Multi-layer Learnable Attention Mask for Multimodal Tasks
2406.02761
0
0

Abstract
While the Self-Attention mechanism in the Transformer model has proven to be effective in many domains, we observe that it is less effective in more diverse settings (e.g. multimodality) due to the varying granularity of each token and the high computational demands of lengthy sequences. To address the challenges, we introduce the Learnable Attention Mask (LAM), strategically designed to globally regulate attention maps and prioritize critical tokens within the sequence. Leveraging the Self-Attention module in a BERT-like transformer network, our approach adeptly captures associations between tokens. The extension of the LAM to a multi-layer version accommodates the varied information aspects embedded at each layer of the Transformer network. Comprehensive experimental validation on various datasets, such as MADv2, QVHighlights, ImageNet 1K, and MSRVTT, demonstrates the efficacy of the LAM, exemplifying its ability to enhance model performance while mitigating redundant computations. This pioneering approach presents a significant advancement in enhancing the understanding of complex scenarios, such as in movie understanding.
Create account to get full access
Overview
- The paper introduces a multi-layer learnable attention mask for improving the performance of multimodal tasks, such as image-text matching and visual question answering.
- The proposed approach aims to learn attention masks that capture relevant cross-modal interactions, allowing the model to focus on the most informative features for the given task.
- The authors demonstrate the effectiveness of their method on various multimodal benchmarks, outperforming existing attention-based approaches.
Plain English Explanation
The paper presents a new way to help artificial intelligence (AI) models better understand the relationship between images and text. When AI models are trained on tasks that involve both images and text, such as matching images to their descriptions or answering questions about images, they need to learn how the visual and textual information are connected.
The researchers developed a multi-layer learnable attention mask that can help the AI model focus on the most important parts of the image and text for the given task. The attention mask acts like a filter, highlighting the areas that are most relevant and downplaying the less relevant parts.
By learning this attention mask in multiple layers of the model, the researchers found that the AI could better capture the complex relationships between images and text, leading to improved performance on tasks like image-text matching and visual question answering. This approach outperformed other attention-based methods, suggesting that it is a promising technique for enhancing the capabilities of multimodal AI systems.
Technical Explanation
The paper introduces a multi-layer learnable attention mask for improving the performance of multimodal tasks. The key idea is to learn attention masks that capture relevant cross-modal interactions, allowing the model to focus on the most informative features for the given task.
The authors propose a neural network architecture that consists of a vision transformer and a language model. The attention masks are learned in multiple layers of the network, using a dedicated attention head that is trained to predict the importance of each feature for the task at hand.
The authors evaluate their approach on various multimodal benchmarks, including image-text matching and visual question answering. The results show that the proposed method outperforms existing attention-based approaches, demonstrating the effectiveness of the learnable attention masks for capturing relevant cross-modal interactions.
Critical Analysis
The paper presents a novel and promising approach for enhancing the performance of multimodal AI systems. The use of learnable attention masks is a clever way to guide the model's focus towards the most informative features, which can be particularly useful for tasks that require understanding the complex relationships between images and text.
One potential limitation of the approach is that it relies on the availability of large-scale multimodal datasets for training the attention masks. The performance of the method may be sensitive to the quality and diversity of the training data, which could be a challenge in domains with limited data.
Additionally, the paper does not provide a detailed analysis of the attention patterns learned by the model or the specific types of cross-modal interactions that the attention masks are capturing. Further exploration of these aspects could provide valuable insights into the inner workings of the proposed method and its potential for generalization to other multimodal tasks.
Conclusion
The paper presents a multi-layer learnable attention mask approach that significantly improves the performance of multimodal AI systems on tasks like image-text matching and visual question answering. By learning to focus on the most relevant parts of the input, the model can better capture the complex relationships between visual and textual information.
