Unveiling Visual Biases in Audio-Visual Localization Benchmarks

0

Sign in to get full access
Overview
- The paper examines visual biases in audio-visual localization benchmarks.
- It investigates how visual cues can influence the performance of audio-visual localization models.
- The research aims to unveil and mitigate these biases to improve the reliability of audio-visual localization systems.
Plain English Explanation
The paper looks at how visual information can affect the performance of models that try to locate the source of a sound using both audio and visual data. These audio-visual localization models are often used in applications like virtual assistants, robots, and self-driving cars.
The researchers found that the visual cues in the training data can lead the models to rely too heavily on the visual information, even when the audio information would be more reliable for locating the sound source. This "visual bias" can make the models perform poorly in real-world situations where the visual and audio information don't always match up.
To address this issue, the researchers propose methods to reduce the visual bias and make the models more robust to real-world audio-visual mismatches. By understanding and mitigating these biases, the goal is to improve the reliability and effectiveness of audio-visual localization systems.
Technical Explanation
The paper focuses on audio-visual localization, which involves using both audio and visual information to determine the location of a sound source. The researchers analyze several popular audio-visual localization benchmarks and find that the models trained on these datasets exhibit significant visual biases.
Through a series of experiments, the researchers demonstrate that the visual cues in the training data can lead the models to overly rely on the visual information, even when the audio information would be more reliable for accurately locating the sound source. This visual bias can cause the models to perform poorly in real-world situations where the audio and visual inputs do not align.
To mitigate these biases, the paper proposes several techniques, such as adversarial training and cross-modal alignment. These methods aim to reduce the model's dependence on visual cues and improve its ability to integrate audio and visual information effectively.
The researchers also introduce a new benchmark designed to better evaluate the true audio-visual localization capabilities of models by explicitly controlling for visual biases.
Critical Analysis
The paper raises important concerns about the visual biases present in current audio-visual localization benchmarks and models. The findings highlight the need for more robust and reliable audio-visual perception systems, especially for applications like virtual assistants, robots, and autonomous vehicles.
While the proposed techniques for mitigating visual biases are promising, the authors acknowledge that further research is needed to fully address the problem. Additional factors, such as the quality and diversity of the training data, may also contribute to the visual bias and should be explored.
Furthermore, the paper focuses on static audio-visual localization tasks, and it would be valuable to investigate how these biases manifest in more dynamic, real-world scenarios where the sound source and the observer are both moving.
Conclusion
This paper sheds light on a critical issue in the development of audio-visual localization systems: the presence of visual biases that can undermine the models' ability to accurately locate sound sources. By unveiling these biases and proposing mitigation strategies, the researchers aim to pave the way for more robust and reliable audio-visual perception capabilities, which are essential for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling Visual Biases in Audio-Visual Localization Benchmarks
Liangyu Chen, Zihao Yue, Boshen Xu, Qin Jin
Audio-Visual Source Localization (AVSL) aims to localize the source of sound within a video. In this paper, we identify a significant issue in existing benchmarks: the sounding objects are often easily recognized based solely on visual cues, which we refer to as visual bias. Such biases hinder these benchmarks from effectively evaluating AVSL models. To further validate our hypothesis regarding visual biases, we examine two representative AVSL benchmarks, VGG-SS and EpicSounding-Object, where the vision-only models outperform all audiovisual baselines. Our findings suggest that existing AVSL benchmarks need further refinement to facilitate audio-visual learning.
