Can CLIP help CLIP in learning 3D?

0

Sign in to get full access
Overview
- This paper explores how the CLIP (Contrastive Language-Image Pre-training) model can be leveraged to aid in learning 3D representations.
- The researchers investigate novel techniques for improving CLIP's performance on 3D tasks, which is an important area of research for applications like augmented reality and robotics.
- The paper presents several approaches, including using CLIP to guide 3D model training, and using CLIP's visual-linguistic understanding to enhance 3D object recognition.
Plain English Explanation
The CLIP model is a powerful AI system that can understand the relationship between images and the language used to describe them. This paper looks at how CLIP's capabilities can be used to help machines learn about 3D objects and environments.
One key idea is using CLIP to provide "guidance" during the training of 3D models. Normally, 3D model training requires lots of labeled 3D data, which can be costly and time-consuming to obtain. By leveraging CLIP's visual-linguistic understanding, the researchers explore ways to train 3D models more efficiently, using less 3D data.
Another approach is using CLIP to enhance 3D object recognition - the ability for AI systems to identify and classify 3D objects. CLIP's knowledge of how objects are described in language could complement the geometric information captured in 3D data, leading to more robust and accurate 3D object recognition.
Overall, this research aims to find ways that the remarkable capabilities of the CLIP model can be harnessed to advance the state-of-the-art in 3D perception and modeling - technologies that are crucial for emerging applications like augmented reality and robotics.
Technical Explanation
The paper first reviews relevant prior work, including efforts to leverage CLIP for few-shot learning and data selection for multimodal models.
The main technical contributions focus on two approaches:
-
CLIP-Guided 3D Model Training: The researchers propose using CLIP's visual-linguistic understanding to guide the training of 3D models. This involves incorporating CLIP-based losses or regularizers into the 3D model objective, encouraging the 3D model to learn representations that align with CLIP's multimodal representations.
-
CLIP-Enhanced 3D Object Recognition: The paper explores ways to leverage CLIP's language knowledge to improve 3D object recognition. This includes using CLIP embeddings as additional inputs to 3D recognition models, or designing novel architectures that tightly integrate CLIP with 3D processing.
Extensive experiments are conducted on 3D classification and retrieval tasks, demonstrating the benefits of these CLIP-based approaches compared to standard 3D-only baselines. The results suggest CLIP can indeed be a valuable tool for advancing 3D perception capabilities.
Critical Analysis
The paper provides a solid technical foundation and promising empirical results for using CLIP to improve 3D learning. However, some potential limitations and open questions are worth considering:
- The experiments are primarily conducted on established 3D benchmarks, but it's unclear how these techniques would scale to real-world 3D applications with greater complexity and diversity.
- The paper does not deeply explore the limitations of CLIP's 3D understanding or address potential misalignments between CLIP's 2D-centric representations and 3D data.
- Further research is needed to understand how to optimally integrate CLIP with 3D models, as well as the tradeoffs between CLIP-guided training and purely 3D-supervised approaches.
Overall, this work represents an important step forward, but continued research is needed to fully unlock CLIP's potential for advancing 3D perception and modeling capabilities. Careful consideration of the technology's limitations and continued evaluation on challenging real-world tasks will be crucial.
Conclusion
This paper explores novel techniques for leveraging the CLIP model to enhance 3D learning and perception. By using CLIP to guide 3D model training or integrate CLIP's visual-linguistic knowledge into 3D object recognition, the researchers demonstrate promising improvements over standard 3D-only approaches.
These findings suggest CLIP could be a valuable tool for advancing 3D technologies that are critical for emerging applications like augmented reality and robotics. While further research is needed, this work represents an important step forward in bridging the gap between 2D visual-linguistic understanding and 3D geometric reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can CLIP help CLIP in learning 3D?
Cristian Sbrolli, Matteo Matteucci
In this study, we explore an alternative approach to enhance contrastive text-image-3D alignment in the absence of textual descriptions for 3D objects. We introduce two unsupervised methods, $I2I$ and $(I2L)^2$, which leverage CLIP knowledge about textual and 2D data to compute the neural perceived similarity between two 3D samples. We employ the proposed methods to mine 3D hard negatives, establishing a multimodal contrastive pipeline with hard negative weighting via a custom loss function. We train on different configurations of the proposed hard negative mining approach, and we evaluate the accuracy of our models in 3D classification and on the cross-modal retrieval benchmark, testing image-to-shape and shape-to-image retrieval. Results demonstrate that our approach, even without explicit text alignment, achieves comparable or superior performance on zero-shot and standard 3D classification, while significantly improving both image-to-shape and shape-to-image retrieval compared to previous methods.
Read more9/10/2024
👁️
0
MV-CLIP: Multi-View CLIP for Zero-shot 3D Shape Recognition
Dan Song, Xinwei Fu, Ning Liu, Weizhi Nie, Wenhui Li, Lanjun Wang, You Yang, Anan Liu
Large-scale pre-trained models have demonstrated impressive performance in vision and language tasks within open-world scenarios. Due to the lack of comparable pre-trained models for 3D shapes, recent methods utilize language-image pre-training to realize zero-shot 3D shape recognition. However, due to the modality gap, pretrained language-image models are not confident enough in the generalization to 3D shape recognition. Consequently, this paper aims to improve the confidence with view selection and hierarchical prompts. Leveraging the CLIP model as an example, we employ view selection on the vision side by identifying views with high prediction confidence from multiple rendered views of a 3D shape. On the textual side, the strategy of hierarchical prompts is proposed for the first time. The first layer prompts several classification candidates with traditional class-level descriptions, while the second layer refines the prediction based on function-level descriptions or further distinctions between the candidates. Remarkably, without the need for additional training, our proposed method achieves impressive zero-shot 3D classification accuracies of 84.44%, 91.51%, and 66.17% on ModelNet40, ModelNet10, and ShapeNet Core55, respectively. Furthermore, we will make the code publicly available to facilitate reproducibility and further research in this area.
Read more9/12/2024

