Enhancing Cross-Modal Fine-Tuning with Gradually Intermediate Modality Generation

0
Sign in to get full access
Overview
- This paper proposes a novel approach for enhancing cross-modal fine-tuning by gradually generating intermediate modalities during the training process.
- The key idea is to gradually bridge the gap between different modalities (e.g., text and image) by generating intermediary representations, rather than directly fine-tuning on the target task.
- The authors demonstrate the effectiveness of their approach on several cross-modal tasks, including image-text classification and multi-modal fusion.
Plain English Explanation
The paper addresses a common challenge in cross-modal learning, where models need to work with different types of data like text and images. Typically, these models are fine-tuned directly on the target task, but the authors argue that this can be suboptimal.
Instead, the proposed approach gradually generates intermediate representations that help bridge the gap between the modalities. For example, when fine-tuning a model to classify images and text, the system might first learn to generate a text representation from an image, then use that to classify the image-text pair.
By gradually transitioning between the modalities, the model is able to learn more effectively and achieve better performance on the final task. The authors show this approach works well for a variety of cross-modal problems, like identifying the contents of an image based on associated text or fusing information from different modalities.
Technical Explanation
The key innovation in this paper is the use of an intermediate modality generation mechanism to enhance cross-modal fine-tuning. Instead of directly fine-tuning a pre-trained model on the target cross-modal task, the authors propose a two-stage approach:
-
Intermediate Modality Generation: The model first learns to generate an intermediate representation that bridges the gap between the input and target modalities. For example, when fine-tuning for an image-text classification task, the model would first learn to generate a text representation from an input image.
-
Cross-Modal Fine-Tuning: The model then uses the generated intermediate representations to fine-tune on the target cross-modal task, such as classifying the image-text pair.
The authors demonstrate the effectiveness of this approach on several benchmark datasets and show that it outperforms standard fine-tuning techniques. They also provide insights into how the intermediate representations are learned and discuss the importance of sparsity in the generated representations.
Critical Analysis
The authors provide a thorough evaluation of their approach and address several potential limitations. One key concern is the computational overhead of the two-stage training process, which may be more resource-intensive than direct fine-tuning.
Additionally, the paper does not explore the potential for multi-modal diagnostic frameworks that could further enhance the understanding and interpretability of the cross-modal interactions learned by the model.
Overall, the proposed approach represents an interesting and promising direction for improving cross-modal learning, but further research is needed to address these potential drawbacks and explore additional applications and extensions of the technique.
Conclusion
This paper presents a novel approach for enhancing cross-modal fine-tuning by gradually generating intermediate modality representations during the training process. The authors demonstrate the effectiveness of their method on several benchmark tasks and provide insights into the underlying mechanisms.
While the two-stage training process introduces some computational overhead, the resulting performance gains suggest that this approach could be a valuable tool for researchers and practitioners working on cross-modal learning problems. Future work could explore ways to further optimize the training process and investigate additional applications of the intermediate modality generation technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Cross-Modal Fine-Tuning with Gradually Intermediate Modality Generation
Lincan Cai, Shuang Li, Wenxuan Ma, Jingxuan Kang, Binhui Xie, Zixun Sun, Chengwei Zhu
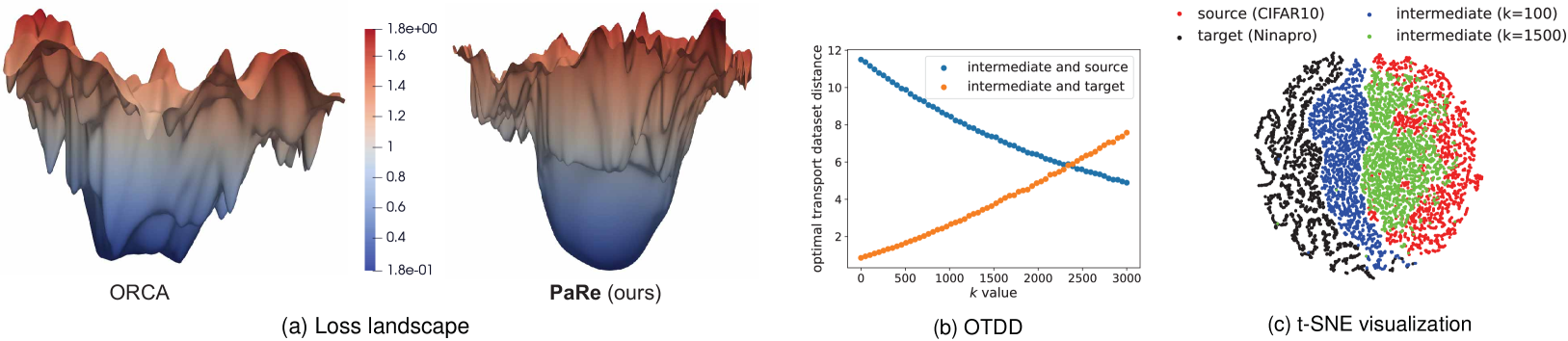
Large-scale pretrained models have proven immensely valuable in handling data-intensive modalities like text and image. However, fine-tuning these models for certain specialized modalities, such as protein sequence and cosmic ray, poses challenges due to the significant modality discrepancy and scarcity of labeled data. In this paper, we propose an end-to-end method, PaRe, to enhance cross-modal fine-tuning, aiming to transfer a large-scale pretrained model to various target modalities. PaRe employs a gating mechanism to select key patches from both source and target data. Through a modality-agnostic Patch Replacement scheme, these patches are preserved and combined to construct data-rich intermediate modalities ranging from easy to hard. By gradually intermediate modality generation, we can not only effectively bridge the modality gap to enhance stability and transferability of cross-modal fine-tuning, but also address the challenge of limited data in the target modality by leveraging enriched intermediate modality data. Compared with hand-designed, general-purpose, task-specific, and state-of-the-art cross-modal fine-tuning approaches, PaRe demonstrates superior performance across three challenging benchmarks, encompassing more than ten modalities.
