Multimodal Contextual Dialogue Breakdown Detection for Conversational AI Models

0

Sign in to get full access
Overview
- This paper proposes a multimodal approach for detecting dialogue breakdowns in conversational AI models.
- The method combines textual, visual, and acoustic signals to identify when a conversation goes off-track or becomes incoherent.
- The goal is to enable conversational AI systems to better understand and respond to contextual cues, improving the overall quality of the interaction.
Plain English Explanation
Conversational AI models, like chatbots and virtual assistants, are designed to have natural conversations with users. However, sometimes these conversations can go off-track or become confusing and incoherent, a problem known as a "dialogue breakdown." This paper presents a new way to detect these breakdowns by using multiple types of information - text, visuals, and audio.
The key idea is that by considering not just the words used, but also the tone of voice, facial expressions, and other contextual cues, the AI can better understand when a conversation is starting to go wrong. This allows the system to intervene and try to get the conversation back on track, improving the overall user experience.
For example, if a user is asking a question but seems frustrated or confused based on their tone and body language, the system could detect this and provide a more helpful, clarifying response, rather than forging ahead with the conversation.
Technical Explanation
The proposed approach, called Multimodal Contextual Dialogue Breakdown Detection (MCDBD), combines textual, visual, and acoustic signals to identify dialogue breakdowns. The authors leverage large language models, computer vision techniques, and audio processing to extract relevant features from the conversational interaction.
These multimodal features are then fed into a neural network that is trained to classify whether a given dialogue turn represents a breakdown or not. The model is trained on a dataset of annotated dialogues, where human raters have identified the points at which the conversation went off-track.
The results show that the multimodal approach outperforms text-only baselines, demonstrating the value of incorporating additional modalities to better understand the context of the conversation. The authors also provide an in-depth analysis of the model's performance and the relative importance of the different input features.
Critical Analysis
The proposed MCDBD approach represents an important step forward in enabling conversational AI systems to better understand and respond to dialogue breakdowns. By considering multiple modalities, the model can capture richer contextual information that is often crucial for identifying when a conversation is going off-track.
However, the paper does not address some potential limitations of the approach. For example, the dataset used for training and evaluation may not be representative of the full range of real-world conversational scenarios, and the model's performance may suffer when deployed in more diverse or challenging environments.
Additionally, the paper does not delve into the ethical implications of deploying such a system, such as concerns around privacy or the potential for bias in the underlying data or model. These are important considerations as conversational AI becomes more prevalent in our daily lives.
Conclusion
This paper presents a novel multimodal approach for detecting dialogue breakdowns in conversational AI systems. By leveraging textual, visual, and acoustic signals, the proposed MCDBD model can more effectively identify when a conversation is starting to go off-track, allowing the system to intervene and provide more appropriate and helpful responses.
While the results are promising, the research also highlights the need for further work to address potential limitations and ethical concerns. As conversational AI continues to advance, it will be crucial to develop techniques that can ensure these systems are reliable, trustworthy, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Contextual Dialogue Breakdown Detection for Conversational AI Models
Md Messal Monem Miah, Ulie Schnaithmann, Arushi Raghuvanshi, Youngseo Son
Detecting dialogue breakdown in real time is critical for conversational AI systems, because it enables taking corrective action to successfully complete a task. In spoken dialog systems, this breakdown can be caused by a variety of unexpected situations including high levels of background noise, causing STT mistranscriptions, or unexpected user flows. In particular, industry settings like healthcare, require high precision and high flexibility to navigate differently based on the conversation history and dialogue states. This makes it both more challenging and more critical to accurately detect dialog breakdown. To accurately detect breakdown, we found it requires processing audio inputs along with downstream NLP model inferences on transcribed text in real time. In this paper, we introduce a Multimodal Contextual Dialogue Breakdown (MultConDB) model. This model significantly outperforms other known best models by achieving an F1 of 69.27.
Read more4/15/2024
🗣️
0
Is one brick enough to break the wall of spoken dialogue state tracking?
Lucas Druart (LIA), Valentin Vielzeuf (LIA), Yannick Est`eve (LIA)
In Task-Oriented Dialogue (TOD) systems, correctly updating the system's understanding of the user's requests (textit{a.k.a} dialogue state tracking) is key to a smooth interaction. Traditionally, TOD systems perform this update in three steps: transcription of the user's utterance, semantic extraction of the key concepts, and contextualization with the previously identified concepts. Such cascade approaches suffer from cascading errors and separate optimization. End-to-End approaches have been proven helpful up to the turn-level semantic extraction step. This paper goes one step further and provides (1) a novel approach for completely neural spoken DST, (2) an in depth comparison with a state of the art cascade approach and (3) avenues towards better context propagation. Our study highlights that jointly-optimized approaches are also competitive for contextually dependent tasks, such as Dialogue State Tracking (DST), especially in audio native settings. Context propagation in DST systems could benefit from training procedures accounting for the previous' context inherent uncertainty.
