Music auto-tagging in the long tail: A few-shot approach

0
Sign in to get full access
Overview
- The paper explores a few-shot approach to music auto-tagging, which aims to classify music into various genres and styles with limited training data.
- The researchers focus on the "long tail" of music genres that have fewer examples, aiming to improve classification performance in these underrepresented areas.
- The paper presents a novel few-shot learning framework and evaluates its effectiveness on several music auto-tagging datasets.
Plain English Explanation
Imagine you want to build a system that can automatically categorize songs into different musical genres and styles. This could be useful for music streaming services, radio stations, or music discovery apps. However, there's a challenge - some genres and styles have far fewer examples available to train the system on compared to more popular ones.
This paper tackles this "long tail" problem by proposing a new few-shot learning approach. Few-shot learning means the system can learn to classify new genres and styles with just a small number of training examples, rather than needing a large dataset.
The key idea is to first train the system on a broad set of musical genres and styles, giving it a general understanding of music. Then, when faced with a new, underrepresented genre, the system can quickly adapt and learn to classify it accurately using just a few examples. This allows the system to perform well even on niche or obscure musical styles that don't have a lot of training data available.
The researchers evaluate their few-shot learning approach on several music auto-tagging datasets and show that it outperforms traditional machine learning methods, especially for those "long tail" genres and styles. This could lead to more comprehensive and inclusive music classification systems in the future.
Technical Explanation
The paper introduces a novel few-shot learning framework for music auto-tagging. The core idea is to first train a base model on a broad set of musical genres and styles, giving the system a general understanding of music. Then, when faced with a new, underrepresented genre, the system can quickly adapt and learn to classify it accurately using just a few examples.
Specifically, the researchers propose a "prototypical network" architecture, which learns to map music input (e.g. audio features) into an embedding space where examples of the same genre/style are clustered closely together. During the few-shot learning stage, the system compares new examples to these learned "prototypes" to efficiently classify the music.
The paper evaluates this few-shot learning approach on several music auto-tagging datasets, including the Million Song Dataset and FMA. They show that it outperforms traditional supervised learning techniques, particularly for the "long tail" of underrepresented genres and styles.
Critical Analysis
The paper makes a compelling case for the value of few-shot learning in music auto-tagging, especially for handling the "long tail" of niche genres. By requiring just a handful of examples to learn new classes, the proposed framework can be more inclusive and comprehensive compared to systems that rely on large, balanced training datasets.