Read more6/14/2024
0
Multimodal Infusion Tuning for Large Models
Hao Sun, Yu Song, Xinyao Yu, Jiaqing Liu, Yen-Wei Chen, Lanfen Lin
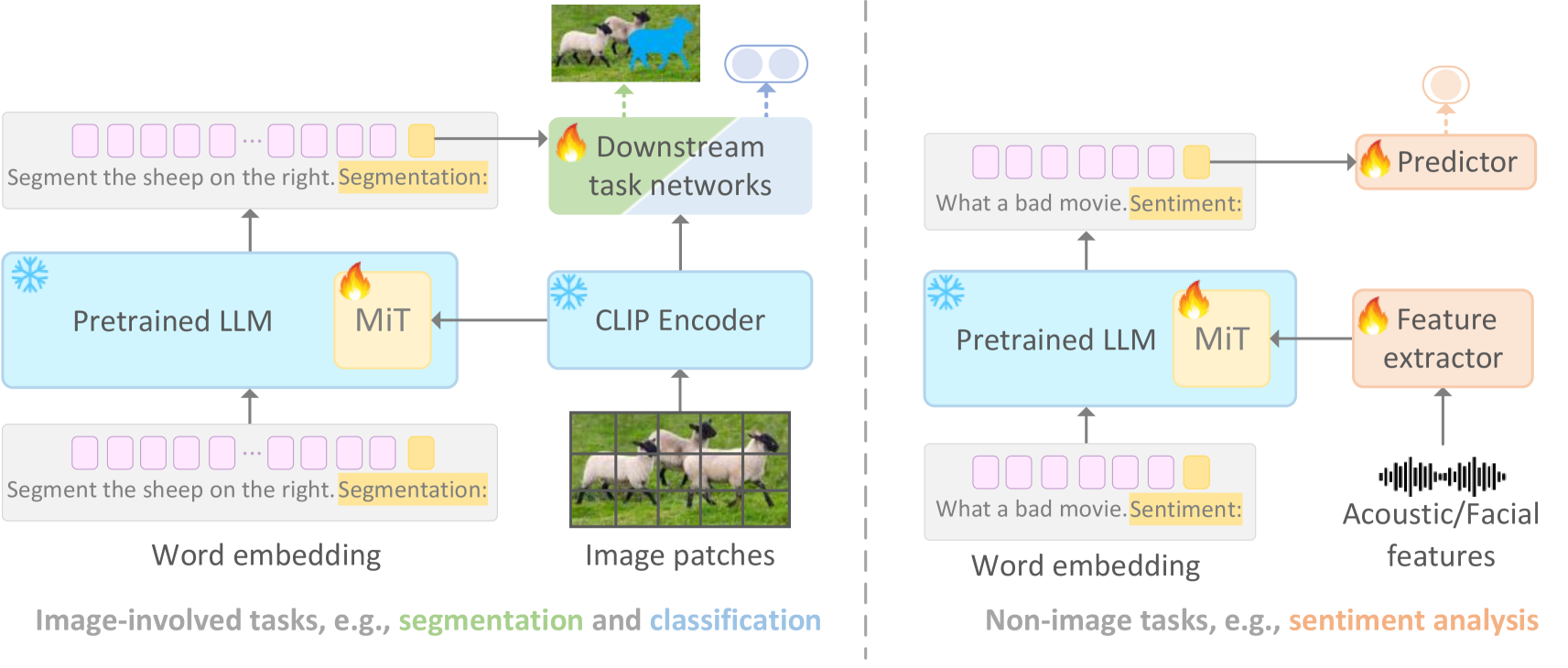
Recent advancements in large-scale models have showcased remarkable generalization capabilities in various tasks. However, integrating multimodal processing into these models presents a significant challenge, as it often comes with a high computational burden. To address this challenge, we introduce a new parameter-efficient multimodal tuning strategy for large models in this paper, referred to as Multimodal Infusion Tuning (MiT). MiT leverages decoupled self-attention mechanisms within large language models to effectively integrate information from diverse modalities such as images and acoustics. In MiT, we also design a novel adaptive rescaling strategy at the attention head level, which optimizes the representation of infused multimodal features. Notably, all foundation models are kept frozen during the tuning process to reduce the computational burden and only 2.5% parameters are tunable. We conduct experiments across a range of multimodal tasks, including image-related tasks like referring segmentation and non-image tasks such as sentiment analysis. Our results showcase that MiT achieves state-of-the-art performance in multimodal understanding while significantly reducing computational overhead(10% of previous methods). Moreover, our tuned model exhibits robust reasoning abilities even in complex scenarios.
