MV-CLIP: Multi-View CLIP for Zero-shot 3D Shape Recognition

0
👁️
Sign in to get full access
Overview
- Large pre-trained models have shown impressive performance in vision and language tasks, but lack comparable pre-trained models for 3D shapes.
- Recent methods use language-image pre-training to enable zero-shot 3D shape recognition, but the modality gap limits their confidence in this task.
- This paper aims to improve zero-shot 3D shape recognition by using view selection and hierarchical prompts.
Plain English Explanation
Modern AI models trained on large datasets have become remarkably capable at understanding and processing visual and textual information. However, these models have historically struggled when it comes to understanding 3D shapes and objects.
To address this, researchers have started exploring ways to leverage the power of these pre-trained vision and language models for 3D shape recognition. The key idea is to use the knowledge these models have gained from training on 2D images and text to also recognize and classify 3D shapes, even without any direct training on 3D data.
This paper proposes two novel techniques to improve the performance of this zero-shot 3D shape recognition. First, it uses "view selection" to identify the most informative 2D views of a 3D shape, which helps the model make more confident predictions. Second, it introduces "hierarchical prompts" - a way of providing the model with multi-level textual descriptions to guide its classification process.
By applying these techniques, the researchers were able to significantly boost the accuracy of zero-shot 3D shape recognition, without needing to train the model further on 3D data. This is an exciting development that could make 3D understanding much more accessible for a wide range of AI applications.
Technical Explanation
The core challenge addressed in this paper is the modality gap between 2D images and 3D shapes, which limits the ability of pre-trained language-image models to generalize well to 3D shape recognition tasks.
To overcome this, the paper proposes two key innovations:
-
View Selection: The researchers recognized that not all 2D views of a 3D shape are equally informative for classification. By identifying the views with the highest prediction confidence from the CLIP model, they were able to improve the overall accuracy of zero-shot 3D shape recognition.
-
Hierarchical Prompts: Instead of using a single textual prompt to describe a 3D shape, the paper introduces a two-level prompting strategy. The first layer provides broad, class-level descriptions, while the second layer refines the prediction with more specific, function-level details. This hierarchical approach helps the model better understand and classify the 3D shapes.
Remarkably, by applying these techniques to the CLIP model, the researchers were able to achieve impressive zero-shot 3D classification accuracies of 84.44%, 91.51%, and 66.17% on the ModelNet40, ModelNet10, and ShapeNet Core55 datasets, respectively, without any additional training.
Critical Analysis
The paper presents a well-designed and effective approach to improving zero-shot 3D shape recognition. However, a few potential limitations and areas for further research are worth considering:
-
The proposed techniques, while powerful, are still reliant on the quality and generalization capabilities of the underlying pre-trained language-image model (in this case, CLIP). Improvements to the base model could further enhance the zero-shot 3D recognition performance.
-
The paper focuses on using CLIP as an example, but it would be interesting to see how the view selection and hierarchical prompting strategies might apply to other pre-trained vision-language models, such as Perceiver IO.
-
While the zero-shot 3D recognition accuracies are impressive, it would be valuable to understand the model's performance on a wider range of 3D datasets and real-world scenarios, including more complex or deformed shapes.
-
The paper does not provide a detailed analysis of the computational efficiency or inference time of the proposed approach, which could be an important practical consideration for real-world applications.
Conclusion
This paper presents a novel and effective approach to improving zero-shot 3D shape recognition by leveraging view selection and hierarchical prompts. By addressing the modality gap between 2D images and 3D shapes, the researchers were able to significantly boost the performance of pre-trained language-image models on this task, without the need for additional training.
