Multi-robot maze exploration using an efficient cost-utility method

0

Sign in to get full access
Overview
- Explores multi-robot maze exploration using an efficient cost-utility method
- Proposes a novel algorithm that combines the wavefront, nearest-frontier, and potential fields approaches
- Evaluates the algorithm's performance through simulation experiments
Plain English Explanation
The paper describes a method for multiple robots to explore a maze efficiently. The key idea is to combine three existing techniques - wavefront, nearest-frontier, and potential fields - in a novel way to guide the robots.
The algorithm works by having each robot maintain a map of the explored area and plan its path to the nearest unexplored frontier, while also considering the potential fields of other robots to avoid collisions. This approach aims to balance exploration efficiency, coordination, and obstacle avoidance.
The researchers tested their algorithm through computer simulations and found that it outperformed alternative approaches in terms of exploration time and coverage of the maze. This suggests the method could be useful for real-world applications involving multiple robots exploring unknown environments.
Technical Explanation
The paper presents a novel algorithm for multi-robot maze exploration that combines the wavefront, nearest-frontier, and potential fields approaches. The key components of the algorithm are:
-
Wavefront Exploration: Each robot maintains a wavefront map of the explored area, which is used to plan paths to the nearest unexplored frontier.
-
Nearest-Frontier Selection: Robots select the nearest unexplored frontier as their next exploration target, aiming to efficiently cover the entire maze.
-
Potential Fields: Robots repel each other using potential fields to avoid collisions and ensure coordinated exploration.
The researchers evaluated their algorithm through simulation experiments, comparing its performance to alternative approaches like hierarchical path planning and frontier-based exploration. The results showed that their proposed method outperformed the alternatives in terms of exploration time and coverage of the maze environment.
Critical Analysis
The paper makes a solid contribution to the field of multi-robot exploration by presenting an effective algorithm that combines several well-established techniques. The authors have carefully designed the algorithm and conducted thorough simulation experiments to validate its performance.
However, the paper does not address several potential limitations and areas for further research. For example, the algorithm assumes perfect communication and sensor capabilities among the robots, which may not be the case in real-world scenarios. Additionally, the evaluation is limited to simulated environments, and the algorithm's performance in physical robot experiments is not explored.
Further research could investigate the algorithm's robustness to communication failures, sensor noise, and other real-world challenges. Extending the evaluation to include physical robot experiments would also help validate the algorithm's practical applicability.
Conclusion
This paper introduces an efficient cost-utility method for multi-robot maze exploration, which combines the wavefront, nearest-frontier, and potential fields approaches. The proposed algorithm outperforms alternative techniques in simulation experiments, suggesting it could be a promising solution for real-world applications involving multiple robots exploring unknown environments. Further research is needed to address the algorithm's limitations and validate its performance in physical robot experiments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-robot maze exploration using an efficient cost-utility method
Manousos Linardakis, Iraklis Varlamis, Georgios Th. Papadopoulos
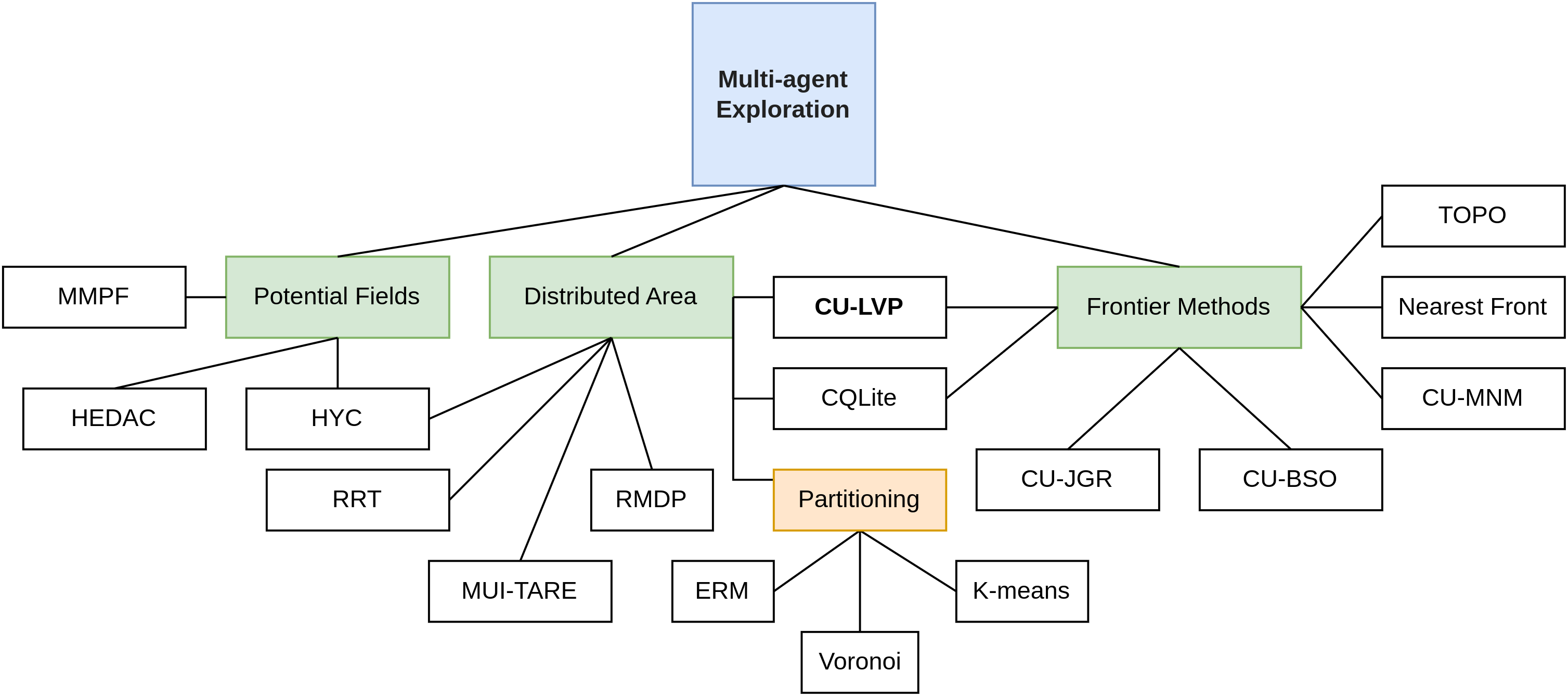
In the field of modern robotics, robots are proving to be useful in tackling high-risk situations, such as navigating hazardous environments like burning buildings, earthquake-stricken areas, or patrolling crime-ridden streets, as well as exploring uncharted caves. These scenarios share similarities with maze exploration problems in terms of complexity. While several methods have been proposed for single-agent systems, ranging from potential fields to flood-fill methods, recent research endeavors have focused on creating methods tailored for multiple agents to enhance the quality and efficiency of maze coverage. The contribution of this paper is the implementation of established maze exploration methods and their comparison with a new cost-utility algorithm designed for multiple agents, which combines the existing methodologies to optimize exploration outcomes. Through a comprehensive and comparative analysis, this paper evaluates the performance of the new approach against the implemented baseline methods from the literature, highlighting its efficacy and potential advantages in various scenarios. The code and experimental results supporting this study are available in the following repository (https://github.com/manouslinard/multiagent-exploration/).
Read more7/22/2024
0
Distributed maze exploration using multiple agents and optimal goal assignment
Manousos Linardakis, Iraklis Varlamis, Georgios Th. Papadopoulos
Robotic exploration has long captivated researchers aiming to map complex environments efficiently. Techniques such as potential fields and frontier exploration have traditionally been employed in this pursuit, primarily focusing on solitary agents. Recent advancements have shifted towards optimizing exploration efficiency through multiagent systems. However, many existing approaches overlook critical real-world factors, such as broadcast range limitations, communication costs, and coverage overlap. This paper addresses these gaps by proposing a distributed maze exploration strategy (CU-LVP) that assumes constrained broadcast ranges and utilizes Voronoi diagrams for better area partitioning. By adapting traditional multiagent methods to distributed environments with limited broadcast ranges, this study evaluates their performance across diverse maze topologies, demonstrating the efficacy and practical applicability of the proposed method. The code and experimental results supporting this study are available in the following repository: https://github.com/manouslinard/multiagent-exploration/.
Read more5/31/2024

