MVGamba: Unify 3D Content Generation as State Space Sequence Modeling

0

Sign in to get full access
Overview
- This paper proposes a novel approach called MVGamba (Multi-View Gamba) for unifying 3D content generation as a state space sequence modeling problem.
- The key idea is to model the generation of 3D content, such as 3D shapes or 3D scenes, as a sequential process of transitioning between different states in a latent state space.
- The model is designed to be highly flexible and capable of generating a diverse range of 3D content from a wide variety of input modalities, including multi-view images, text, or even 3D shapes.
Plain English Explanation
The paper presents a new way to generate 3D content, such as 3D shapes or 3D scenes, using a technique called MVGamba (Multi-View Gamba). The core idea is to model the process of creating 3D content as a sequence of steps, where each step involves transitioning between different states in a hidden or "latent" space. This latent space can represent the underlying structure and properties of the 3D content being generated.
The key advantage of this approach is that it allows the model to be highly flexible and capable of generating a wide range of 3D content from various input sources, such as multi-view images, text, or even existing 3D shapes. This makes it a powerful tool for tasks like 3D shape generation, 3D scene creation, and 3D content synthesis in general.
Technical Explanation
The MVGamba model works by encoding the input data (e.g., multi-view images, text, or 3D shapes) into a latent state space representation. This latent space is designed to capture the underlying structure and properties of the 3D content being generated. The model then generates new 3D content by sequentially transitioning between different states in this latent space, much like a state space model would.
The authors demonstrate the flexibility of their approach by applying MVGamba to a variety of 3D content generation tasks, including 3D shape generation, 3D scene creation, and 3D reconstruction from multi-view images. The model is able to generate high-quality 3D content across these diverse tasks, showcasing its ability to unify 3D content generation as a state space sequence modeling problem.
Critical Analysis
The paper presents a compelling and ambitious approach to unifying 3D content generation tasks. The core idea of modeling the generation process as a sequence of transitions in a latent state space is intriguing and has the potential to be a powerful and flexible framework.
However, the authors do not address certain limitations or potential issues with their approach. For example, they do not discuss the computational complexity of the model, which could be a concern for real-world applications. Additionally, the paper does not provide a comprehensive analysis of the model's performance compared to other state-of-the-art approaches in specific 3D content generation tasks.
It would also be valuable to see the authors explore the interpretability and explainability of the learned latent state representations. Understanding the underlying structure and properties captured by the model could provide valuable insights into the 3D content generation process.
Conclusion
The MVGamba model presented in this paper offers a promising and unified approach to 3D content generation, leveraging the flexibility of state space sequence modeling. By encoding input data into a latent state space and generating new content through sequential transitions, the model demonstrates the ability to handle a diverse range of 3D generation tasks.
The core ideas behind MVGamba have the potential to advance the field of 3D content synthesis and could find applications in a variety of domains, from computer graphics and virtual reality to robotic perception and planning. As the authors continue to refine and expand their work, addressing the identified limitations and exploring the model's interpretability, MVGamba could emerge as a powerful and versatile tool for 3D content generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MVGamba: Unify 3D Content Generation as State Space Sequence Modeling
Xuanyu Yi, Zike Wu, Qiuhong Shen, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Shuicheng Yan, Xinchao Wang, Hanwang Zhang
Recent 3D large reconstruction models (LRMs) can generate high-quality 3D content in sub-seconds by integrating multi-view diffusion models with scalable multi-view reconstructors. Current works further leverage 3D Gaussian Splatting as 3D representation for improved visual quality and rendering efficiency. However, we observe that existing Gaussian reconstruction models often suffer from multi-view inconsistency and blurred textures. We attribute this to the compromise of multi-view information propagation in favor of adopting powerful yet computationally intensive architectures (e.g., Transformers). To address this issue, we introduce MVGamba, a general and lightweight Gaussian reconstruction model featuring a multi-view Gaussian reconstructor based on the RNN-like State Space Model (SSM). Our Gaussian reconstructor propagates causal context containing multi-view information for cross-view self-refinement while generating a long sequence of Gaussians for fine-detail modeling with linear complexity. With off-the-shelf multi-view diffusion models integrated, MVGamba unifies 3D generation tasks from a single image, sparse images, or text prompts. Extensive experiments demonstrate that MVGamba outperforms state-of-the-art baselines in all 3D content generation scenarios with approximately only $0.1times$ of the model size.
