Multilingual Fine-Grained News Headline Hallucination Detection

0

Sign in to get full access
Overview
- This paper proposes a multilingual fine-grained news headline hallucination detection model.
- Hallucination refers to the generation of irrelevant or misleading content by language models.
- The model aims to detect hallucination at the word, entity, and sentence level across multiple languages.
- The researchers create a new dataset for this task and evaluate their model's performance.
Plain English Explanation
The paper describes a system that can identify when a news headline contains made-up or irrelevant information. This is an important problem, as language models used to generate text can sometimes produce content that is not based on facts.
The researchers developed a model that can detect different types of hallucination, such as at the individual word level, the entity level (e.g. names, places), and the overall sentence level. Importantly, the model works across multiple languages, not just English.
To train and test their model, the researchers created a new dataset of news headlines annotated for different types of hallucination. They then evaluated how well their model could identify hallucinated content in this dataset.
The key benefit of this work is developing the capability to automatically catch when a headline generator or other language model is producing inaccurate or misleading information. This can help ensure the reliability of AI-generated content, especially in high-stakes domains like news reporting.
Technical Explanation
The paper introduces a multilingual fine-grained news headline hallucination detection model. Hallucination refers to the generation of irrelevant or misleading content by language models. The proposed model aims to detect hallucination at the word, entity, and sentence level across multiple languages.
To support this task, the researchers created a new dataset of news headlines annotated for different types of hallucination. They then developed a multilingual transformer-based model to classify each token, entity, and sentence as either hallucinated or not.
The experimental results demonstrate that the model achieves strong performance on the hallucination detection task across several languages. The researchers also analyze the model's performance on different types of hallucination and investigate how the model's decisions are influenced by various input features.
Critical Analysis
The paper presents a comprehensive approach to detecting hallucination in multilingual news headlines. However, the dataset used for training and evaluation is relatively small, which may limit the model's generalization to real-world scenarios with greater linguistic diversity and complexity.
Additionally, the paper does not address potential biases or limitations in the model's performance, such as its ability to handle low-resource languages or detect more nuanced forms of hallucination. Further research is needed to expand the scope and robustness of the hallucination detection capabilities.
Conclusion
This paper presents a multilingual fine-grained news headline hallucination detection model that can identify different types of hallucination at the word, entity, and sentence level. The researchers create a new dataset and demonstrate the model's strong performance across several languages.
This work is an important step towards ensuring the reliability and trustworthiness of AI-generated content, particularly in high-impact domains like news reporting. By detecting hallucination, this model can help mitigate the spread of misinformation and enhance the transparency of language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multilingual Fine-Grained News Headline Hallucination Detection
Jiaming Shen, Tianqi Liu, Jialu Liu, Zhen Qin, Jay Pavagadhi, Simon Baumgartner, Michael Bendersky
The popularity of automated news headline generation has surged with advancements in pre-trained language models. However, these models often suffer from the ``hallucination'' problem, where the generated headline is not fully supported by its source article. Efforts to address this issue have predominantly focused on English, using over-simplistic classification schemes that overlook nuanced hallucination types. In this study, we introduce the first multilingual, fine-grained news headline hallucination detection dataset that contains over 11 thousand pairs in 5 languages, each annotated with detailed hallucination types by experts. We conduct extensive experiments on this dataset under two settings. First, we implement several supervised fine-tuning approaches as preparatory solutions and demonstrate this dataset's challenges and utilities. Second, we test various large language models' in-context learning abilities and propose two novel techniques, language-dependent demonstration selection and coarse-to-fine prompting, to boost the few-shot hallucination detection performance in terms of the example-F1 metric. We release this dataset to foster further research in multilingual, fine-grained headline hallucination detection.
Read more7/24/2024

0
Fine-grained Hallucination Detection and Editing for Language Models
Abhika Mishra, Akari Asai, Vidhisha Balachandran, Yizhong Wang, Graham Neubig, Yulia Tsvetkov, Hannaneh Hajishirzi
Large language models (LMs) are prone to generate factual errors, which are often called hallucinations. In this paper, we introduce a comprehensive taxonomy of hallucinations and argue that hallucinations manifest in diverse forms, each requiring varying degrees of careful assessments to verify factuality. We propose a novel task of automatic fine-grained hallucination detection and construct a new evaluation benchmark, FavaBench, that includes about one thousand fine-grained human judgments on three LM outputs across various domains. Our analysis reveals that ChatGPT and Llama2-Chat (70B, 7B) exhibit diverse types of hallucinations in the majority of their outputs in information-seeking scenarios. We train FAVA, a retrieval-augmented LM by carefully creating synthetic data to detect and correct fine-grained hallucinations. On our benchmark, our automatic and human evaluations show that FAVA significantly outperforms ChatGPT and GPT-4 on fine-grained hallucination detection, and edits suggested by FAVA improve the factuality of LM-generated text.
Read more8/14/2024
0
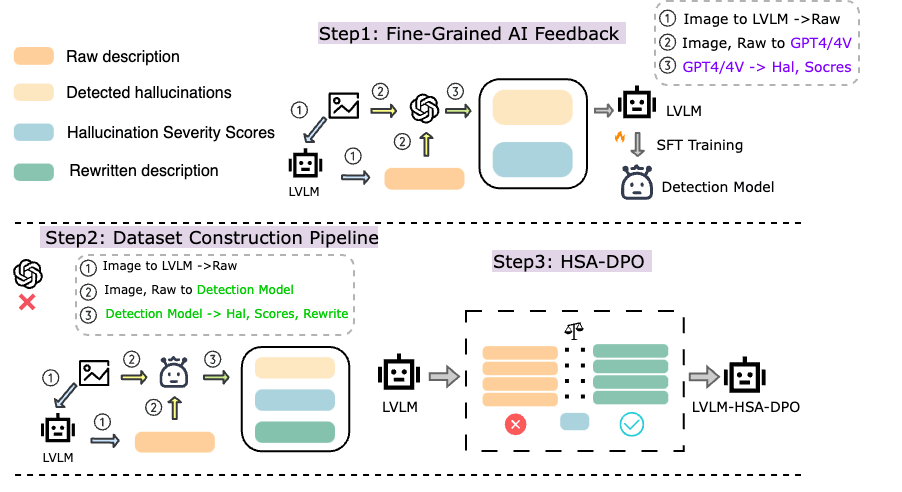
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024
🛸
0
AutoHall: Automated Hallucination Dataset Generation for Large Language Models
Zouying Cao, Yifei Yang, Hai Zhao
While Large language models (LLMs) have garnered widespread applications across various domains due to their powerful language understanding and generation capabilities, the detection of non-factual or hallucinatory content generated by LLMs remains scarce. Currently, one significant challenge in hallucination detection is the laborious task of time-consuming and expensive manual annotation of the hallucinatory generation. To address this issue, this paper first introduces a method for automatically constructing model-specific hallucination datasets based on existing fact-checking datasets called AutoHall. Furthermore, we propose a zero-resource and black-box hallucination detection method based on self-contradiction. We conduct experiments towards prevalent open-/closed-source LLMs, achieving superior hallucination detection performance compared to extant baselines. Moreover, our experiments reveal variations in hallucination proportions and types among different models.
Read more7/22/2024