0
Hierarchical Large Scale Multirobot Path (Re)Planning
Lishuo Pan, Kevin Hsu, Nora Ayanian
We consider a large-scale multi-robot path planning problem in a cluttered environment. Our approach achieves real-time replanning by dividing the workspace into cells and utilizing a hierarchical planner. Specifically, we propose novel multi-commodity flow-based high-level planners that route robots through cells with reduced congestion, along with an anytime low-level planner that computes collision-free paths for robots within each cell in parallel. A highlight of our method is a significant improvement in computation time. Specifically, we show empirical results of a 500-times speedup in computation time compared to the baseline multi-agent pathfinding approach on the environments we study. We account for the robot's embodiment and support non-stop execution with continuous replanning. We demonstrate the real-time performance of our algorithm with up to 142 robots in simulation, and a representative 32 physical Crazyflie nano-quadrotor experiment.
Read more9/25/2024

0
Learning Coordinated Maneuver in Adversarial Environments
Zechen Hu, Manshi Limbu, Daigo Shishika, Xuesu Xiao, Xuan Wang
This paper aims to solve the coordination of a team of robots traversing a route in the presence of adversaries with random positions. Our goal is to minimize the overall cost of the team, which is determined by (i) the accumulated risk when robots stay in adversary-impacted zones and (ii) the mission completion time. During traversal, robots can reduce their speed and act as a `guard' (the slower, the better), which will decrease the risks certain adversary incurs. This leads to a trade-off between the robots' guarding behaviors and their travel speeds. The formulated problem is highly non-convex and cannot be efficiently solved by existing algorithms. Our approach includes a theoretical analysis of the robots' behaviors for the single-adversary case. As the scale of the problem expands, solving the optimal solution using optimization approaches is challenging, therefore, we employ reinforcement learning techniques by developing new encoding and policy-generating methods. Simulations demonstrate that our learning methods can efficiently produce team coordination behaviors. We discuss the reasoning behind these behaviors and explain why they reduce the overall team cost.
Read more8/22/2024