My3DGen: A Scalable Personalized 3D Generative Model
2307.05468
0
0
Abstract
In recent years, generative 3D face models (e.g., EG3D) have been developed to tackle the problem of synthesizing photo-realistic faces. However, these models are often unable to capture facial features unique to each individual, highlighting the importance of personalization. Some prior works have shown promise in personalizing generative face models, but these studies primarily focus on 2D settings. Also, these methods require both fine-tuning and storing a large number of parameters for each user, posing a hindrance to achieving scalable personalization. Another challenge of personalization is the limited number of training images available for each individual, which often leads to overfitting when using full fine-tuning methods. Our proposed approach, My3DGen, generates a personalized 3D prior of an individual using as few as 50 training images. My3DGen allows for novel view synthesis, semantic editing of a given face (e.g. adding a smile), and synthesizing novel appearances, all while preserving the original person's identity. We decouple the 3D facial features into global features and personalized features by freezing the pre-trained EG3D and training additional personalized weights through low-rank decomposition. As a result, My3DGen introduces only $textbf{240K}$ personalized parameters per individual, leading to a $textbf{127}times$ reduction in trainable parameters compared to the $textbf{30.6M}$ required for fine-tuning the entire parameter space. Despite this significant reduction in storage, our model preserves identity features without compromising the quality of downstream applications.
Create account to get full access
Overview
- The paper presents a novel approach for generating high-quality 3D portraits from text descriptions, leveraging a text-guided 3D portrait generation model.
- It explores techniques for reconstructing 3D human models from synthetic and in-the-wild data, as well as methods for simultaneously controlling identity and expression in personalized 3D avatars.
- The research also introduces a framework called TALK3D for synthesizing high-fidelity talking portrait animations from text.
- The techniques developed in this work have potential applications in areas such as personalized 3D avatar generation, virtual collaboration, and digital entertainment.
Plain English Explanation
The researchers have developed a way to create detailed 3D models of people's faces and bodies just by describing them in text. This could be useful for things like virtual meetings, video games, and other digital experiences where you want realistic human-like characters.
The key innovation is a machine learning model that can take a text description of a person's appearance, like "a young woman with long curly brown hair and green eyes," and generate a 3D model that matches that description. This allows creators to easily build custom 3D characters without needing specialized 3D modeling skills.
The model was trained on a large dataset of 3D human scans, as well as synthetic data that was generated to cover a wide range of appearances. This allowed the model to learn how to translate text descriptions into realistic 3D forms.
In addition to static 3D models, the researchers also developed a system called TALK3D that can generate talking portrait animations from text. This could be used to create virtual assistants or digital avatars that can have natural conversations.
Overall, these techniques have the potential to make it much easier to create personalized 3D content for a variety of applications, from gaming to remote collaboration. By bridging the gap between text and 3D, the researchers aim to democratize the creation of lifelike digital humans.
Technical Explanation
The paper presents a text-guided 3D portrait generation framework that can create high-quality 3D portraits from natural language descriptions. The key components include:
-
Text-to-3D Generation Model: The researchers developed a machine learning model that can translate text descriptions of human appearances into corresponding 3D mesh models. This model was trained on a large dataset of 3D human scans as well as synthetic data generated to cover a diverse range of facial features and body types.
-
3D Human Reconstruction: The paper also explores techniques for reconstructing 3D human models from both synthetic and in-the-wild data sources. This includes methods for accurately capturing the detailed geometry and texture of human subjects.
-
Identity and Expression Control: The researchers introduce approaches for simultaneously controlling the identity and expression of personalized 3D avatars. This allows for fine-grained manipulation of the avatar's appearance and emotions.
-
TALK3D Framework: The work introduces TALK3D, a framework for synthesizing high-fidelity talking portrait animations from text input. This enables the creation of virtual assistants and digital avatars that can engage in natural language conversations.
The experiments demonstrate the effectiveness of the proposed techniques in generating realistic 3D portraits that match natural language descriptions. The models are able to capture intricate facial features, body shapes, and even dynamic expressions with a high degree of realism.
Critical Analysis
The paper presents a compelling approach for bridging the gap between text and 3D content creation. The ability to easily generate personalized 3D models and animations from natural language descriptions has significant potential for democratizing 3D content creation.
However, the paper does acknowledge some limitations of the current techniques. For example, the model may struggle with generating highly detailed or unconventional human appearances that are not well-represented in the training data. Additionally, the quality of the generated 3D models and animations, while impressive, may not yet be at the level required for professional-grade applications.
Further research could explore ways to improve the model's generalization capabilities, as well as techniques for integrating the 3D generation with other aspects of digital content creation, such as animation, rigging, and rendering. Investigating the ethical implications of these technologies, particularly around the creation of synthetic media, would also be an important area for future work.
Overall, the research presented in this paper represents an exciting step forward in the field of text-to-3D generation, with the potential to significantly impact how we create and interact with virtual environments and digital characters.
Conclusion
This paper introduces a novel approach for generating high-quality 3D portraits from text descriptions, leveraging techniques in 3D human reconstruction, identity and expression control, and talking portrait synthesis. The proposed methods demonstrate the ability to translate natural language into realistic 3D content, with potential applications in virtual collaboration, digital entertainment, and personalized avatar generation.
While the current techniques have some limitations, the research represents an important advancement in bridging the gap between text and 3D, with the promise of democratizing the creation of lifelike digital humans. As the field continues to evolve, further research exploring the ethical implications and practical applications of these technologies will be crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
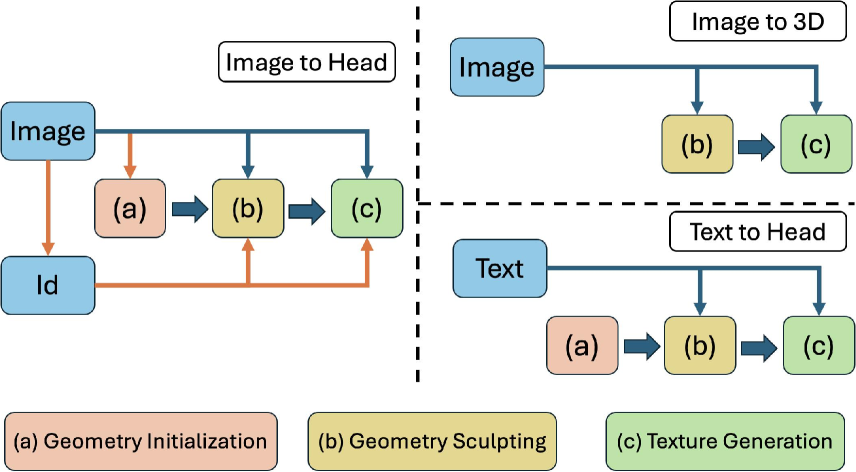
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma
0
0
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
6/26/2024