Read more9/12/2024
0
Unveiling and Mitigating Bias in Audio Visual Segmentation
Peiwen Sun, Honggang Zhang, Di Hu
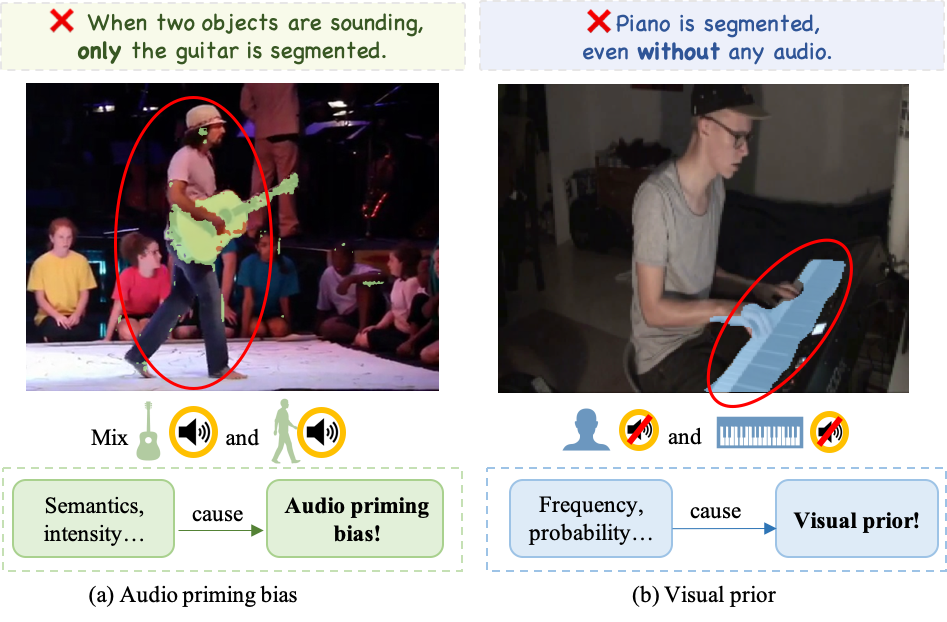
Community researchers have developed a range of advanced audio-visual segmentation models aimed at improving the quality of sounding objects' masks. While masks created by these models may initially appear plausible, they occasionally exhibit anomalies with incorrect grounding logic. We attribute this to real-world inherent preferences and distributions as a simpler signal for learning than the complex audio-visual grounding, which leads to the disregard of important modality information. Generally, the anomalous phenomena are often complex and cannot be directly observed systematically. In this study, we made a pioneering effort with the proper synthetic data to categorize and analyze phenomena as two types audio priming bias and visual prior according to the source of anomalies. For audio priming bias, to enhance audio sensitivity to different intensities and semantics, a perception module specifically for audio perceives the latent semantic information and incorporates information into a limited set of queries, namely active queries. Moreover, the interaction mechanism related to such active queries in the transformer decoder is customized to adapt to the need for interaction regulating among audio semantics. For visual prior, multiple contrastive training strategies are explored to optimize the model by incorporating a biased branch, without even changing the structure of the model. During experiments, observation demonstrates the presence and the impact that has been produced by the biases of the existing model. Finally, through experimental evaluation of AVS benchmarks, we demonstrate the effectiveness of our methods in handling both types of biases, achieving competitive performance across all three subsets.
Read more7/24/2024

0
Aligning Sight and Sound: Advanced Sound Source Localization Through Audio-Visual Alignment
Arda Senocak, Hyeonggon Ryu, Junsik Kim, Tae-Hyun Oh, Hanspeter Pfister, Joon Son Chung
Recent studies on learning-based sound source localization have mainly focused on the localization performance perspective. However, prior work and existing benchmarks overlook a crucial aspect: cross-modal interaction, which is essential for interactive sound source localization. Cross-modal interaction is vital for understanding semantically matched or mismatched audio-visual events, such as silent objects or off-screen sounds. In this paper, we first comprehensively examine the cross-modal interaction of existing methods, benchmarks, evaluation metrics, and cross-modal understanding tasks. Then, we identify the limitations of previous studies and make several contributions to overcome the limitations. First, we introduce a new synthetic benchmark for interactive sound source localization. Second, we introduce new evaluation metrics to rigorously assess sound source localization methods, focusing on accurately evaluating both localization performance and cross-modal interaction ability. Third, we propose a learning framework with a cross-modal alignment strategy to enhance cross-modal interaction. Lastly, we evaluate both interactive sound source localization and auxiliary cross-modal retrieval tasks together to thoroughly assess cross-modal interaction capabilities and benchmark competing methods. Our new benchmarks and evaluation metrics reveal previously overlooked issues in sound source localization studies. Our proposed novel method, with enhanced cross-modal alignment, shows superior sound source localization performance. This work provides the most comprehensive analysis of sound source localization to date, with extensive validation of competing methods on both existing and new benchmarks using new and standard evaluation metrics.
