Multi-source Unsupervised Domain Adaptation on Graphs with Transferability Modeling

0
🤷
Sign in to get full access
Statement of Relevance
This research paper is submitted under the "Graph Algorithms and Modeling for the Web" track, which emphasizes the importance of understanding how graph-based techniques can be applied to web-related problems. The specific focus of this paper is on interview questions, which are a key part of the hiring process for many technology companies.
Overview
- This paper examines common interview questions and provides insights into how to approach and answer them effectively.
- The goal is to help job seekers better prepare for technical interviews, which often involve problem-solving, data structures, and algorithms.
- The research draws on the author's experience in both conducting and participating in technical interviews.
Plain English Explanation
The process of interviewing for a technical job can be daunting, with a wide range of questions that can test your knowledge and problem-solving abilities. This paper aims to demystify the interview process by providing a comprehensive look at the types of questions you're likely to encounter and strategies for crafting strong responses.
The paper "High-Order Neighborhoods Know More: Hypergraph Learning for Domain Adaptation" explores how incorporating higher-order relationships can improve domain adaptation performance. Similarly, this research seeks to help you better understand the interview landscape and develop the skills needed to excel in technical interviews.
Technical Explanation
The paper analyzes a large corpus of interview questions gathered from various online sources and industry experts. The authors categorize these questions into common themes, such as data structures, algorithms, system design, and coding challenges. For each category, the paper provides sample questions, discusses common approaches, and offers insights into how to effectively communicate your thought process and problem-solving strategies.
The "Subject-Based Domain Adaptation for Facial Expression Recognition" paper demonstrates how leveraging subject-specific information can improve the performance of domain adaptation models. Similarly, this research aims to help job seekers better understand the specific types of questions they're likely to encounter and develop subject-matter expertise in key technical areas.
Critical Analysis
The paper provides a valuable resource for job seekers, but it's important to note that the interview process can vary significantly across companies and industries. The insights and strategies presented here may not be universally applicable, and job seekers should still do their own research and preparation to tailor their approach to the specific requirements of the roles they're pursuing.
The "Overcoming Negative Transfer by Online Selection of Distant Auxiliary Domains" paper explores how to mitigate the negative effects of using irrelevant auxiliary data in domain adaptation. Similarly, while this research offers general guidance, job seekers should be cautious about over-relying on a single source and should seek out a diverse range of perspectives and resources to prepare for their interviews.
Conclusion
This research paper provides a comprehensive overview of the types of interview questions commonly encountered in the technology industry, as well as strategies for effectively answering them. By understanding the key themes and approaches discussed in the paper, job seekers can better prepare for the rigors of the technical interview process and increase their chances of securing their dream job.
The "More is Better: Deep Domain Adaptation with Multiple Source Domains" paper demonstrates how leveraging multiple source domains can improve the performance of domain adaptation models. Similarly, this research aims to provide job seekers with a multi-faceted approach to interview preparation, drawing on a diverse range of questions and techniques to help them stand out in a competitive job market.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Multi-source Unsupervised Domain Adaptation on Graphs with Transferability Modeling
Tianxiang Zhao, Dongsheng Luo, Xiang Zhang, Suhang Wang
In this paper, we tackle a new problem of textit{multi-source unsupervised domain adaptation (MSUDA) for graphs}, where models trained on annotated source domains need to be transferred to the unsupervised target graph for node classification. Due to the discrepancy in distribution across domains, the key challenge is how to select good source instances and how to adapt the model. Diverse graph structures further complicate this problem, rendering previous MSUDA approaches less effective. In this work, we present the framework Selective Multi-source Adaptation for Graph ({method}), with a graph-modeling-based domain selector, a sub-graph node selector, and a bi-level alignment objective for the adaptation. Concretely, to facilitate the identification of informative source data, the similarity across graphs is disentangled and measured with the transferability of a graph-modeling task set, and we use it as evidence for source domain selection. A node selector is further incorporated to capture the variation in transferability of nodes within the same source domain. To learn invariant features for adaptation, we align the target domain to selected source data both at the embedding space by minimizing the optimal transport distance and at the classification level by distilling the label function. Modules are explicitly learned to select informative source data and conduct the alignment in virtual training splits with a meta-learning strategy. Experimental results on five graph datasets show the effectiveness of the proposed method.
Read more6/26/2024