Read more7/2/2024
0
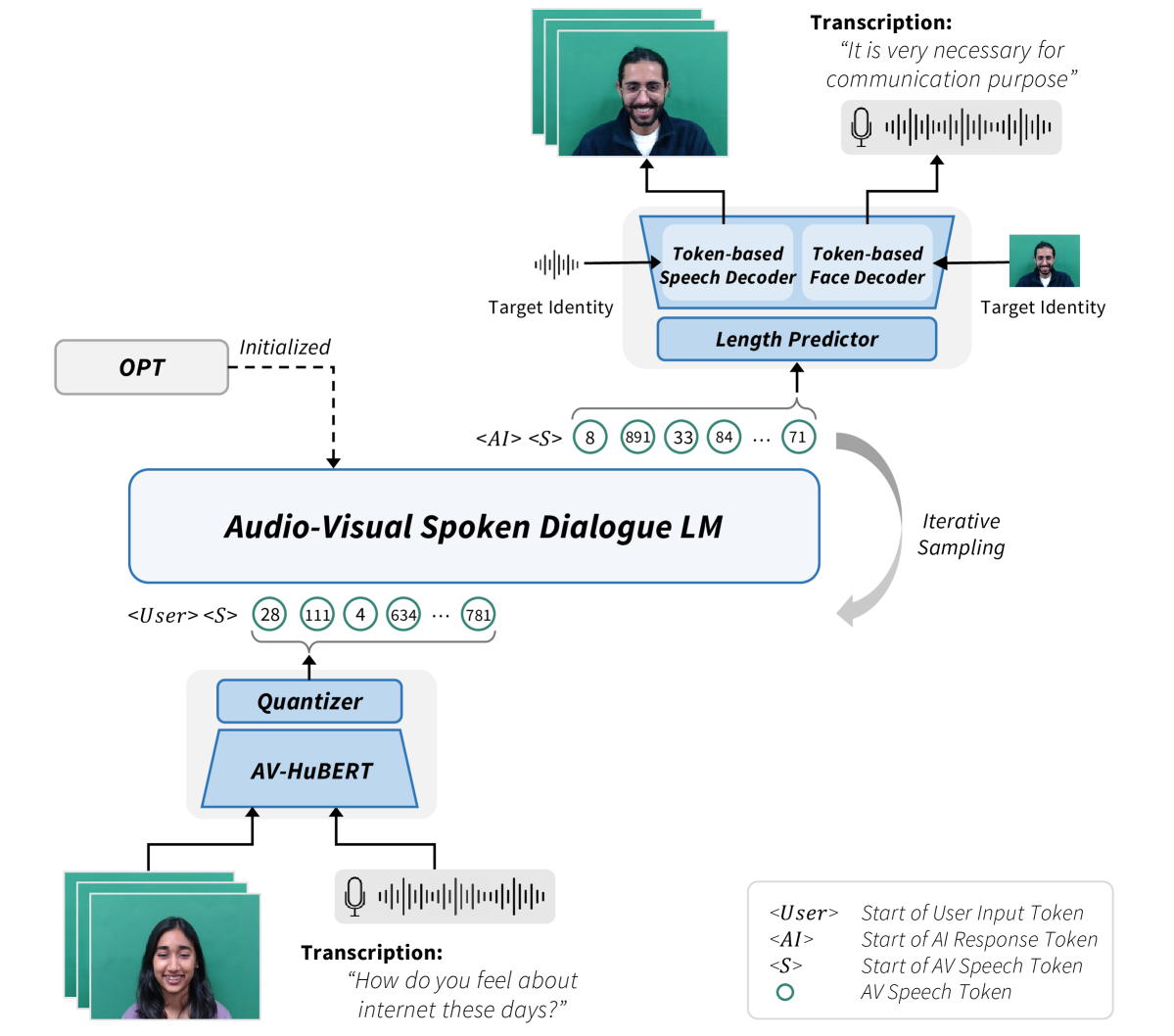
Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim, Joanna Hong, Jeong Hun Yeo, Yong Man Ro
In this paper, we introduce a novel Face-to-Face spoken dialogue model. It processes audio-visual speech from user input and generates audio-visual speech as the response, marking the initial step towards creating an avatar chatbot system without relying on intermediate text. To this end, we newly introduce MultiDialog, the first large-scale multimodal (i.e., audio and visual) spoken dialogue corpus containing 340 hours of approximately 9,000 dialogues, recorded based on the open domain dialogue dataset, TopicalChat. The MultiDialog contains parallel audio-visual recordings of conversation partners acting according to the given script with emotion annotations, which we expect to open up research opportunities in multimodal synthesis. Our Face-to-Face spoken dialogue model incorporates a textually pretrained large language model and adapts it into the audio-visual spoken dialogue domain by incorporating speech-text joint pretraining. Through extensive experiments, we validate the effectiveness of our model in facilitating a face-to-face conversation. Demo and data are available at https://multidialog.github.io and https://huggingface.co/datasets/IVLLab/MultiDialog, respectively.
Read more8/6/2024
✅
0
Conversation Disentanglement with Bi-Level Contrastive Learning
Chengyu Huang, Zheng Zhang, Hao Fei, Lizi Liao
Conversation disentanglement aims to group utterances into detached sessions, which is a fundamental task in processing multi-party conversations. Existing methods have two main drawbacks. First, they overemphasize pairwise utterance relations but pay inadequate attention to the utterance-to-context relation modeling. Second, huge amount of human annotated data is required for training, which is expensive to obtain in practice. To address these issues, we propose a general disentangle model based on bi-level contrastive learning. It brings closer utterances in the same session while encourages each utterance to be near its clustered session prototypes in the representation space. Unlike existing approaches, our disentangle model works in both supervised setting with labeled data and unsupervised setting when no such data is available. The proposed method achieves new state-of-the-art performance on both settings across several public datasets.
Read more9/4/2024