0
Optimizing CLIP Models for Image Retrieval with Maintained Joint-Embedding Alignment
Konstantin Schall, Kai Uwe Barthel, Nico Hezel, Klaus Jung
Contrastive Language and Image Pairing (CLIP), a transformative method in multimedia retrieval, typically trains two neural networks concurrently to generate joint embeddings for text and image pairs. However, when applied directly, these models often struggle to differentiate between visually distinct images that have similar captions, resulting in suboptimal performance for image-based similarity searches. This paper addresses the challenge of optimizing CLIP models for various image-based similarity search scenarios, while maintaining their effectiveness in text-based search tasks such as text-to-image retrieval and zero-shot classification. We propose and evaluate two novel methods aimed at refining the retrieval capabilities of CLIP without compromising the alignment between text and image embeddings. The first method involves a sequential fine-tuning process: initially optimizing the image encoder for more precise image retrieval and subsequently realigning the text encoder to these optimized image embeddings. The second approach integrates pseudo-captions during the retrieval-optimization phase to foster direct alignment within the embedding space. Through comprehensive experiments, we demonstrate that these methods enhance CLIP's performance on various benchmarks, including image retrieval, k-NN classification, and zero-shot text-based classification, while maintaining robustness in text-to-image retrieval. Our optimized models permit maintaining a single embedding per image, significantly simplifying the infrastructure needed for large-scale multi-modal similarity search systems.
Read more9/4/2024
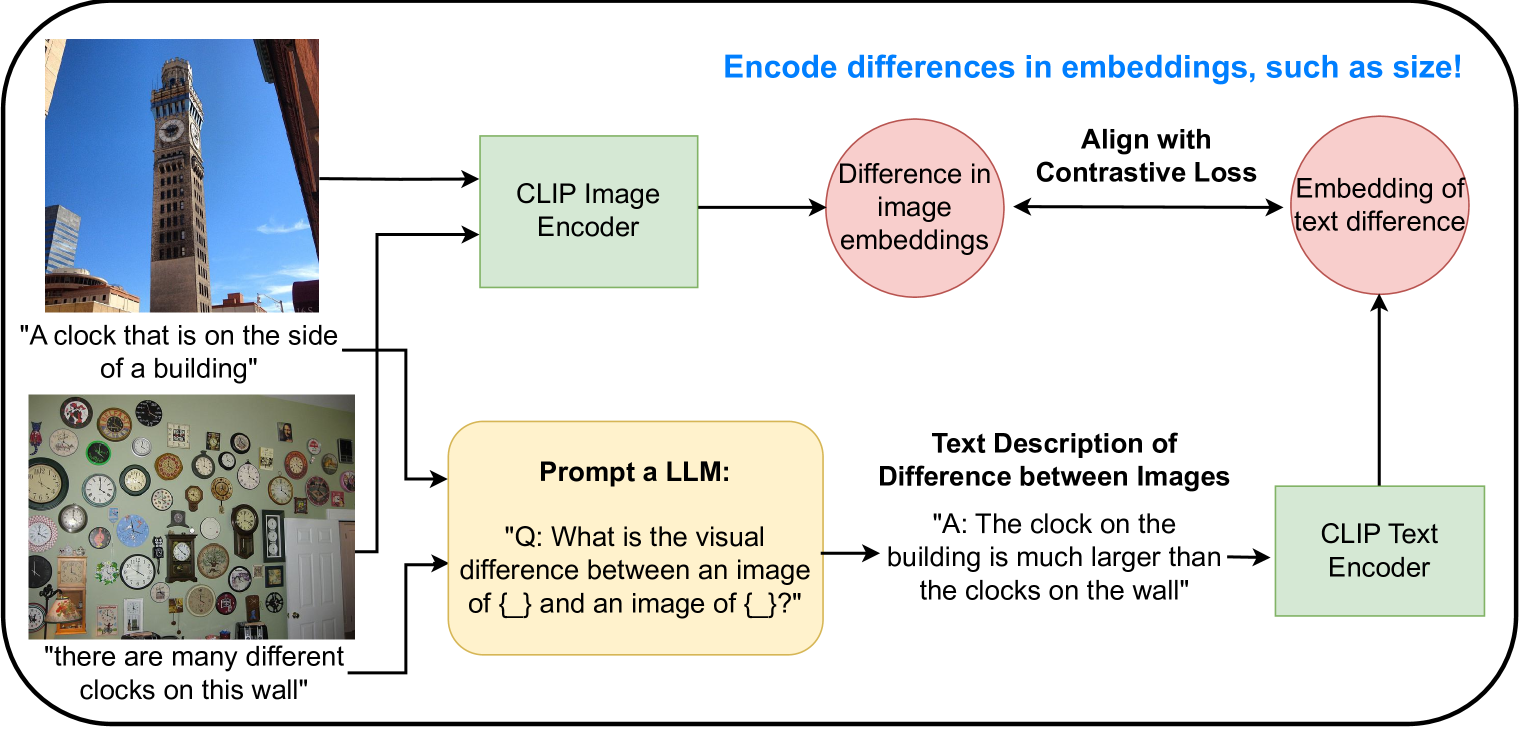
0
New!Finetuning CLIP to Reason about Pairwise Differences
Dylan Sam, Devin Willmott, Joao D. Semedo, J. Zico Kolter
Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
Read more9/17/2024