However, the paper does not fully address some potential limitations of the approach. For example, it's unclear how the few-shot learning system would handle highly ambiguous or subjective genre classifications, where even human experts may disagree. Additionally, the evaluation is primarily focused on static datasets, and the researchers do not explore how the system would perform in a more dynamic, real-world setting where new genres are constantly emerging.
Further research could investigate ways to make the few-shot learning more robust to these challenges, perhaps by incorporating additional contextual information or meta-learning techniques. Exploring the trade-offs between few-shot performance and broader generalization capabilities could also be a fruitful area for future work.
Conclusion
This paper presents a novel few-shot learning approach to music auto-tagging that shows promise for handling the "long tail" of underrepresented genres and styles. By leveraging a base of broad musical knowledge and quickly adapting to new examples, the system can provide more comprehensive and inclusive music classification capabilities compared to traditional supervised learning methods.
While the paper has some limitations, the core idea of few-shot learning for music tagging is an interesting and important direction for the field. As music catalogs continue to grow in breadth and diversity, such techniques could play a key role in building intelligent music systems that serve the full spectrum of musical tastes and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Music auto-tagging in the long tail: A few-shot approach
T. Aleksandra Ma, Alexander Lerch
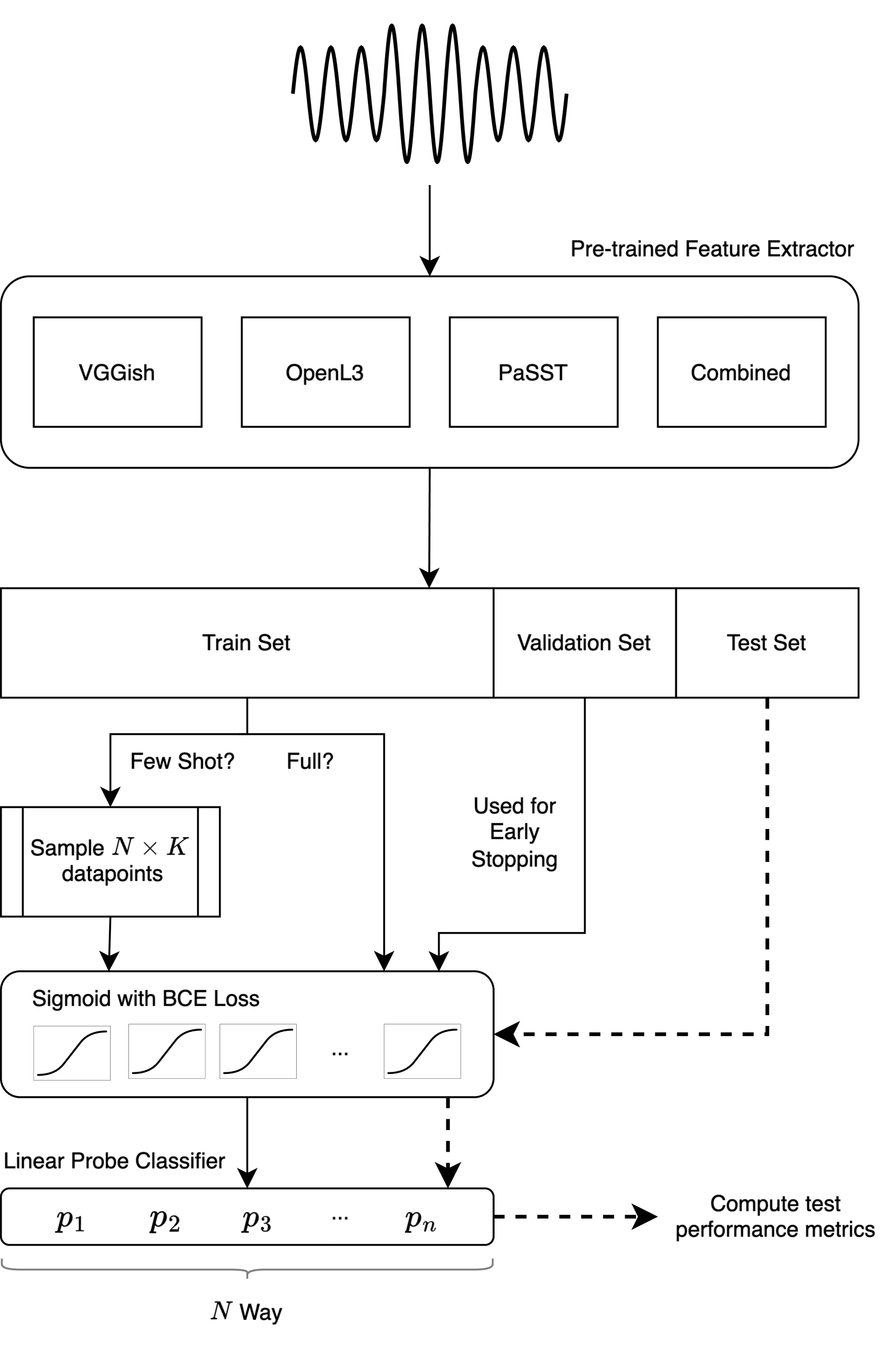
In the realm of digital music, using tags to efficiently organize and retrieve music from extensive databases is crucial for music catalog owners. Human tagging by experts is labor-intensive but mostly accurate, whereas automatic tagging through supervised learning has approached satisfying accuracy but is restricted to a predefined set of training tags. Few-shot learning offers a viable solution to expand beyond this small set of predefined tags by enabling models to learn from only a few human-provided examples to understand tag meanings and subsequently apply these tags autonomously. We propose to integrate few-shot learning methodology into multi-label music auto-tagging by using features from pre-trained models as inputs to a lightweight linear classifier, also known as a linear probe. We investigate different popular pre-trained features, as well as different few-shot parametrizations with varying numbers of classes and samples per class. Our experiments demonstrate that a simple model with pre-trained features can achieve performance close to state-of-the-art models while using significantly less training data, such as 20 samples per tag. Additionally, our linear probe performs competitively with leading models when trained on the entire training dataset. The results show that this transfer learning-based few-shot approach could effectively address the issue of automatically assigning long-tail tags with only limited labeled data.