This work demonstrates the potential of attention-based techniques for enhancing the capabilities of multimodal AI, and suggests that further research in this direction could lead to even more powerful and versatile systems that can seamlessly integrate and understand information from multiple modalities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Adapting LLaMA Decoder to Vision Transformer
Jiahao Wang, Wenqi Shao, Mengzhao Chen, Chengyue Wu, Yong Liu, Taiqiang Wu, Kaipeng Zhang, Songyang Zhang, Kai Chen, Ping Luo
0
0
This work examines whether decoder-only Transformers such as LLaMA, which were originally designed for large language models (LLMs), can be adapted to the computer vision field. We first LLaMAfy a standard ViT step-by-step to align with LLaMA's architecture, and find that directly applying a causal mask to the self-attention brings an attention collapse issue, resulting in the failure to the network training. We suggest to reposition the class token behind the image tokens with a post-sequence class token technique to overcome this challenge, enabling causal self-attention to efficiently capture the entire image's information. Additionally, we develop a soft mask strategy that gradually introduces a causal mask to the self-attention at the onset of training to facilitate the optimization behavior. The tailored model, dubbed as image LLaMA (iLLaMA), is akin to LLaMA in architecture and enables direct supervised learning. Its causal self-attention boosts computational efficiency and learns complex representation by elevating attention map ranks. iLLaMA rivals the performance with its encoder-only counterparts, achieving 75.1% ImageNet top-1 accuracy with only 5.7M parameters. Scaling the model to $sim$310M and pre-training on ImageNet-21K further enhances the accuracy to 86.0%. Extensive experiments demonstrate iLLaMA's reliable properties: shape-texture bias, calibration, quantization compatibility, ADE20K segmentation and CIFAR transfer learning. We hope our study can kindle fresh views to visual architectures in the wave of LLMs and inspire the development of unified multimodal models. Pre-trained models and codes are available https://github.com/techmonsterwang/iLLaMA.
5/28/2024
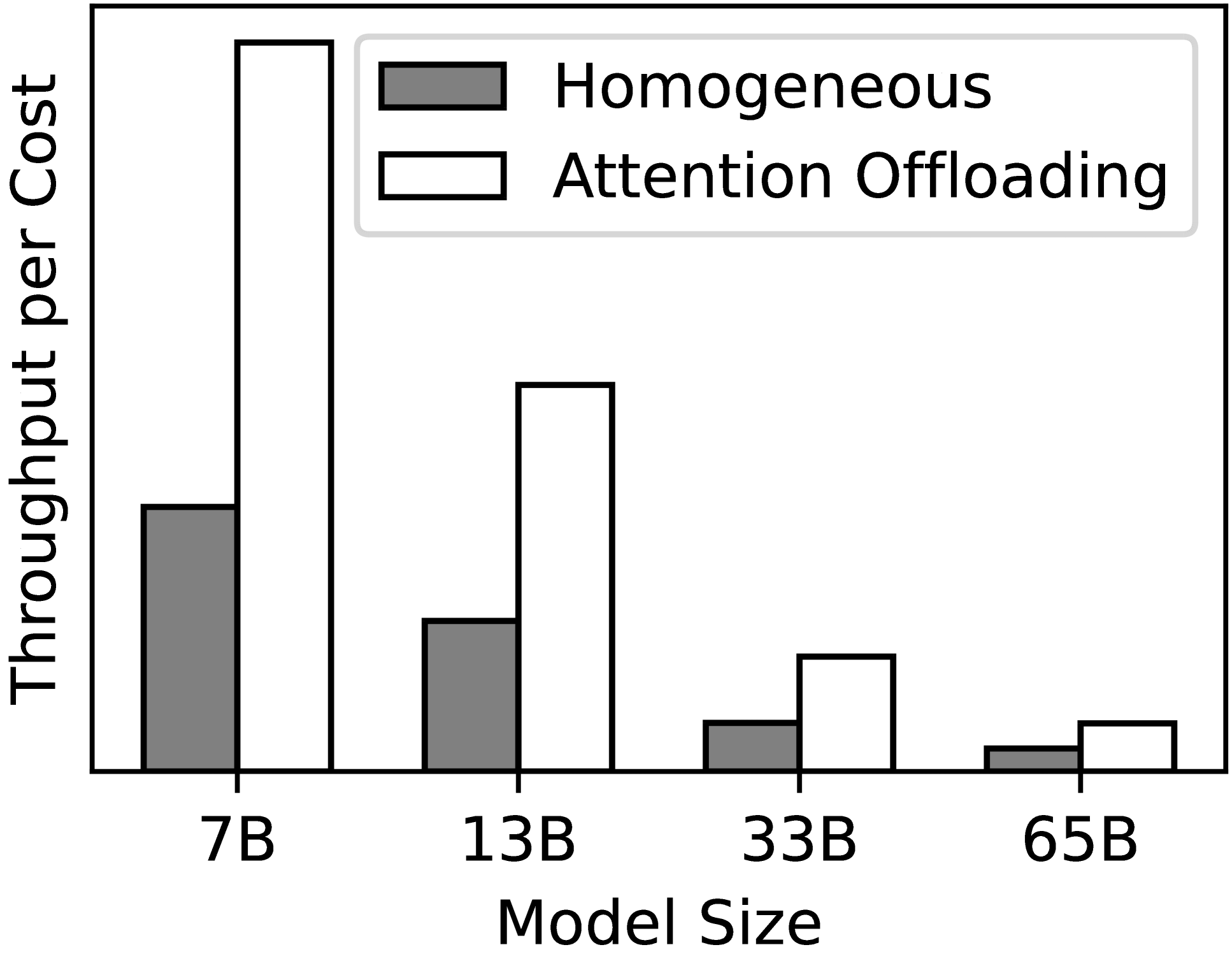
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024
👀
How Transformers Learn Diverse Attention Correlations in Masked Vision Pretraining
Yu Huang, Zixin Wen, Yuejie Chi, Yingbin Liang
0
0
