Multi-Task Learning for Features Extraction in Financial Annual Reports
2404.05281
0
0
⛏️
Abstract
For assessing various performance indicators of companies, the focus is shifting from strictly financial (quantitative) publicly disclosed information to qualitative (textual) information. This textual data can provide valuable weak signals, for example through stylistic features, which can complement the quantitative data on financial performance or on Environmental, Social and Governance (ESG) criteria. In this work, we use various multi-task learning methods for financial text classification with the focus on financial sentiment, objectivity, forward-looking sentence prediction and ESG-content detection. We propose different methods to combine the information extracted from training jointly on different tasks; our best-performing method highlights the positive effect of explicitly adding auxiliary task predictions as features for the final target task during the multi-task training. Next, we use these classifiers to extract textual features from annual reports of FTSE350 companies and investigate the link between ESG quantitative scores and these features.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores using multi-task learning to extract key features from financial annual reports.
- The authors developed a model that can simultaneously identify different types of information, such as financial data, Corporate Social Responsibility (CSR) activities, and other relevant details.
- The goal is to create a more comprehensive and accurate system for extracting valuable insights from complex financial documents.
Plain English Explanation
Financial annual reports contain a wealth of information, but sifting through all the details can be challenging. The researchers in this study aimed to create a more efficient way to extract important data from these reports.
They used a technique called multi-task learning, which allows a single model to perform multiple related tasks at the same time. For example, the model could be trained to identify financial figures, mentions of CSR initiatives, and other key pieces of information - all while processing the same document.
The advantage of this approach is that the different tasks can reinforce each other and lead to better performance overall. By learning to recognize various types of relevant information in parallel, the model can build a more holistic understanding of the report's contents.
This could be particularly useful for analysts, investors, and others who need to quickly and accurately extract insights from large collections of financial documents. Rather than manually sifting through each report, they could rely on an automated system to surface the most important details.
Technical Explanation
The researchers developed a multi-task learning architecture to tackle the problem of feature extraction from financial annual reports. Their model was trained to simultaneously identify three key elements:
- Financial data, such as revenue, expenses, and profit figures
- Mentions of Corporate Social Responsibility (CSR) activities
- Other relevant information that could provide valuable insights
By learning these interconnected tasks together, the model was able to leverage the relationships between them and achieve better performance compared to single-task approaches.
The core of the model was a transformer-based Automatic Detection of Relevant Information for Predictions and Forecasts in Financial Texts encoder that processed the input text. This was followed by task-specific heads that produced the desired outputs for each sub-task.
The researchers experimented with different ways of sharing information between the tasks, such as having the tasks share certain model layers or using cross-stitch units to dynamically adjust the flow of information. They found that these multi-task approaches outperformed single-task baselines on a range of evaluation metrics.
Critical Analysis
The paper presents a promising approach for extracting valuable insights from financial annual reports. By leveraging multi-task learning, the model can take advantage of the relationships between different types of information, potentially leading to more accurate and comprehensive feature extraction.
However, the researchers acknowledge several limitations and areas for further exploration. For example, the experiments were conducted on a relatively small dataset, and the model's performance may need to be evaluated on larger, more diverse corpora. Additionally, the paper does not deeply explore the interpretability of the model's predictions, which could be important for trust and real-world applications.
Another potential issue is the reliance on transformer-based architectures, which can be computationally intensive and potentially less efficient than other neural network designs. Detection of Temporality at the Discourse Level in Financial News or Assessing the Quality of Information Extraction may offer insights into alternative approaches that could address these concerns.
Overall, the research presented in this paper represents a valuable contribution to the field of financial document analysis. However, further work is needed to M2SA: A Multimodal, Multilingual Model for Sentiment Analysis of Tweets and Death of Feature Engineering: Bert with Linguistic Features for SQuAD the model's robustness, scalability, and interpretability.
Conclusion
This paper explores the use of multi-task learning to extract a wide range of valuable information from financial annual reports. By training a single model to simultaneously identify financial data, CSR activities, and other relevant details, the researchers were able to create a more comprehensive and accurate feature extraction system.
The results of this study suggest that multi-task learning could be a powerful tool for streamlining the analysis of complex financial documents. As organizations continue to generate increasing volumes of data, having efficient and effective ways to extract meaningful insights will become increasingly important.
While the current model has some limitations, the researchers have laid the groundwork for further advancements in this area. Continued refinement and testing on larger, more diverse datasets could lead to significant improvements in the state of the art for financial document analysis.
Related Papers
🔎
Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no, Enrique Costa-Montenegro
0
0
Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (NLP) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (LDA) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. We created an experimental data set composed of 2,158 financial news items that were manually labelled by NLP researchers to evaluate our solution. The ROUGE-L values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with LDA to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text.