$E^{3}$Gen: Efficient, Expressive and Editable Avatars Generation
Weitian Zhang, Yichao Yan, Yunhui Liu, Xingdong Sheng, Xiaokang Yang
0
0
This paper aims to introduce 3D Gaussian for efficient, expressive, and editable digital avatar generation. This task faces two major challenges: (1) The unstructured nature of 3D Gaussian makes it incompatible with current generation pipelines; (2) the expressive animation of 3D Gaussian in a generative setting that involves training with multiple subjects remains unexplored. In this paper, we propose a novel avatar generation method named $E^3$Gen, to effectively address these challenges. First, we propose a novel generative UV features plane representation that encodes unstructured 3D Gaussian onto a structured 2D UV space defined by the SMPL-X parametric model. This novel representation not only preserves the representation ability of the original 3D Gaussian but also introduces a shared structure among subjects to enable generative learning of the diffusion model. To tackle the second challenge, we propose a part-aware deformation module to achieve robust and accurate full-body expressive pose control. Extensive experiments demonstrate that our method achieves superior performance in avatar generation and enables expressive full-body pose control and editing. Our project page is https://olivia23333.github.io/E3Gen.
5/31/2024

Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior
Yiqian Wu, Hao Xu, Xiangjun Tang, Xien Chen, Siyu Tang, Zhebin Zhang, Chen Li, Xiaogang Jin
0
0
Existing neural rendering-based text-to-3D-portrait generation methods typically make use of human geometry prior and diffusion models to obtain guidance. However, relying solely on geometry information introduces issues such as the Janus problem, over-saturation, and over-smoothing. We present Portrait3D, a novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve text-to-3D-portrait generation that overcomes the aforementioned issues. To accomplish this, we train a 3D portrait generator, 3DPortraitGAN-Pyramid, as a robust prior. This generator is capable of producing 360{deg} canonical 3D portraits, serving as a starting point for the subsequent diffusion-based generation process. To mitigate the grid-like artifact caused by the high-frequency information in the feature-map-based 3D representation commonly used by most 3D-aware GANs, we integrate a novel pyramid tri-grid 3D representation into 3DPortraitGAN-Pyramid. To generate 3D portraits from text, we first project a randomly generated image aligned with the given prompt into the pre-trained 3DPortraitGAN-Pyramid's latent space. The resulting latent code is then used to synthesize a pyramid tri-grid. Beginning with the obtained pyramid tri-grid, we use score distillation sampling to distill the diffusion model's knowledge into the pyramid tri-grid. Following that, we utilize the diffusion model to refine the rendered images of the 3D portrait and then use these refined images as training data to further optimize the pyramid tri-grid, effectively eliminating issues with unrealistic color and unnatural artifacts. Our experimental results show that Portrait3D can produce realistic, high-quality, and canonical 3D portraits that align with the prompt.
4/17/2024

SynthForge: Synthesizing High-Quality Face Dataset with Controllable 3D Generative Models
Abhay Rawat, Shubham Dokania, Astitva Srivastava, Shuaib Ahmed, Haiwen Feng, Rahul Tallamraju
0
0
Recent advancements in generative models have unlocked the capabilities to render photo-realistic data in a controllable fashion. Trained on the real data, these generative models are capable of producing realistic samples with minimal to no domain gap, as compared to the traditional graphics rendering. However, using the data generated using such models for training downstream tasks remains under-explored, mainly due to the lack of 3D consistent annotations. Moreover, controllable generative models are learned from massive data and their latent space is often too vast to obtain meaningful sample distributions for downstream task with limited generation. To overcome these challenges, we extract 3D consistent annotations from an existing controllable generative model, making the data useful for downstream tasks. Our experiments show competitive performance against state-of-the-art models using only generated synthetic data, demonstrating potential for solving downstream tasks. Project page: https://synth-forge.github.io
6/13/2024