Multimodal Misinformation Detection using Large Vision-Language Models

0

Sign in to get full access
Overview
- Multimodal misinformation detection using large vision-language models
- Combining visual and textual information to identify misinformation
- Potential for improving social media and news analytics
Plain English Explanation
Misinformation, or the spread of false or misleading information, has become a significant problem, especially on social media and in online news. This research explores using large vision-language models - AI systems that can understand both images and text - to detect and combat misinformation.
The key idea is that visual information, such as images or videos, can often provide important clues about the veracity of an online claim or article. By analyzing both the text and the associated visuals, these large models can potentially identify misinformation more accurately than using text alone.
For example, if a news article claims a certain event occurred, but the accompanying images seem to be from a different time or place, the model may flag it as potentially misleading. This multimodal approach, combining visual and textual cues, could be particularly valuable for identifying things like manipulated or out-of-context images that are commonly used to spread misinformation.
Technical Explanation
The researchers propose using large pre-trained vision-language models to tackle the problem of multimodal misinformation detection. These models, trained on vast amounts of image and text data, can understand and reason about the relationship between visual and textual information.
The researchers experiment with several different model architectures, including LEMMA and MMIDR, which are designed specifically for multimodal misinformation detection. They evaluate the models' performance on various misinformation detection tasks, including identifying manipulated images, verifying claims, and detecting fake news articles.
The results suggest that the multimodal approach, which considers both visual and textual cues, outperforms text-only models in many cases. The researchers also find that fine-tuning the pre-trained models on misinformation-specific datasets can further improve their accuracy.
Critical Analysis
The paper provides a promising direction for addressing the growing problem of misinformation, but it also acknowledges several limitations and areas for further research.
One key challenge is the inherent difficulty in defining and identifying "ground truth" for misinformation, as the line between truth and falsehood can be blurry, especially in complex, ambiguous, or rapidly evolving situations. The researchers note that their models may struggle with more subtle or context-dependent forms of misinformation.
Additionally, the paper does not address potential biases or ethical concerns that may arise from using large language models, which can reflect societal biases present in their training data. Careful consideration of these issues will be crucial as these technologies are deployed in real-world applications.
Further research is also needed to understand the generalizability of these methods across different languages, cultural contexts, and evolving misinformation tactics. Continued collaboration between the research community, platform providers, and fact-checking organizations will be important to address this complex and ever-changing challenge.
Conclusion
This research represents an important step towards leveraging the power of large multimodal language models to detect and combat the spread of online misinformation. By combining visual and textual cues, these models have the potential to more accurately identify manipulated content, verify claims, and flag potential instances of fake news.
While significant challenges remain, this work highlights the value of an interdisciplinary, multimodal approach to addressing the misinformation crisis. As these technologies continue to evolve, they may become increasingly crucial tools for maintaining the integrity of online information and promoting a more informed and engaged public.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Misinformation Detection using Large Vision-Language Models
Sahar Tahmasebi, Eric Muller-Budack, Ralph Ewerth
The increasing proliferation of misinformation and its alarming impact have motivated both industry and academia to develop approaches for misinformation detection and fact checking. Recent advances on large language models (LLMs) have shown remarkable performance in various tasks, but whether and how LLMs could help with misinformation detection remains relatively underexplored. Most of existing state-of-the-art approaches either do not consider evidence and solely focus on claim related features or assume the evidence to be provided. Few approaches consider evidence retrieval as part of the misinformation detection but rely on fine-tuning models. In this paper, we investigate the potential of LLMs for misinformation detection in a zero-shot setting. We incorporate an evidence retrieval component into the process as it is crucial to gather pertinent information from various sources to detect the veracity of claims. To this end, we propose a novel re-ranking approach for multimodal evidence retrieval using both LLMs and large vision-language models (LVLM). The retrieved evidence samples (images and texts) serve as the input for an LVLM-based approach for multimodal fact verification (LVLM4FV). To enable a fair evaluation, we address the issue of incomplete ground truth for evidence samples in an existing evidence retrieval dataset by annotating a more complete set of evidence samples for both image and text retrieval. Our experimental results on two datasets demonstrate the superiority of the proposed approach in both evidence retrieval and fact verification tasks and also better generalization capability across dataset compared to the supervised baseline.
Read more7/22/2024
🔎
0
LEMMA: Towards LVLM-Enhanced Multimodal Misinformation Detection with External Knowledge Augmentation
Keyang Xuan, Li Yi, Fan Yang, Ruochen Wu, Yi R. Fung, Heng Ji
The rise of multimodal misinformation on social platforms poses significant challenges for individuals and societies. Its increased credibility and broader impact compared to textual misinformation make detection complex, requiring robust reasoning across diverse media types and profound knowledge for accurate verification. The emergence of Large Vision Language Model (LVLM) offers a potential solution to this problem. Leveraging their proficiency in processing visual and textual information, LVLM demonstrates promising capabilities in recognizing complex information and exhibiting strong reasoning skills. In this paper, we first investigate the potential of LVLM on multimodal misinformation detection. We find that even though LVLM has a superior performance compared to LLMs, its profound reasoning may present limited power with a lack of evidence. Based on these observations, we propose LEMMA: LVLM-Enhanced Multimodal Misinformation Detection with External Knowledge Augmentation. LEMMA leverages LVLM intuition and reasoning capabilities while augmenting them with external knowledge to enhance the accuracy of misinformation detection. Our method improves the accuracy over the top baseline LVLM by 7% and 13% on Twitter and Fakeddit datasets respectively.
Read more6/24/2024