Read more6/21/2024
0
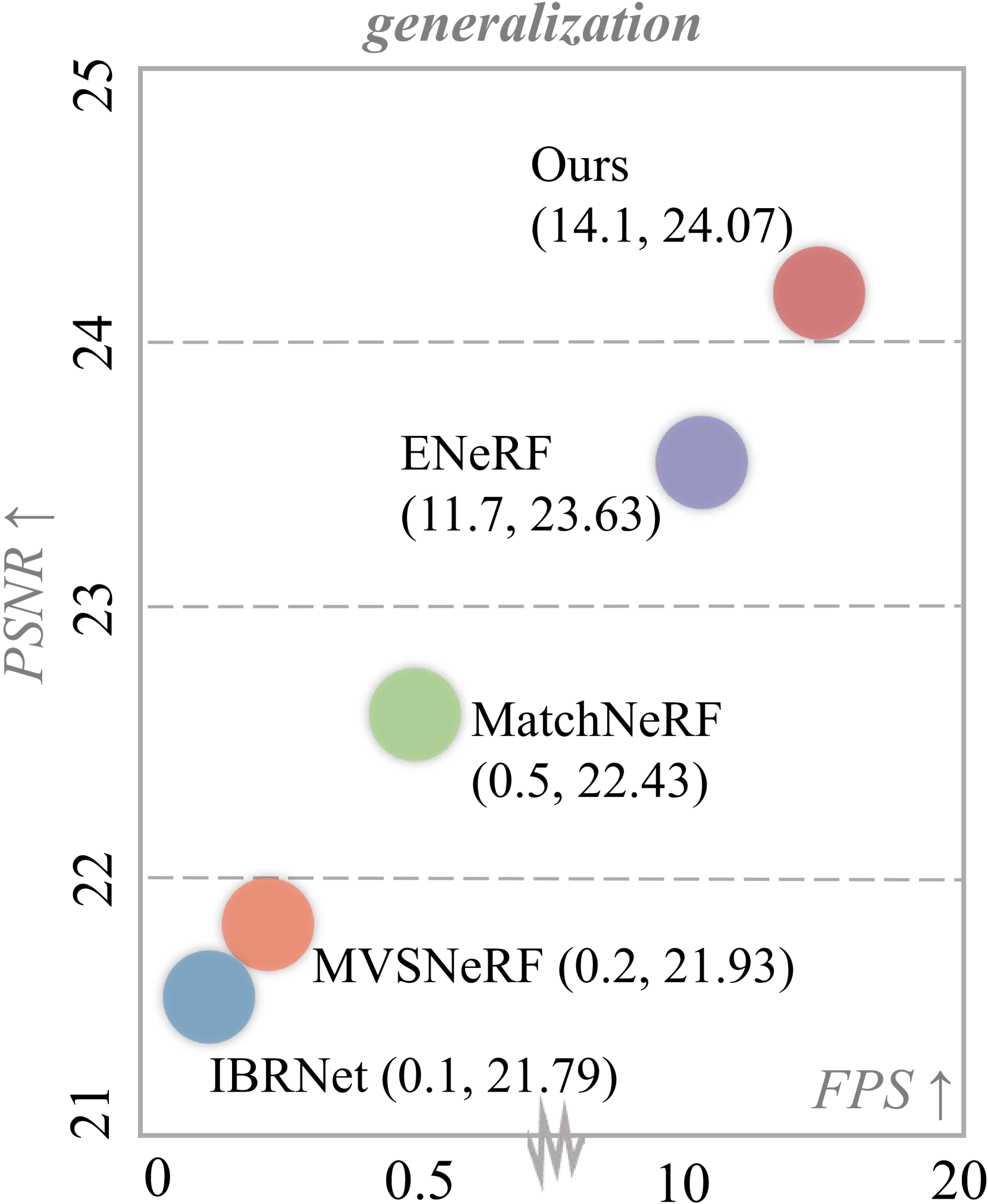
Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei Liu
We present MVSGaussian, a new generalizable 3D Gaussian representation approach derived from Multi-View Stereo (MVS) that can efficiently reconstruct unseen scenes. Specifically, 1) we leverage MVS to encode geometry-aware Gaussian representations and decode them into Gaussian parameters. 2) To further enhance performance, we propose a hybrid Gaussian rendering that integrates an efficient volume rendering design for novel view synthesis. 3) To support fast fine-tuning for specific scenes, we introduce a multi-view geometric consistent aggregation strategy to effectively aggregate the point clouds generated by the generalizable model, serving as the initialization for per-scene optimization. Compared with previous generalizable NeRF-based methods, which typically require minutes of fine-tuning and seconds of rendering per image, MVSGaussian achieves real-time rendering with better synthesis quality for each scene. Compared with the vanilla 3D-GS, MVSGaussian achieves better view synthesis with less training computational cost. Extensive experiments on DTU, Real Forward-facing, NeRF Synthetic, and Tanks and Temples datasets validate that MVSGaussian attains state-of-the-art performance with convincing generalizability, real-time rendering speed, and fast per-scene optimization.