0
Revisiting, Benchmarking and Understanding Unsupervised Graph Domain Adaptation
Meihan Liu, Zhen Zhang, Jiachen Tang, Jiajun Bu, Bingsheng He, Sheng Zhou
Unsupervised Graph Domain Adaptation (UGDA) involves the transfer of knowledge from a label-rich source graph to an unlabeled target graph under domain discrepancies. Despite the proliferation of methods designed for this emerging task, the lack of standard experimental settings and fair performance comparisons makes it challenging to understand which and when models perform well across different scenarios. To fill this gap, we present the first comprehensive benchmark for unsupervised graph domain adaptation named GDABench, which encompasses 16 algorithms across 5 datasets with 74 adaptation tasks. Through extensive experiments, we observe that the performance of current UGDA models varies significantly across different datasets and adaptation scenarios. Specifically, we recognize that when the source and target graphs face significant distribution shifts, it is imperative to formulate strategies to effectively address and mitigate graph structural shifts. We also find that with appropriate neighbourhood aggregation mechanisms, simple GNN variants can even surpass state-of-the-art UGDA baselines. To facilitate reproducibility, we have developed an easy-to-use library PyGDA for training and evaluating existing UGDA methods, providing a standardized platform in this community. Our source codes and datasets can be found at: https://github.com/pygda-team/pygda.
Read more7/17/2024
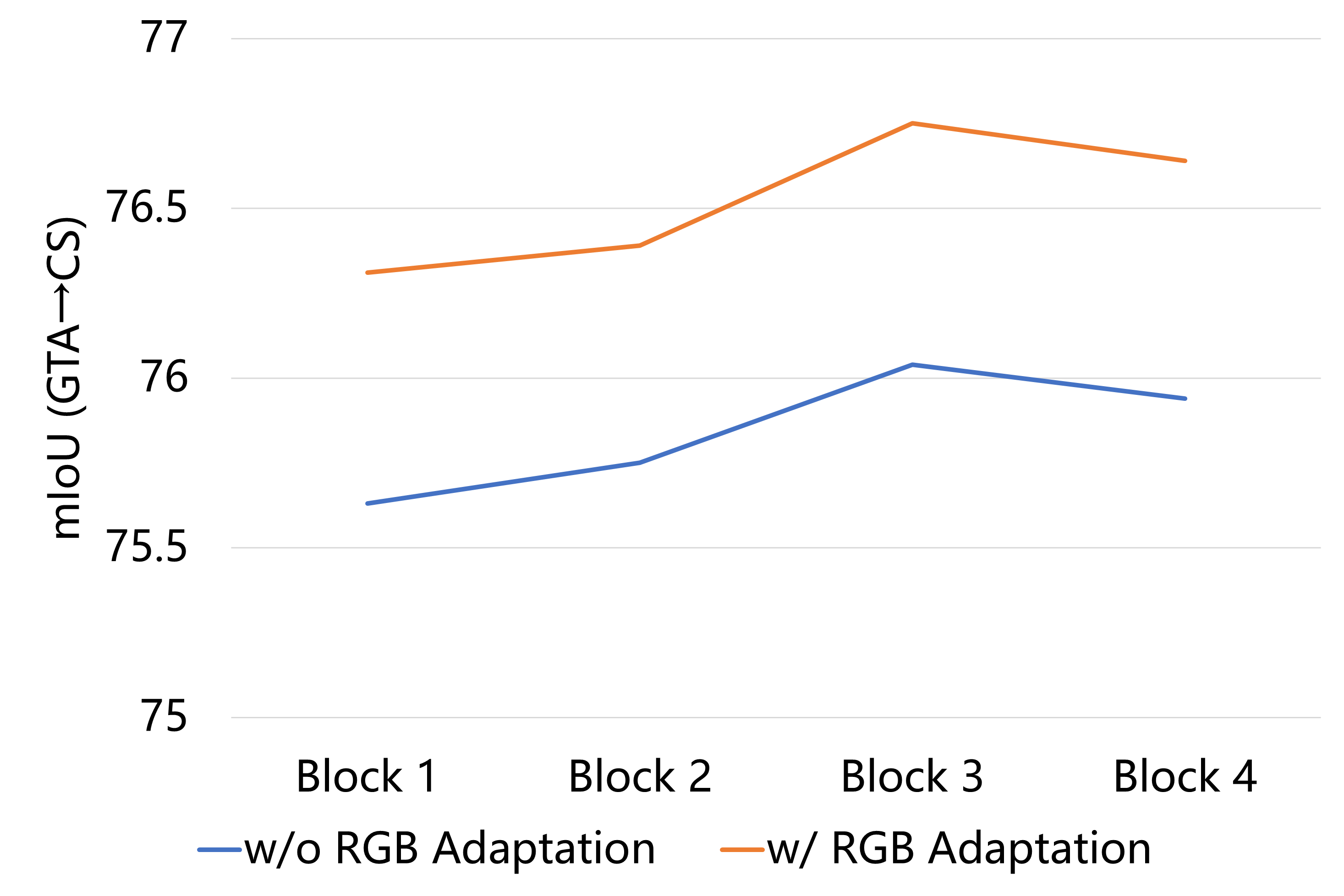
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024

0
Can Modifying Data Address Graph Domain Adaptation?
Renhong Huang, Jiarong Xu, Xin Jiang, Ruichuan An, Yang Yang
Graph neural networks (GNNs) have demonstrated remarkable success in numerous graph analytical tasks. Yet, their effectiveness is often compromised in real-world scenarios due to distribution shifts, limiting their capacity for knowledge transfer across changing environments or domains. Recently, Unsupervised Graph Domain Adaptation (UGDA) has been introduced to resolve this issue. UGDA aims to facilitate knowledge transfer from a labeled source graph to an unlabeled target graph. Current UGDA efforts primarily focus on model-centric methods, such as employing domain invariant learning strategies and designing model architectures. However, our critical examination reveals the limitations inherent to these model-centric methods, while a data-centric method allowed to modify the source graph provably demonstrates considerable potential. This insight motivates us to explore UGDA from a data-centric perspective. By revisiting the theoretical generalization bound for UGDA, we identify two data-centric principles for UGDA: alignment principle and rescaling principle. Guided by these principles, we propose GraphAlign, a novel UGDA method that generates a small yet transferable graph. By exclusively training a GNN on this new graph with classic Empirical Risk Minimization (ERM), GraphAlign attains exceptional performance on the target graph. Extensive experiments under various transfer scenarios demonstrate the GraphAlign outperforms the best baselines by an average of 2.16%, training on the generated graph as small as 0.25~1% of the original training graph.
Read more7/30/2024