Read more7/17/2024

0
Robust Latent Representation Tuning for Image-text Classification
Hao Sun, Yu Song
Large models have demonstrated exceptional generalization capabilities in computer vision and natural language processing. Recent efforts have focused on enhancing these models with multimodal processing abilities. However, addressing the challenges posed by scenarios where one modality is absent remains a significant hurdle. In response to this issue, we propose a robust latent representation tuning method for large models. Specifically, our approach introduces a modality latent translation module to maximize the correlation between modalities, resulting in a robust representation. Following this, a newly designed fusion module is employed to facilitate information interaction between the modalities. Within this framework, common semantics are refined during training, and robust performance is achieved even in the absence of one modality. Importantly, our method maintains the frozen state of the image and text foundation models to preserve their capabilities acquired through large-scale pretraining. We conduct experiments on several public datasets, and the results underscore the effectiveness of our proposed method.
Read more6/17/2024
0
Multi-Modal Parameter-Efficient Fine-tuning via Graph Neural Network
Bin Cheng, Jiaxuan Lu
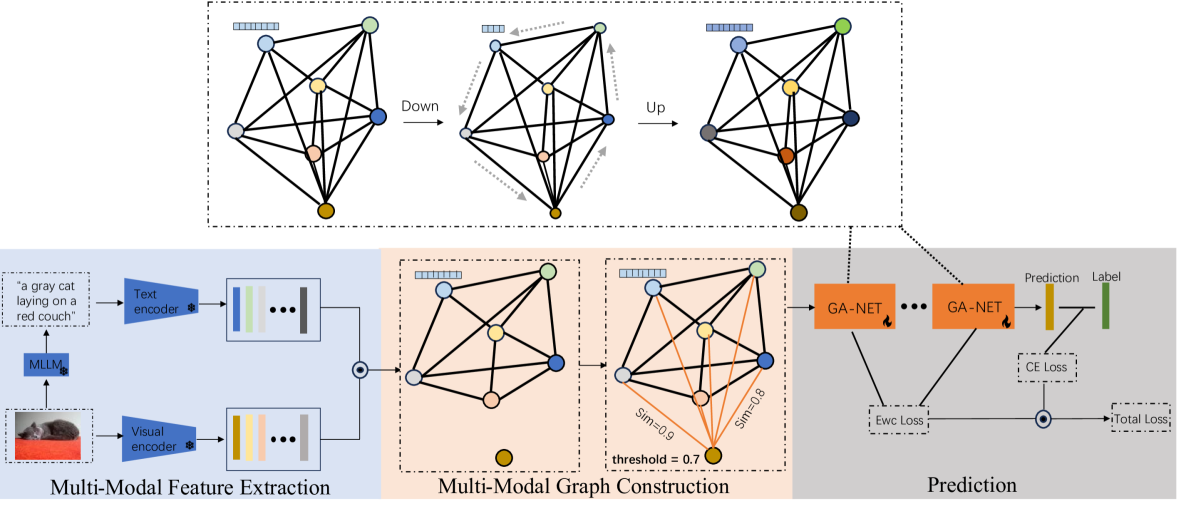
With the advent of the era of foundation models, pre-training and fine-tuning have become common paradigms. Recently, parameter-efficient fine-tuning has garnered widespread attention due to its better balance between the number of learnable parameters and performance. However, some current parameter-efficient fine-tuning methods only model a single modality and lack the utilization of structural knowledge in downstream tasks. To address this issue, this paper proposes a multi-modal parameter-efficient fine-tuning method based on graph networks. Each image is fed into a multi-modal large language model (MLLM) to generate a text description. The image and its corresponding text description are then processed by a frozen image encoder and text encoder to generate image features and text features, respectively. A graph is constructed based on the similarity of the multi-modal feature nodes, and knowledge and relationships relevant to these features are extracted from each node. Additionally, Elastic Weight Consolidation (EWC) regularization is incorporated into the loss function to mitigate the problem of forgetting during task learning. The proposed model achieves test accuracies on the OxfordPets, Flowers102, and Food101 datasets that improve by 4.45%, 2.92%, and 0.23%, respectively. The code is available at https://github.com/yunche0/GA-Net/tree/master.
Read more8/2/2024