4/3/2024
✨
Efficient Sentiment Analysis: A Resource-Aware Evaluation of Feature Extraction Techniques, Ensembling, and Deep Learning Models
Mahammed Kamruzzaman, Gene Louis Kim
0
0
While reaching for NLP systems that maximize accuracy, other important metrics of system performance are often overlooked. Prior models are easily forgotten despite their possible suitability in settings where large computing resources are unavailable or relatively more costly. In this paper, we perform a broad comparative evaluation of document-level sentiment analysis models with a focus on resource costs that are important for the feasibility of model deployment and general climate consciousness. Our experiments consider different feature extraction techniques, the effect of ensembling, task-specific deep learning modeling, and domain-independent large language models (LLMs). We find that while a fine-tuned LLM achieves the best accuracy, some alternate configurations provide huge (up to 24, 283 *) resource savings for a marginal (<1%) loss in accuracy. Furthermore, we find that for smaller datasets, the differences in accuracy shrink while the difference in resource consumption grows further.
4/19/2024
Characterizing Multimodal Long-form Summarization: A Case Study on Financial Reports
Tianyu Cao, Natraj Raman, Danial Dervovic, Chenhao Tan
0
0
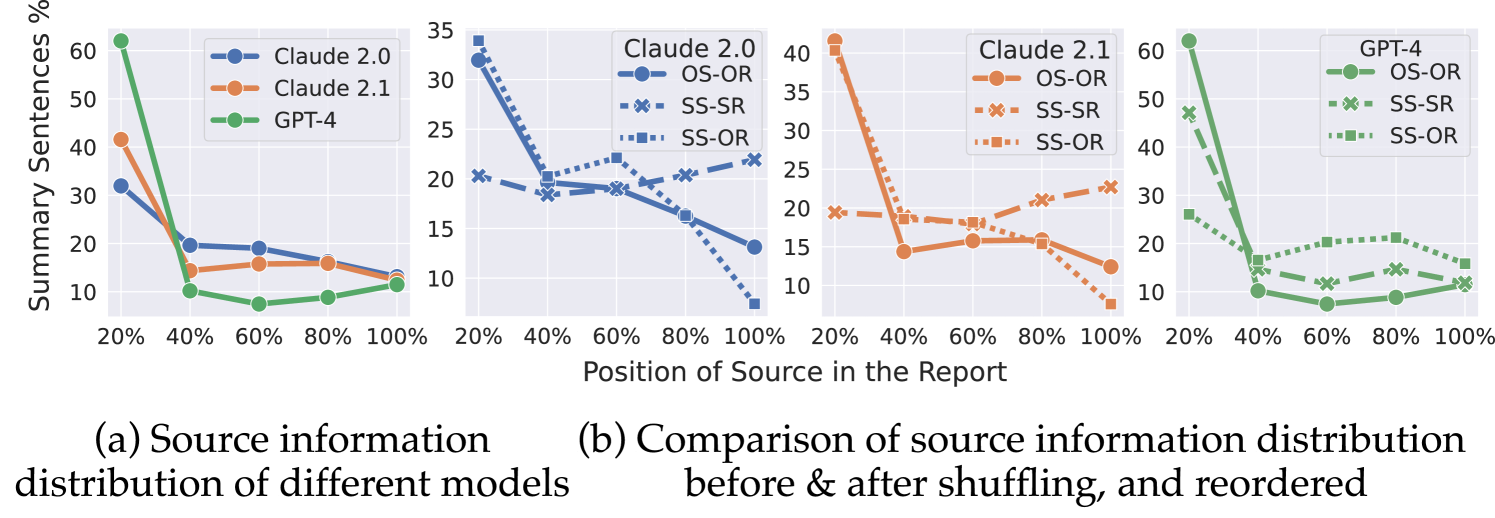
As large language models (LLMs) expand the power of natural language processing to handle long inputs, rigorous and systematic analyses are necessary to understand their abilities and behavior. A salient application is summarization, due to its ubiquity and controversy (e.g., researchers have declared the death of summarization). In this paper, we use financial report summarization as a case study because financial reports not only are long but also use numbers and tables extensively. We propose a computational framework for characterizing multimodal long-form summarization and investigate the behavior of Claude 2.0/2.1, GPT-4/3.5, and Command. We find that GPT-3.5 and Command fail to perform this summarization task meaningfully. For Claude 2 and GPT-4, we analyze the extractiveness of the summary and identify a position bias in LLMs. This position bias disappears after shuffling the input for Claude, which suggests that Claude has the ability to recognize important information. We also conduct a comprehensive investigation on the use of numeric data in LLM-generated summaries and offer a taxonomy of numeric hallucination. We employ prompt engineering to improve GPT-4's use of numbers with limited success. Overall, our analyses highlight the strong capability of Claude 2 in handling long multimodal inputs compared to GPT-4.
