to capture a wider range of contextual features. Specifically, the convolution layer in Multi-Convformer consists of several sub-layers, each with a different convolution kernel size. The outputs of these sub-layers are then concatenated and passed through a linear layer to produce the final convolution output.
By using multiple convolution kernels, the model can extract diverse local features from the input, potentially leading to improved performance on speech recognition and other language-related tasks. The authors hypothesize that this approach will allow the model to better understand the complexities of speech, as different kernel sizes may be better suited to capturing different aspects of the input.
Additionally, the use of multiple kernels may make the model more efficient, as it can potentially learn more with fewer parameters compared to stacking multiple single-kernel convolution layers.
Critical Analysis
The authors provide a well-designed and thorough evaluation of the Multi-Convformer model, comparing its performance to the original Conformer as well as other state-of-the-art models on several speech recognition benchmarks.
One potential limitation of the research, as acknowledged by the authors, is that the optimal number and sizes of convolution kernels may need to be tuned for specific tasks or datasets. The paper does not explore this in depth, and further investigation may be needed to determine the best configuration for a given problem.
Additionally, while the authors demonstrate the effectiveness of Multi-Convformer on speech recognition tasks, it would be interesting to see how the model performs on other language-related tasks, such as machine translation or text classification. Expanding the evaluation to a broader range of applications could provide further insights into the model's capabilities and limitations.
Conclusion
The Multi-Convformer model proposed in this paper represents an interesting and promising extension of the Conformer architecture. By leveraging multiple convolution kernels, the model can capture a wider range of contextual features, potentially leading to improved performance on speech recognition and other language-related tasks.
The authors have provided a thorough evaluation of the model, demonstrating its effectiveness on several speech recognition benchmarks. While some areas for further research have been identified, the Multi-Convformer model stands as a valuable contribution to the ongoing development of efficient and high-performing models for speech and language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Convformer: Extending Conformer with Multiple Convolution Kernels
Darshan Prabhu, Yifan Peng, Preethi Jyothi, Shinji Watanabe
Convolutions have become essential in state-of-the-art end-to-end Automatic Speech Recognition~(ASR) systems due to their efficient modelling of local context. Notably, its use in Conformers has led to superior performance compared to vanilla Transformer-based ASR systems. While components other than the convolution module in the Conformer have been reexamined, altering the convolution module itself has been far less explored. Towards this, we introduce Multi-Convformer that uses multiple convolution kernels within the convolution module of the Conformer in conjunction with gating. This helps in improved modeling of local dependencies at varying granularities. Our model rivals existing Conformer variants such as CgMLP and E-Branchformer in performance, while being more parameter efficient. We empirically compare our approach with Conformer and its variants across four different datasets and three different modelling paradigms and show up to 8% relative word error rate~(WER) improvements.
Read more7/25/2024
🗣️
1
Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
Mingbin Xu, Alex Jin, Sicheng Wang, Mu Su, Tim Ng, Henry Mason, Shiyi Han, Zhihong Lei, Yaqiao Deng, Zhen Huang, Mahesh Krishnamoorthy
With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other smart home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on smart wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
Read more5/15/2024

0
Continuous Sign Language Recognition with Adapted Conformer via Unsupervised Pretraining
Neena Aloysius, Geetha M, Prema Nedungadi
Conventional Deep Learning frameworks for continuous sign language recognition (CSLR) are comprised of a single or multi-modal feature extractor, a sequence-learning module, and a decoder for outputting the glosses. The sequence learning module is a crucial part wherein transformers have demonstrated their efficacy in the sequence-to-sequence tasks. Analyzing the research progress in the field of Natural Language Processing and Speech Recognition, a rapid introduction of various transformer variants is observed. However, in the realm of sign language, experimentation in the sequence learning component is limited. In this work, the state-of-the-art Conformer model for Speech Recognition is adapted for CSLR and the proposed model is termed ConSignformer. This marks the first instance of employing Conformer for a vision-based task. ConSignformer has bimodal pipeline of CNN as feature extractor and Conformer for sequence learning. For improved context learning we also introduce Cross-Modal Relative Attention (CMRA). By incorporating CMRA into the model, it becomes more adept at learning and utilizing complex relationships within the data. To further enhance the Conformer model, unsupervised pretraining called Regressional Feature Extraction is conducted on a curated sign language dataset. The pretrained Conformer is then fine-tuned for the downstream recognition task. The experimental results confirm the effectiveness of the adopted pretraining strategy and demonstrate how CMRA contributes to the recognition process. Remarkably, leveraging a Conformer-based backbone, our model achieves state-of-the-art performance on the benchmark datasets: PHOENIX-2014 and PHOENIX-2014T.
Read more5/21/2024
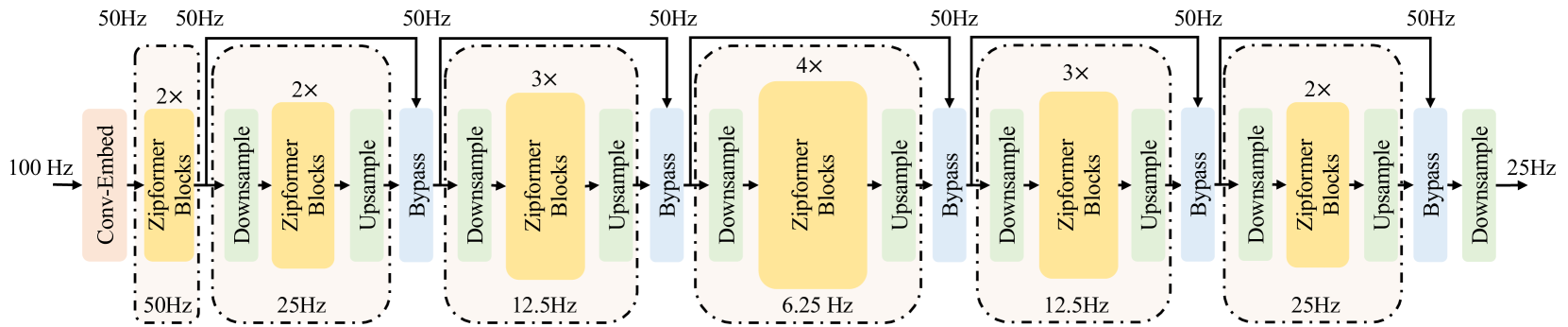
0
Zipformer: A faster and better encoder for automatic speech recognition
Zengwei Yao, Liyong Guo, Xiaoyu Yang, Wei Kang, Fangjun Kuang, Yifan Yang, Zengrui Jin, Long Lin, Daniel Povey
The Conformer has become the most popular encoder model for automatic speech recognition (ASR). It adds convolution modules to a transformer to learn both local and global dependencies. In this work we describe a faster, more memory-efficient, and better-performing transformer, called Zipformer. Modeling changes include: 1) a U-Net-like encoder structure where middle stacks operate at lower frame rates; 2) reorganized block structure with more modules, within which we re-use attention weights for efficiency; 3) a modified form of LayerNorm called BiasNorm allows us to retain some length information; 4) new activation functions SwooshR and SwooshL work better than Swish. We also propose a new optimizer, called ScaledAdam, which scales the update by each tensor's current scale to keep the relative change about the same, and also explictly learns the parameter scale. It achieves faster convergence and better performance than Adam. Extensive experiments on LibriSpeech, Aishell-1, and WenetSpeech datasets demonstrate the effectiveness of our proposed Zipformer over other state-of-the-art ASR models. Our code is publicly available at https://github.com/k2-fsa/icefall.
Read more4/11/2024