Masked reconstruction, which predicts randomly masked patches from unmasked ones, has emerged as an important approach in self-supervised pretraining. However, the theoretical understanding of masked pretraining is rather limited, especially for the foundational architecture of transformers. In this paper, to the best of our knowledge, we provide the first end-to-end theoretical guarantee of learning one-layer transformers in masked reconstruction self-supervised pretraining. On the conceptual side, we posit a mechanism of how transformers trained with masked vision pretraining objectives produce empirically observed local and diverse attention patterns, on data distributions with spatial structures that highlight feature-position correlations. On the technical side, our end-to-end characterization of training dynamics in softmax-attention models simultaneously accounts for input and position embeddings, which is developed based on a careful analysis tracking the interplay between feature-wise and position-wise attention correlations.
6/6/2024

What Matters in Transformers? Not All Attention is Needed
Shwai He, Guoheng Sun, Zheyu Shen, Ang Li
0
0
Scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks. However, this scaling also introduces redundant structures, posing challenges for real-world deployment. Despite some recognition of redundancy in LLMs, the variability of redundancy across different structures, such as MLP and Attention layers, is under-explored. In this work, we investigate the varying redundancy across different modules within Transformers, including Blocks, MLP, and Attention layers, using a similarity-based metric. This metric operates on the premise that redundant structures produce outputs highly similar to their inputs. Surprisingly, while attention layers are essential for transformers and distinguish them from other mainstream architectures, we found that a large proportion of attention layers exhibit excessively high similarity and can be safely pruned without degrading performance, leading to reduced memory and computation costs. Additionally, we further propose a method that jointly drops Attention and MLP layers, achieving improved performance and dropping ratios. Extensive experiments demonstrate the effectiveness of our methods, e.g., Llama-3-70B maintains comparable performance even after pruning half of the attention layers. Our findings provide valuable insights for future network architecture design. The code will be released at: url{https://github.com/Shwai-He/LLM-Drop}.
6/26/2024