4/10/2024
Detection of Temporality at Discourse Level on Financial News by Combining Natural Language Processing and Machine Learning
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Ana Barros-Vila, Francisco J. Gonz'alez-Casta~no
0
0
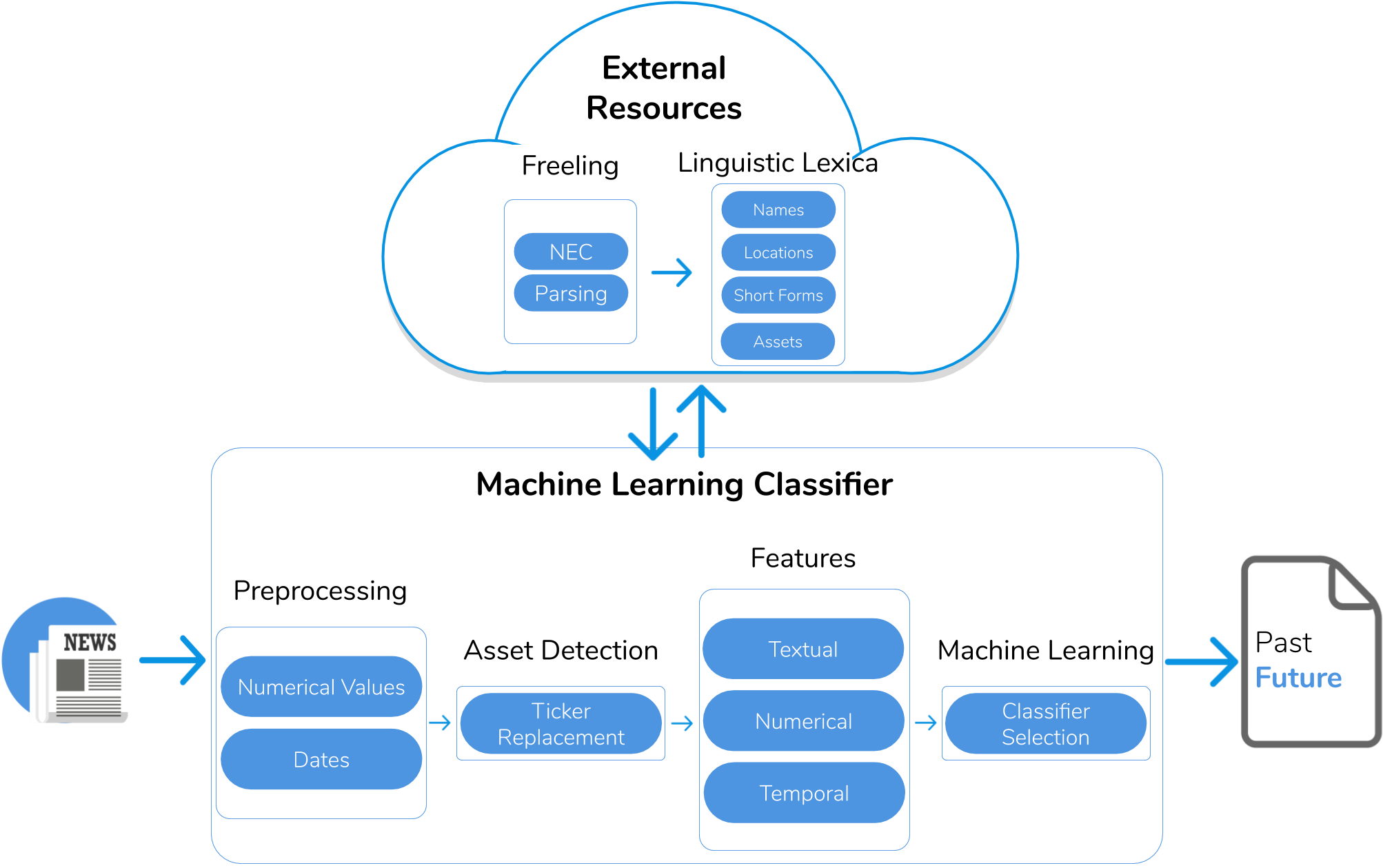
Finance-related news such as Bloomberg News, CNN Business and Forbes are valuable sources of real data for market screening systems. In news, an expert shares opinions beyond plain technical analyses that include context such as political, sociological and cultural factors. In the same text, the expert often discusses the performance of different assets. Some key statements are mere descriptions of past events while others are predictions. Therefore, understanding the temporality of the key statements in a text is essential to separate context information from valuable predictions. We propose a novel system to detect the temporality of finance-related news at discourse level that combines Natural Language Processing and Machine Learning techniques, and exploits sophisticated features such as syntactic and semantic dependencies. More specifically, we seek to extract the dominant tenses of the main statements, which may be either explicit or implicit. We have tested our system on a labelled dataset of finance-related news annotated by researchers with knowledge in the field. Experimental results reveal a high detection precision compared to an alternative rule-based baseline approach. Ultimately, this research contributes to the state-of-the-art of market screening by identifying predictive knowledge for financial decision making.
4/3/2024