The techniques introduced in this work represent an important step forward in making 3D understanding more accessible for a wide range of AI applications, from robotics and autonomous vehicles to virtual design and e-commerce. As the field of 3D perception continues to evolve, the insights and methods presented in this paper are likely to inspire further research and innovation in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
MV-CLIP: Multi-View CLIP for Zero-shot 3D Shape Recognition
Dan Song, Xinwei Fu, Ning Liu, Weizhi Nie, Wenhui Li, Lanjun Wang, You Yang, Anan Liu
Large-scale pre-trained models have demonstrated impressive performance in vision and language tasks within open-world scenarios. Due to the lack of comparable pre-trained models for 3D shapes, recent methods utilize language-image pre-training to realize zero-shot 3D shape recognition. However, due to the modality gap, pretrained language-image models are not confident enough in the generalization to 3D shape recognition. Consequently, this paper aims to improve the confidence with view selection and hierarchical prompts. Leveraging the CLIP model as an example, we employ view selection on the vision side by identifying views with high prediction confidence from multiple rendered views of a 3D shape. On the textual side, the strategy of hierarchical prompts is proposed for the first time. The first layer prompts several classification candidates with traditional class-level descriptions, while the second layer refines the prediction based on function-level descriptions or further distinctions between the candidates. Remarkably, without the need for additional training, our proposed method achieves impressive zero-shot 3D classification accuracies of 84.44%, 91.51%, and 66.17% on ModelNet40, ModelNet10, and ShapeNet Core55, respectively. Furthermore, we will make the code publicly available to facilitate reproducibility and further research in this area.
Read more9/12/2024
🌐
0
PEVA-Net: Prompt-Enhanced View Aggregation Network for Zero/Few-Shot Multi-View 3D Shape Recognition
Dongyun Lin, Yi Cheng, Shangbo Mao, Aiyuan Guo, Yiqun Li
Large vision-language models have impressively promote the performance of 2D visual recognition under zero/few-shot scenarios. In this paper, we focus on exploiting the large vision-language model, i.e., CLIP, to address zero/few-shot 3D shape recognition based on multi-view representations. The key challenge for both tasks is to generate a discriminative descriptor of the 3D shape represented by multiple view images under the scenarios of either without explicit training (zero-shot 3D shape recognition) or training with a limited number of data (few-shot 3D shape recognition). We analyze that both tasks are relevant and can be considered simultaneously. Specifically, leveraging the descriptor which is effective for zero-shot inference to guide the tuning of the aggregated descriptor under the few-shot training can significantly improve the few-shot learning efficacy. Hence, we propose Prompt-Enhanced View Aggregation Network (PEVA-Net) to simultaneously address zero/few-shot 3D shape recognition. Under the zero-shot scenario, we propose to leverage the prompts built up from candidate categories to enhance the aggregation process of multiple view-associated visual features. The resulting aggregated feature serves for effective zero-shot recognition of the 3D shapes. Under the few-shot scenario, we first exploit a transformer encoder to aggregate the view-associated visual features into a global descriptor. To tune the encoder, together with the main classification loss, we propose a self-distillation scheme via a feature distillation loss by treating the zero-shot descriptor as the guidance signal for the few-shot descriptor. This scheme can significantly enhance the few-shot learning efficacy.