Read more9/14/2024
0
New!Self-supervised Learning for Acoustic Few-Shot Classification
Jingyong Liang, Bernd Meyer, Issac Ning Lee, Thanh-Toan Do
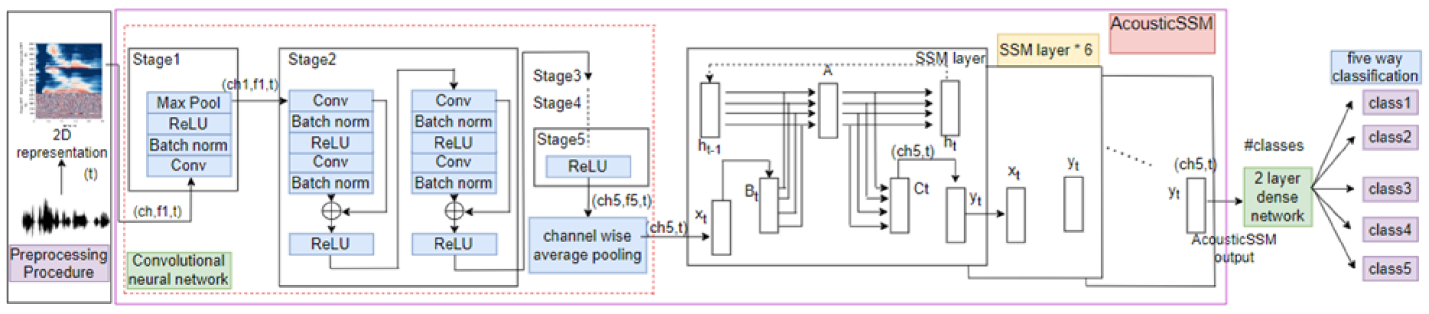
Labelled data are limited and self-supervised learning is one of the most important approaches for reducing labelling requirements. While it has been extensively explored in the image domain, it has so far not received the same amount of attention in the acoustic domain. Yet, reducing labelling is a key requirement for many acoustic applications. Specifically in bioacoustic, there are rarely sufficient labels for fully supervised learning available. This has led to the widespread use of acoustic recognisers that have been pre-trained on unrelated data for bioacoustic tasks. We posit that training on the actual task data and combining self-supervised pre-training with few-shot classification is a superior approach that has the ability to deliver high accuracy even when only a few labels are available. To this end, we introduce and evaluate a new architecture that combines CNN-based preprocessing with feature extraction based on state space models (SSMs). This combination is motivated by the fact that CNN-based networks alone struggle to capture temporal information effectively, which is crucial for classifying acoustic signals. SSMs, specifically S4 and Mamba, on the other hand, have been shown to have an excellent ability to capture long-range dependencies in sequence data. We pre-train this architecture using contrastive learning on the actual task data and subsequent fine-tuning with an extremely small amount of labelled data. We evaluate the performance of this proposed architecture for ($n$-shot, $n$-class) classification on standard benchmarks as well as real-world data. Our evaluation shows that it outperforms state-of-the-art architectures on the few-shot classification problem.
Read more9/17/2024

0
An Experimental Comparison Of Multi-view Self-supervised Methods For Music Tagging
Gabriel Meseguer-Brocal, Dorian Desblancs, Romain Hennequin
Self-supervised learning has emerged as a powerful way to pre-train generalizable machine learning models on large amounts of unlabeled data. It is particularly compelling in the music domain, where obtaining labeled data is time-consuming, error-prone, and ambiguous. During the self-supervised process, models are trained on pretext tasks, with the primary objective of acquiring robust and informative features that can later be fine-tuned for specific downstream tasks. The choice of the pretext task is critical as it guides the model to shape the feature space with meaningful constraints for information encoding. In the context of music, most works have relied on contrastive learning or masking techniques. In this study, we expand the scope of pretext tasks applied to music by investigating and comparing the performance of new self-supervised methods for music tagging. We open-source a simple ResNet model trained on a diverse catalog of millions of tracks. Our results demonstrate that, although most of these pre-training methods result in similar downstream results, contrastive learning consistently results in better downstream performance compared to other self-supervised pre-training methods. This holds true in a limited-data downstream context.
Read more4/16/2024

0
Text-Guided Mixup Towards Long-Tailed Image Categorization
Richard Franklin, Jiawei Yao, Deyang Zhong, Qi Qian, Juhua Hu
In many real-world applications, the frequency distribution of class labels for training data can exhibit a long-tailed distribution, which challenges traditional approaches of training deep neural networks that require heavy amounts of balanced data. Gathering and labeling data to balance out the class label distribution can be both costly and time-consuming. Many existing solutions that enable ensemble learning, re-balancing strategies, or fine-tuning applied to deep neural networks are limited by the inert problem of few class samples across a subset of classes. Recently, vision-language models like CLIP have been observed as effective solutions to zero-shot or few-shot learning by grasping a similarity between vision and language features for image and text pairs. Considering that large pre-trained vision-language models may contain valuable side textual information for minor classes, we propose to leverage text supervision to tackle the challenge of long-tailed learning. Concretely, we propose a novel text-guided mixup technique that takes advantage of the semantic relations between classes recognized by the pre-trained text encoder to help alleviate the long-tailed problem. Our empirical study on benchmark long-tailed tasks demonstrates the effectiveness of our proposal with a theoretical guarantee. Our code is available at https://github.com/rsamf/text-guided-mixup.
Read more9/6/2024