Read more7/16/2024
0
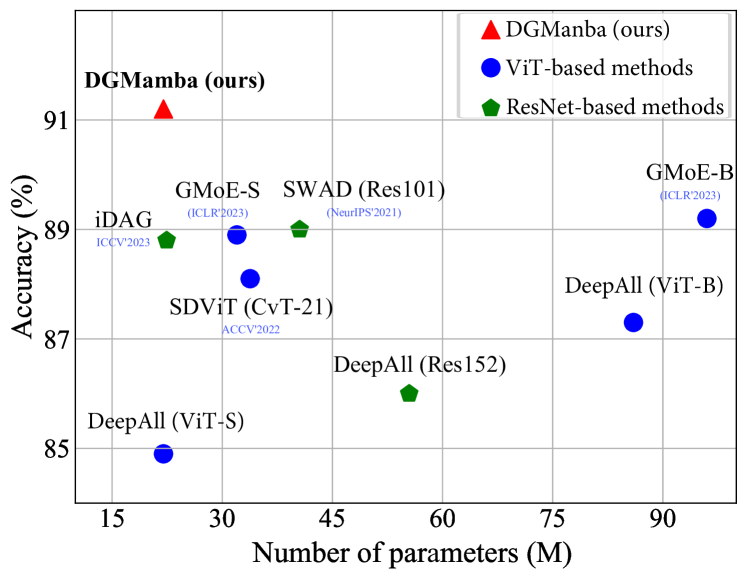
DGMamba: Domain Generalization via Generalized State Space Model
Shaocong Long, Qianyu Zhou, Xiangtai Li, Xuequan Lu, Chenhao Ying, Yuan Luo, Lizhuang Ma, Shuicheng Yan
Domain generalization~(DG) aims at solving distribution shift problems in various scenes. Existing approaches are based on Convolution Neural Networks (CNNs) or Vision Transformers (ViTs), which suffer from limited receptive fields or quadratic complexities issues. Mamba, as an emerging state space model (SSM), possesses superior linear complexity and global receptive fields. Despite this, it can hardly be applied to DG to address distribution shifts, due to the hidden state issues and inappropriate scan mechanisms. In this paper, we propose a novel framework for DG, named DGMamba, that excels in strong generalizability toward unseen domains and meanwhile has the advantages of global receptive fields, and efficient linear complexity. Our DGMamba compromises two core components: Hidden State Suppressing~(HSS) and Semantic-aware Patch refining~(SPR). In particular, HSS is introduced to mitigate the influence of hidden states associated with domain-specific features during output prediction. SPR strives to encourage the model to concentrate more on objects rather than context, consisting of two designs: Prior-Free Scanning~(PFS), and Domain Context Interchange~(DCI). Concretely, PFS aims to shuffle the non-semantic patches within images, creating more flexible and effective sequences from images, and DCI is designed to regularize Mamba with the combination of mismatched non-semantic and semantic information by fusing patches among domains. Extensive experiments on five commonly used DG benchmarks demonstrate that the proposed DGMamba achieves remarkably superior results to state-of-the-art models. The code will be made publicly available at https://github.com/longshaocong/DGMamba.
Read more8/23/2024

0
L4GM: Large 4D Gaussian Reconstruction Model
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xiaohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, Huan Ling
We present L4GM, the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second. Key to our success is a novel dataset of multiview videos containing curated, rendered animated objects from Objaverse. This dataset depicts 44K diverse objects with 110K animations rendered in 48 viewpoints, resulting in 12M videos with a total of 300M frames. We keep our L4GM simple for scalability and build directly on top of LGM, a pretrained 3D Large Reconstruction Model that outputs 3D Gaussian ellipsoids from multiview image input. L4GM outputs a per-frame 3D Gaussian Splatting representation from video frames sampled at a low fps and then upsamples the representation to a higher fps to achieve temporal smoothness. We add temporal self-attention layers to the base LGM to help it learn consistency across time, and utilize a per-timestep multiview rendering loss to train the model. The representation is upsampled to a higher framerate by training an interpolation model which produces intermediate 3D Gaussian representations. We showcase that L4GM that is only trained on synthetic data generalizes extremely well on in-the-wild videos, producing high quality animated 3D assets.
Read more6/18/2024