Read more5/1/2024
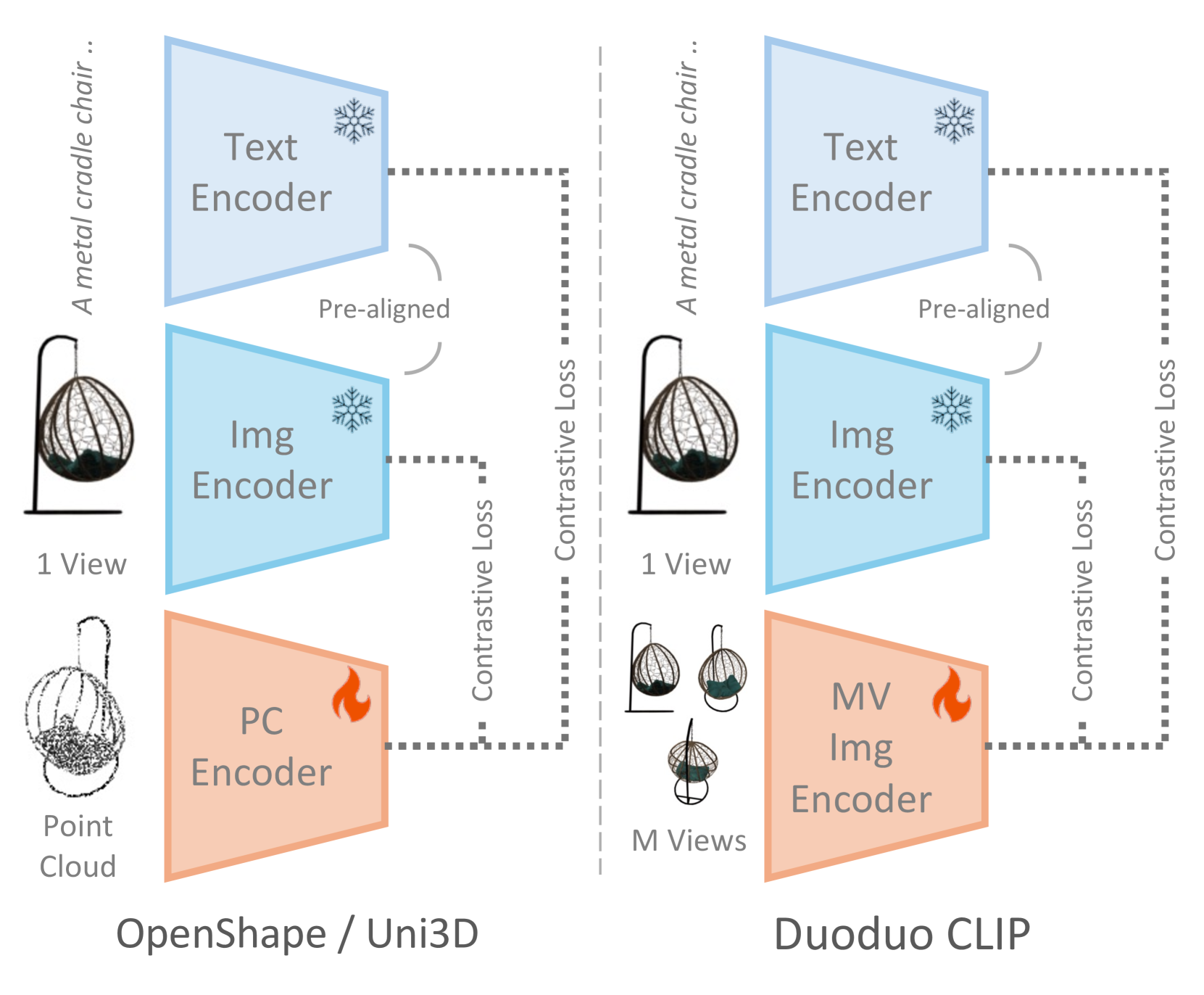
0
Duoduo CLIP: Efficient 3D Understanding with Multi-View Images
Han-Hung Lee, Yiming Zhang, Angel X. Chang
We introduce Duoduo CLIP, a model for 3D representation learning that learns shape encodings from multi-view images instead of point-clouds. The choice of multi-view images allows us to leverage 2D priors from off-the-shelf CLIP models to facilitate fine-tuning with 3D data. Our approach not only shows better generalization compared to existing point cloud methods, but also reduces GPU requirements and training time. In addition, we modify the model with cross-view attention to leverage information across multiple frames of the object which further boosts performance. Compared to the current SOTA point cloud method that requires 480 A100 hours to train 1 billion model parameters we only require 57 A5000 hours and 87 million parameters. Multi-view images also provide more flexibility in use cases compared to point clouds. This includes being able to encode objects with a variable number of images, with better performance when more views are used. This is in contrast to point cloud based methods, where an entire scan or model of an object is required. We showcase this flexibility with object retrieval from images of real-world objects. Our model also achieves better performance in more fine-grained text to shape retrieval, demonstrating better text-and-shape alignment than point cloud based models.
Read more6/18/2024
🛸
0
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
Read more6/7/2024