Read more7/19/2024
0
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
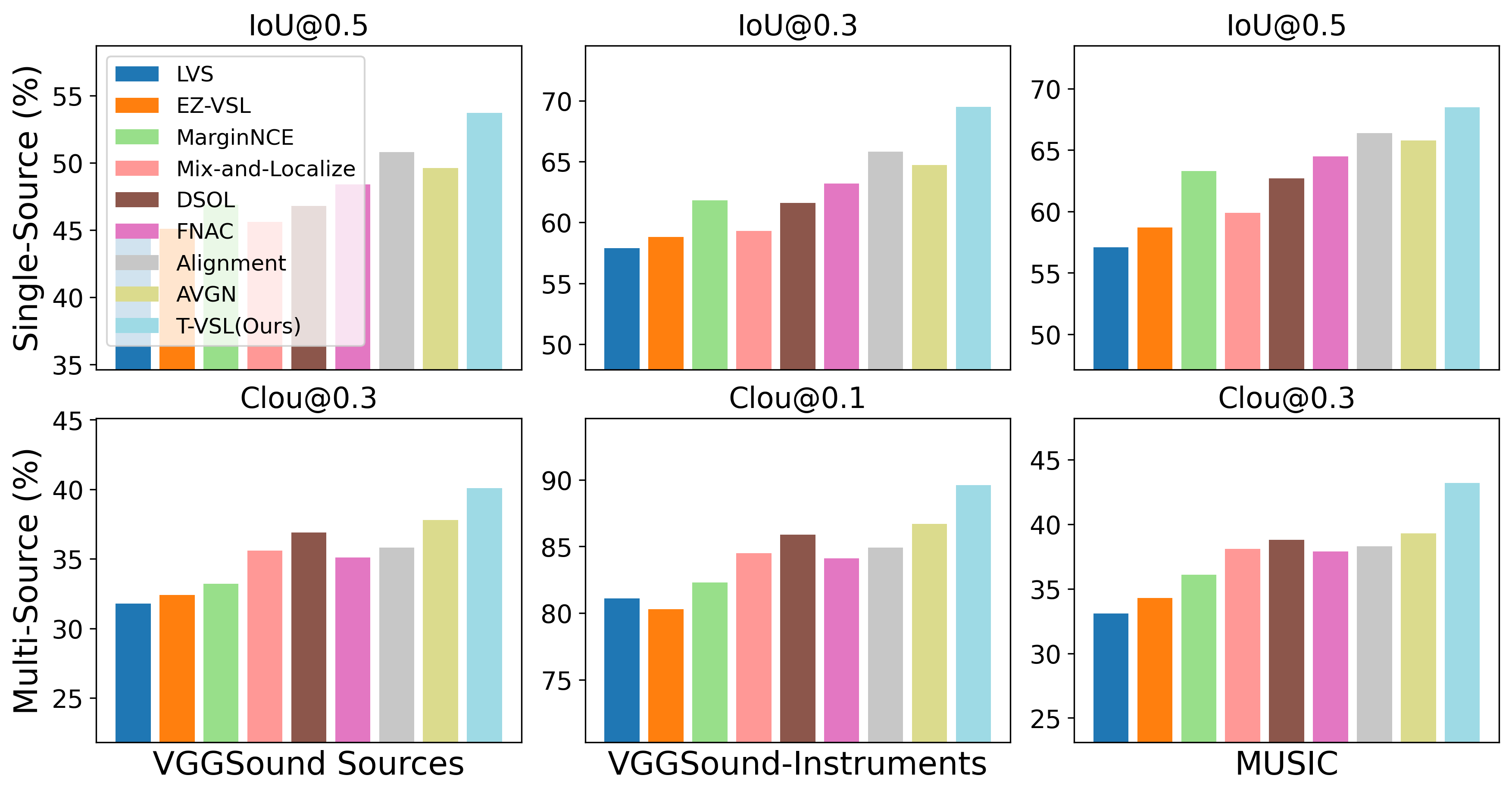
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods. Code is released at https://github.com/enyac-group/T-VSL/tree/main
Read more7/9/2024