0
MMIDR: Teaching Large Language Model to Interpret Multimodal Misinformation via Knowledge Distillation
Longzheng Wang, Xiaohan Xu, Lei Zhang, Jiarui Lu, Yongxiu Xu, Hongbo Xu, Minghao Tang, Chuang Zhang
Automatic detection of multimodal misinformation has gained a widespread attention recently. However, the potential of powerful Large Language Models (LLMs) for multimodal misinformation detection remains underexplored. Besides, how to teach LLMs to interpret multimodal misinformation in cost-effective and accessible way is still an open question. To address that, we propose MMIDR, a framework designed to teach LLMs in providing fluent and high-quality textual explanations for their decision-making process of multimodal misinformation. To convert multimodal misinformation into an appropriate instruction-following format, we present a data augmentation perspective and pipeline. This pipeline consists of a visual information processing module and an evidence retrieval module. Subsequently, we prompt the proprietary LLMs with processed contents to extract rationales for interpreting the authenticity of multimodal misinformation. Furthermore, we design an efficient knowledge distillation approach to distill the capability of proprietary LLMs in explaining multimodal misinformation into open-source LLMs. To explore several research questions regarding the performance of LLMs in multimodal misinformation detection tasks, we construct an instruction-following multimodal misinformation dataset and conduct comprehensive experiments. The experimental findings reveal that our MMIDR exhibits sufficient detection performance and possesses the capacity to provide compelling rationales to support its assessments.
Read more4/9/2024
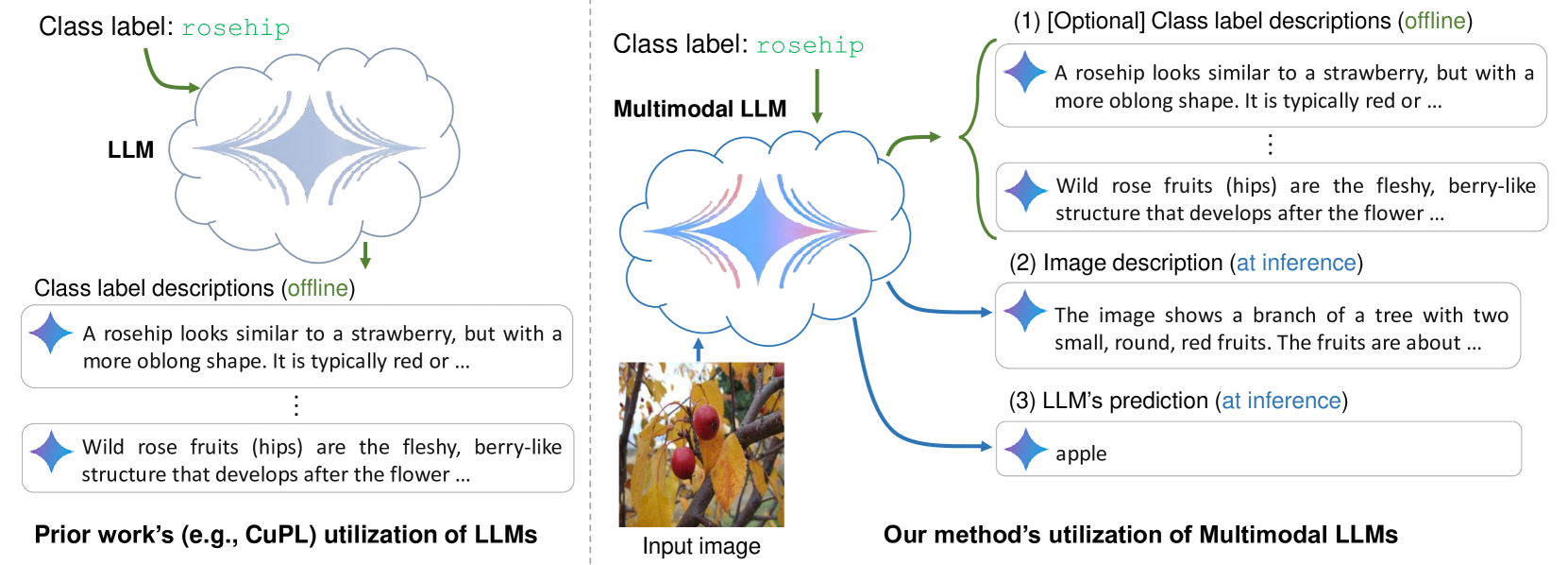
0
What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
Abdelrahman Abdelhamed, Mahmoud Afifi, Alec Go
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
Read more5/27/2024